sedefkahvecioglu/turkish-sentiment-dataset
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/sedefkahvecioglu/turkish-sentiment-dataset
下载链接
链接失效反馈官方服务:
资源简介:
# Turkish Sentiment Analysis Dataset
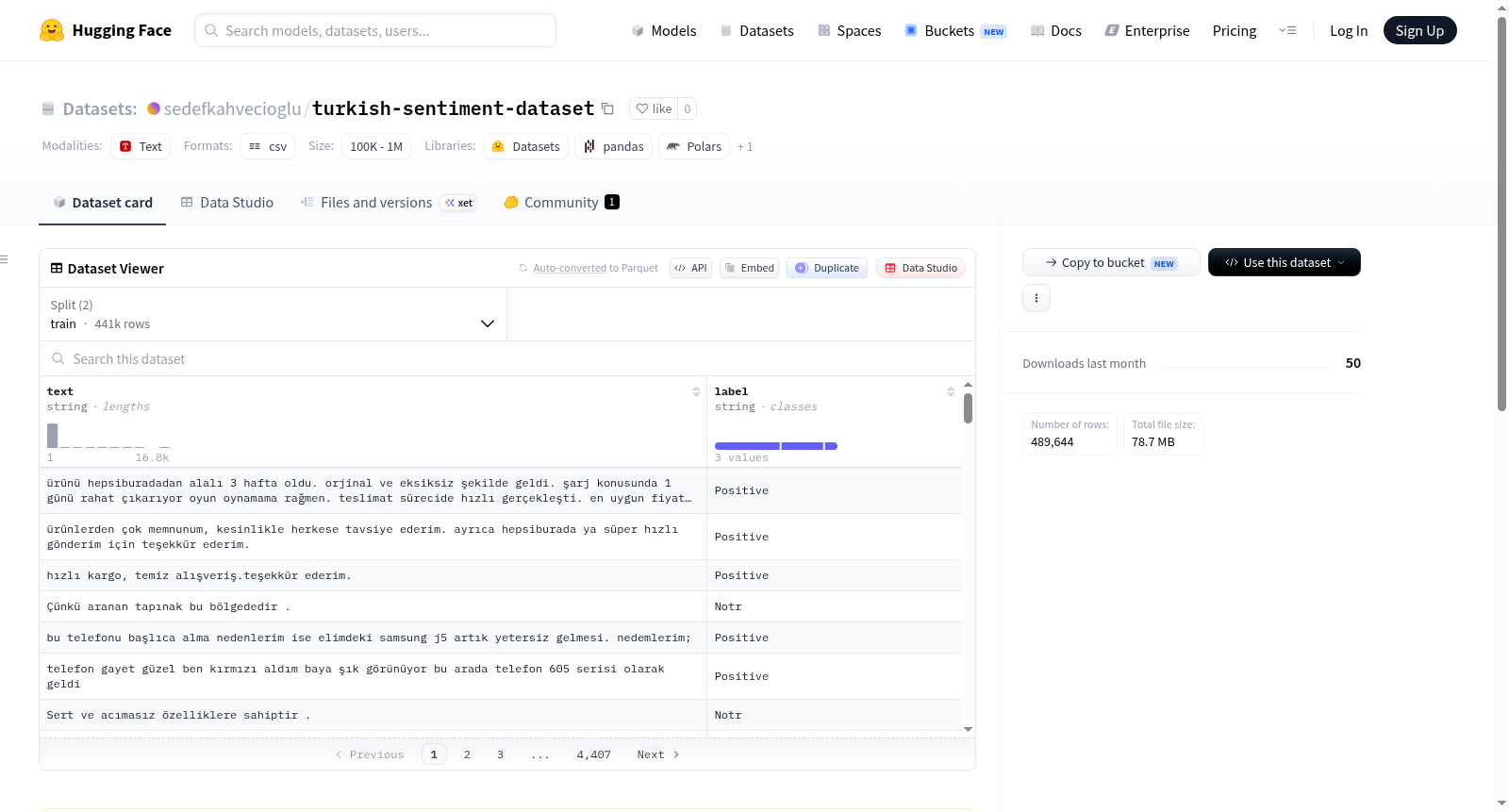
This dataset is designed for sentiment analysis tasks in Turkish. It consists of separate training and test splits.
## Dataset Structure
### Train Split
The training dataset includes labeled text data.
- **text**: Turkish sentence or tweet
- **label**: sentiment label (positive, negative, neutral)
### Test Split
The test dataset includes unlabeled text data.
- **text**: Turkish sentence or tweet
## Purpose
This dataset can be used to train and evaluate machine learning models for sentiment analysis in Turkish.
