ConECT
收藏arXiv2025-06-05 更新2025-06-07 收录
下载链接:
https://huggingface.co/datasets/allegro/ConECT
下载链接
链接失效反馈官方服务:
资源简介:
ConECT数据集(上下文电子商务翻译)旨在支持电子商务领域上下文感知机器翻译的研究。该数据集由从allegro.pl电子商务平台提取的11,000个波兰语句子组成,这些句子被专业翻译人员手动翻译成捷克语,并与主产品图像和类别路径进行对齐。数据集包含各种内容类型,如产品名称、产品描述和报价标题,以提供全面的电子商务翻译语境覆盖。该数据集已公开提供,以促进上下文感知翻译任务的研究。
The ConECT (Contextual E-Commerce Translation) dataset is designed to support research on context-aware machine translation in the e-commerce domain. It consists of 11,000 Polish sentences extracted from the allegro.pl e-commerce platform, which have been manually translated into Czech by professional translators and aligned with the corresponding main product images and category paths. The dataset covers diverse content types including product names, product descriptions, and offer titles, to provide comprehensive contextual coverage for e-commerce translation tasks. The dataset is publicly available to facilitate research on context-aware translation tasks.
提供机构:
Machine Learning Research Allegro.com, Laniqo.com, NASK
创建时间:
2025-06-05
原始信息汇总
ConECT 数据集概述
数据集基本信息
- 名称: ConECT (Contextualized Ecommerce Translation)
- 类型: 电子商务翻译数据集
- 语言: 捷克语 (cs) <-> 波兰语 (pl)
- 数据量: 11,400 句对
- 许可证: CC-BY-NC-4.0
- 论文: ConECT Dataset: Overcoming Data Scarcity in Context-Aware E-Commerce MT
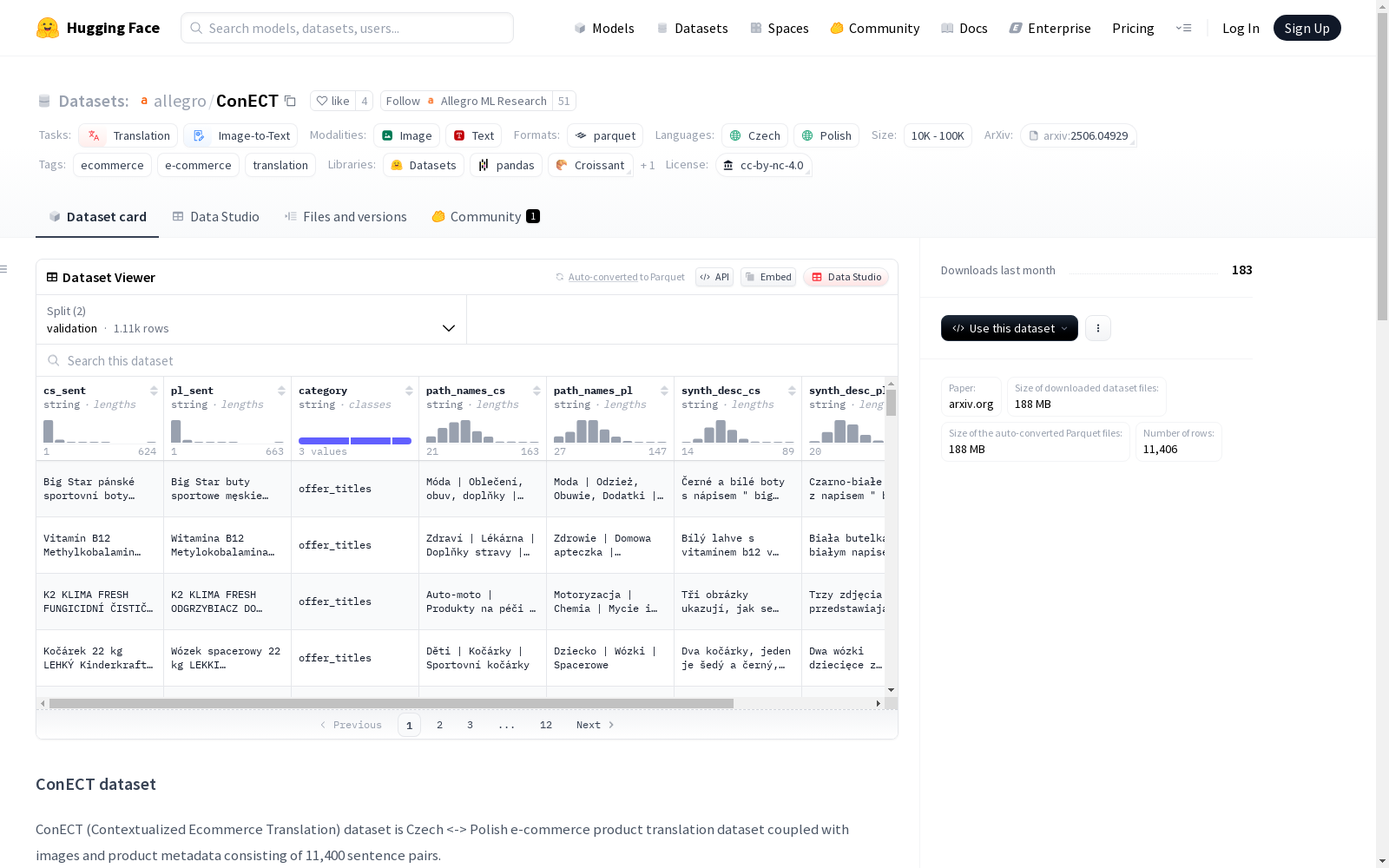
数据集结构
特征
cs_sent: 捷克语句子pl_sent: 波兰语句子category: 类别path_names_cs: 捷克语路径名称path_names_pl: 波兰语路径名称synth_desc_cs: 捷克语合成描述synth_desc_pl: 波兰语合成描述image: 图像
数据划分
- 验证集 (validation)
- 样本数: 1,111
- 大小: 19,985,436.349 字节
- 测试集 (test)
- 样本数: 10,295
- 大小: 180,929,942.845 字节
数据类别
- 产品名称: 识别产品的短短语,通常包含品牌名称和技术规格。
- 产品描述: 详细描述产品特性、规格和使用说明的较长文本。
- 优惠标题: 简洁且吸引人的营销短语,包括促销内容和折扣。
使用方式
python from datasets import load_dataset dataset = load_dataset("allegro/ConECT") print(dataset)
引用
