ChristianZ97/NuminaMath-LEAN-satp-buffer
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ChristianZ97/NuminaMath-LEAN-satp-buffer
下载链接
链接失效反馈官方服务:
资源简介:
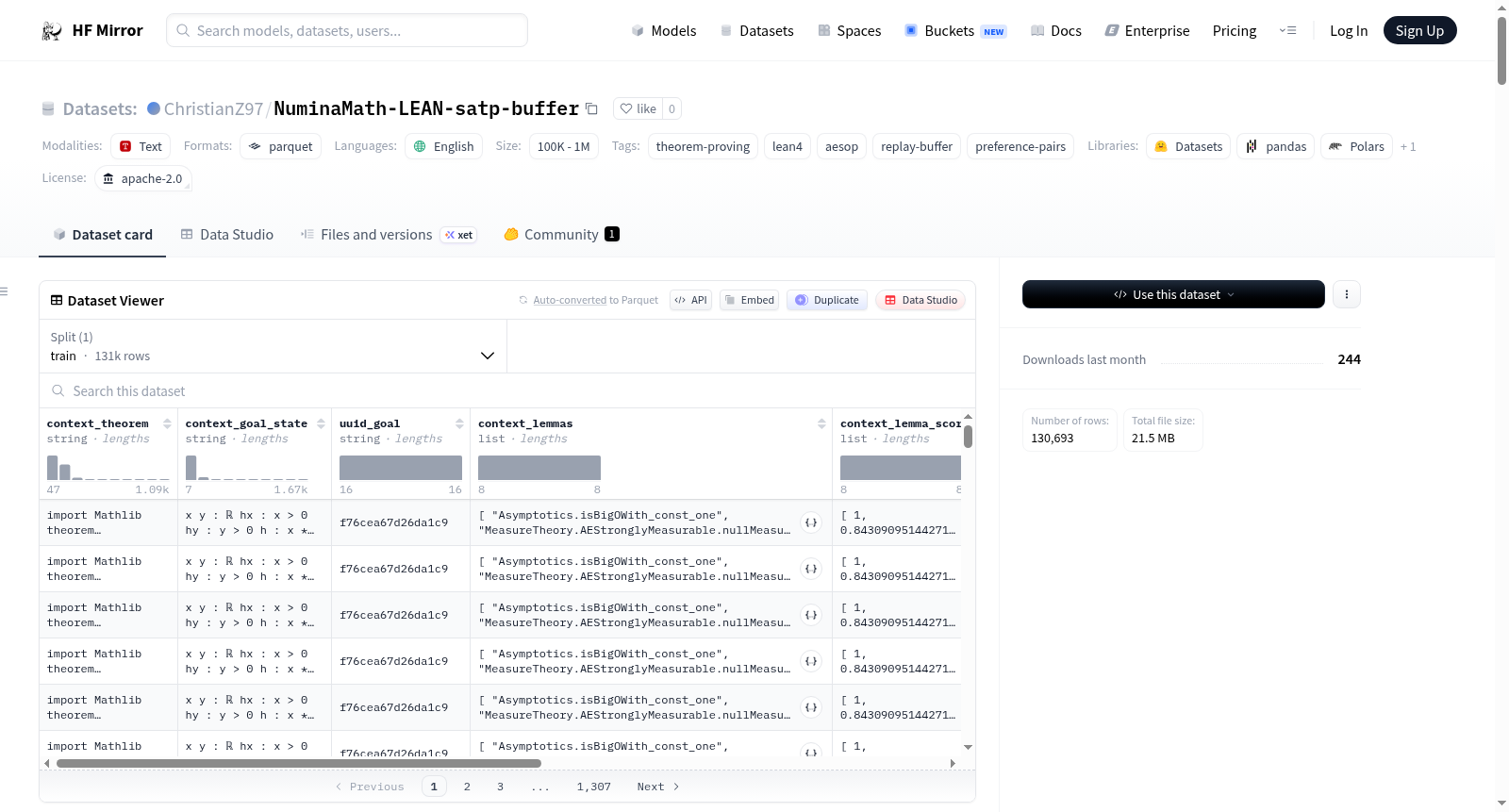
NuminaMath-LEAN-satp-buffer数据集是一个用于记录Lean 4定理证明过程中aesop配置与目标状态配对及其结果的回放缓冲区。每条记录代表一个aesop调用(包括配置块和规则添加)针对一个目标的测试结果,以及二进制输出。数据集包含多个字段,如uuid(目标状态标识)、config_uuid(配置标识)、formal_statement(Lean 4定理源码)、goal_state(Lean 4目标状态)、tactic_string(aesop配置字符串)、reward(证明结果,1.0表示成功,-1.0表示失败)等。数据集还提供了详细的统计数据、合并信息和架构描述,适用于文本生成和强化学习任务。
NuminaMath-LEAN-satp-buffer is a replay buffer of `(goal_state, aesop config)` -> `reward` pairs collected during training and augmentation of an aesop-config policy on Lean 4 theorems from NuminaMath. Each row records one Lean 4 `aesop` invocation (config block plus rule additions) tested against one goal, plus the binary outcome. The dataset includes fields such as uuid, config_uuid, formal_statement, goal_state, tactic_string, reward, etc., with detailed definitions and usage. It also provides statistics, merge information, schema descriptions, and usage examples, making it suitable for text generation and reinforcement learning tasks.