This dataset is designed for sentiment analysis tasks in Turkish. It consists of separate training and test splits. The training dataset includes labeled text data with text (Turkish sentence or tweet) and label (sentiment label: positive, negative, neutral). The test dataset includes unlabeled text data with only text (Turkish sentence or tweet). This dataset can be used to train and evaluate machine learning models for sentiment analysis in Turkish.
提供机构:
sedefkahvecioglu
搜集汇总
数据集介绍
构建方式
该数据集专为土耳其语情感分析任务而构建,由训练集和测试集两部分组成。训练集包含标注的文本数据,每条记录由土耳其语句子或推文及其对应的情感标签(正面、负面、中立)构成。测试集则仅包含未标注的文本数据,用于模型评估。通过这种划分,研究者能够基于标注样本训练模型,并在无标签数据上检验其泛化能力。
特点
数据集聚焦于土耳其语这一较稀缺的自然语言处理资源,弥补了该语种在情感分析领域公开数据集的不足。其情感标签采用三分类体系,覆盖正面、负面及中立情绪,能够适应多类别情感判别需求。同时,数据来源涵盖日常语句与社交媒体推文,增强了语言多样性与领域适用性。
使用方法
用户可将数据集加载至机器学习框架中,利用训练集的文本与标签对模型进行监督学习。测试集则用于评估模型在未见数据上的表现,通过预测情感标签并与标注结果对比计算准确率等指标。此外,研究者可进一步微调预训练语言模型或经典分类器,以适配土耳其语的语法与语义特性。
背景与挑战
背景概述
情感分析作为自然语言处理领域的核心任务之一,旨在自动识别文本中蕴含的情感倾向。然而,现有研究多集中于英语等资源丰富的语言,对于形态复杂且资源稀缺的语言如土耳其语,相关数据集和预训练模型仍显不足。turkish-sentiment-dataset正是在此背景下,由研究团队于近期创建,旨在填补土耳其语情感分析语料库的空白。该数据集包含经过标注的训练集和未标注的测试集,文本来源于土耳其语句子或推文,标签涵盖积极、消极与中立三类情感。这一数据资源为探索土耳其语情感表达的语义特征提供了重要基础,也为跨语言情感分析模型的评估提供了标准化基准。该数据集的发布有望推动土耳其语自然语言处理技术的发展,特别是在社交媒体舆情监控、用户反馈分析等实际应用中发挥关键作用。
当前挑战
在领域问题层面,土耳其语作为黏着语,其复杂的词形变化和丰富的派生结构使得情感特征的提取相较于英语更加困难;同时,社交媒体文本中包含大量非规范拼写、表情符号及网络用语,进一步加剧了情感分类的歧义性。在数据集构建过程中,标注数据规模有限且类别分布不均,尤其是中性样本的界定模糊,导致模型在不同情感类别间的判别能力失衡。此外,测试集标注信息的缺失限制了监督学习框架下的模型评估精度,标注者间的主观差异性也可能引入噪声标注,从而影响下游任务性能的稳定提升。
常用场景
经典使用场景
在自然语言处理领域,情感分析作为一项基础且关键的任务,致力于从文本中挖掘出主观倾向。turkish-sentiment-dataset专为土耳其语情感分析而设计,其结构化地划分了训练集与测试集,训练集提供标注为正、负、中性的文本,测试集用于模型评测。经典使用场景涵盖基于深度学习的文本分类模型(如BERTurk、LSTM)的训练与验证,以及传统机器学习方法(如支持向量机、朴素贝叶斯)的特征工程与对比实验,为土耳其语情感分析任务提供了标准化的数据支撑。
衍生相关工作
基于turkish-sentiment-dataset,研究人员衍生了多项经典工作,例如针对土耳其语情感分析的数据增强方法(如回译、同义词替换),以及融合情感词典与深度学习的混合模型。此外,该数据集被用于评估跨语言情感分析模型的泛化能力,并催生了面向土耳其语的情感知识图谱构建研究。这些工作进一步拓展了土耳其语情感分析的边界,为低资源语言的情感计算提供了可复现的基准与创新思路。
数据集最近研究
最新研究方向
针对土耳其语情感分析数据集的构建与应用研究,当前前沿方向聚焦于低资源语言的情感计算模型优化,特别是结合预训练语言模型(如BERTurk、XLM-R)进行微调,以提升对土耳其语社交媒体文本中复杂情感(如讽刺、混合情感)的识别精度。该数据集在跨语言情感分析的基准测试中扮演关键角色,与近期土耳其语自然语言处理领域的进展紧密相连,如土耳其语情感词典的扩充和方言适应性研究。其意义在于推动非英语语言的AI公平性,减少语言偏见,并为土耳其语互联网内容监控、舆情分析等应用提供可靠基础,助力多语种情感解析技术的民主化进程。
以上内容由遇见数据集搜集并总结生成