提供机构:
ChristianZ97
搜集汇总
数据集介绍
构建方式
NuminaMath-LEAN-satp-buffer 是为 SATP(单GPU Aesop强化学习)项目构建的经验回放缓冲区数据集。其构建方式基于训练过程中的在线采样:在每次Aesop策略探索时,系统记录下当前Lean定理证明上下文(包括定理陈述、目标状态、前提检索结果)以及策略输出的成功与失败动作对。通过锚点扰动和Thompson采样两种路径,算法生成偏好对,并利用diff_head字段标记成功与失败动作在40维动作向量中唯一差异的索引,从而构建出包含纯成功样本、单差分偏好对和多差分负样本的结构化缓冲区。
特点
该数据集的核心特点在于其精细的偏好对标注机制。每一行记录包含完整的定理上下文(context_theorem、context_goal_state)、前提检索快照(context_lemmas及其得分)以及策略输出的规范化Aesop动作字符串。特别地,diff_head字段精确定位成功与失败动作在40维动作空间(涵盖安全策略、非安全策略、引理规则、配置参数等)中的唯一差异位置,使得数据集能够支持行为克隆、直接偏好优化(DPO)以及负向行为克隆等多种训练信号。总计约95,000条记录中,包含71,815个纯成功样本和3,856个单差分偏好对。
使用方法
数据集的加载通过SATP项目提供的HistoryBuffer类完成。用户可分别以正样本和负样本模式加载缓冲区,并进一步从中派生出专门的DPO训练缓冲区。所有数据条目由uuid_goal字段(基于规范化目标状态的SHA256哈希截断)唯一标识,便于与配套数据集(如训练集、验证集、增强数据集)进行跨数据源对齐。加载后的缓冲区可直接用于强化学习策略的离线训练,支持多种损失函数的计算与优化。
背景与挑战
背景概述
NuminaMath-LEAN-satp-buffer数据集诞生于2026年,由研究机构NuminaMath主导开发,旨在推动定理自动证明领域中强化学习与形式化验证的深度融合。该数据集聚焦于Lean4证明助手环境下的Aesop自动化策略调优问题,通过记录单GPU训练过程中每次交互的经验快照,系统收集了包括成功与失败策略、检索前提权重以及配置参数在内的多模态信息。其核心研究问题在于如何利用偏好数据直接优化Aesop策略的搜索行为,从而克服传统监督学习在复杂数学证明中泛化能力不足的局限。作为SATP项目的关键数据枢纽,该数据集与配套的模型、训练集及扩展数据集共同构成了完整的闭环训练体系,为后续基于直接偏好优化(DPO)的证明策略研究奠定了坚实基础。
当前挑战
该数据集所面临的挑战主要体现在两个层面。在领域问题层面,定理自动证明长期受困于策略搜索空间巨大与奖励信号稀疏之间的矛盾,Aesop等自动化工具虽能通过预定义战术组合简化问题,但其超参数依赖人工调校且缺乏自适应能力,导致在复杂定理上的证明成功率难以突破。在数据集构建层面,首要挑战在于如何精确对齐策略差异:由于Aesop的动作向量包含40个分量,且每条经验记录仅保留策略字符串,重构完整动作元组时需通过解析器将字符串映射回整数向量,这一过程极易因解析逻辑与布局定义不一致而产生隐式错位。此外,多分量差异(multi-diff)场景下无法通过单一头索引回溯成功与失败策略间的精确差异,迫使团队设计专门的扰动采样机制与偏好对生成策略。最终,数据集中仅包含约4%的单差分偏好对,近两万条负样本因缺乏配对成功策略而只能用于训练负对数似然,严重制约了DPO方法的效用上限。
常用场景
经典使用场景
NuminaMath-LEAN-satp-buffer数据集是面向AI辅助定理证明任务的强化学习回放缓冲区,专门服务于基于Aesop策略搜索的SATP(单GPU Aesop强化学习)项目。其经典使用场景在于为训练智能体提供经过标注的定理证明经验快照,每条数据均包含上下文定理、目标状态、成功及失败的动作臂、以及二者间的差异头部索引。该设计使得研究者能够从目标-动作对中提取行为克隆信号、偏好对信号以及负例信号,进而驱动智能体在Lean4形式化语言的定理空间中不断优化策略网络,提升证明搜索效率。
衍生相关工作
围绕NuminaMath-LEAN-satp-buffer,衍生出了一系列具有影响力的相关工作。其同源训练集NuminaMath-LEAN-satp提供了完整的训练目标-动作映射,而miniF2F-satp则构建了标准化验证与测试基准。研究者基于该数据集提出了多头策略网络与局部偏好对齐的方法,进一步推动了基于预训练语言模型的定理证明器在数学竞赛题目中的性能提升。此外,数据集中引入的diff_head索引机制启发了后续工作对策略空间中进行结构化差异分析的技术路线,成为符号强化学习领域中的重要参考范例。
数据集最近研究
最新研究方向
该数据集聚焦于基于单GPU的Aesop强化学习项目SATP,通过重放缓冲区存储定理证明过程中的经验快照,为核心研究提供了包含成功与失败策略对的偏好数据集。当前前沿方向集中于利用直接偏好优化(DPO)技术,从1-diff偏好对中学习策略选择,以提升定理证明器的自动化水平。数据集设计精巧,通过40维动作向量和统一目标状态哈希标识,支持跨数据集的高效编码与检索,为强化学习在数学定理证明领域的应用开辟了新路径。其意义在于,通过捕捉Aesop策略执行中的细粒度决策差异,推动了面向复杂数学形式化证明的智能推理系统发展,有望显著提升Lean等证明助手的自动化证明能力。
以上内容由遇见数据集搜集并总结生成