bibtex @misc{pokrywka2025conectdatasetovercomingdata, title={ConECT Dataset: Overcoming Data Scarcity in Context-Aware E-Commerce MT}, author={Mikołaj Pokrywka and Wojciech Kusa and Mieszko Rutkowski and Mikołaj Koszowski}, year={2025}, eprint={2506.04929}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2506.04929}, }
作者信息
- 主要贡献者:
- Mikołaj Pokrywka, Laniqo.com, MLR @ Allegro
- Wojciech Kusa, MLR @ Allegro, NASK
- 其他作者:
- Mieszko Rutkowski, MLR @ Allegro
- Mikołaj Koszowski, MLR @ Allegro
搜集汇总
数据集介绍
构建方式
ConECT数据集的构建过程体现了多模态数据融合的前沿理念。研究团队从allegro.pl电商平台提取了11,000条波兰语句子作为源数据,通过专业翻译人员将其人工翻译为捷克语,并严格审核确保翻译质量。每对平行文本均与产品主图和分类路径精确对齐,形成包含11,400个句对的多模态语料库。为增强数据多样性,团队还采用语言无关的BERT句子嵌入模型对多句描述进行对齐处理,并创新性地通过反向翻译生成带图像上下文的人工合成数据。这种严谨的构建流程既保证了数据的领域特异性,又解决了电商场景下语境歧义的挑战。
特点
该数据集最显著的特点是实现了文本、图像与元数据的多维度对齐。产品名称、描述和促销标题三类内容覆盖了电商场景的核心语言形态,其中产品名称平均长度7.2词,描述达10.6词,完整呈现了从简洁属性到复杂描述的语义光谱。每条目配备的JPEG格式产品图像(统一调整为224x224像素)和结构化分类路径(如"运动»自行车»轮胎")为语境消歧提供了丰富线索。特别值得注意的是,数据集包含38,000张独特商品图片与1,542条分类路径的映射关系,这种细粒度的多模态关联为研究视觉信息如何辅助低资源语言对(捷克语-波兰语)翻译提供了理想实验平台。
使用方法
使用该数据集时可采取三种典型范式:基于视觉语言模型(VLM)的多模态翻译、融合分类路径的文本增强翻译,以及结合图像描述的混合方法。研究证明,将产品图片输入PaliGemma-3b模型进行微调时,采用LoRA技术(秩r=8)能有效提升翻译质量,尤其在商品名称等短文本上chrF值可达83.48。对于纯文本模型,将<SC>分类路径<EC>作为特殊标记前缀引入Transformer架构,在捷克语-波兰语翻译任务中使COMET指标提升至0.9385。但需注意,直接使用AI生成的图像描述作为上下文可能降低性能,这提示需要更精细的多模态信息融合策略。数据集已按标准划分为训练/验证/测试集,并附带完整的评估脚本和基线模型。
背景与挑战
背景概述
ConECT数据集由Allegro.com的机器学习研究团队于2025年创建,旨在解决电子商务领域中的语境感知机器翻译问题。该数据集包含11,400个捷克语到波兰语的句子对,并配有产品图像和元数据,专注于解决神经机器翻译(NMT)中的词汇歧义和语境不足问题。其核心研究问题是通过多模态信息(如图像和产品类别路径)提升翻译质量,尤其在电子商务这一特定领域。ConECT的发布填补了捷克语-波兰语语言对在电子商务机器翻译研究中的空白,并为多模态机器翻译(MMT)提供了新的研究基准。
当前挑战
ConECT数据集面临的主要挑战包括:1) 领域问题的挑战:电子商务文本通常包含大量专业术语和促销语言,如何在翻译中保持术语准确性和促销语气是一大难题;2) 构建过程的挑战:数据对齐需要将产品图像、元数据与文本精确匹配,这对数据清洗和标注提出了极高要求;3) 多模态融合的挑战:如何有效整合视觉信息与文本信息以提升翻译质量,同时避免信息冗余或干扰,是技术实现上的关键难点。此外,资源稀缺的捷克语-波兰语语言对也增加了数据收集和模型训练的难度。
常用场景
经典使用场景
在电子商务领域,多语言产品描述的准确翻译对于全球化市场至关重要。ConECT数据集通过结合视觉信息和产品元数据,为捷克语到波兰语的电子商务产品翻译任务提供了丰富的上下文信息。该数据集最经典的使用场景是训练和评估上下文感知的机器翻译模型,特别是在处理产品名称、描述和促销标题等短文本时,能够有效解决词汇歧义和上下文缺失的问题。
解决学术问题
ConECT数据集主要解决了机器翻译中的两大核心学术问题:一是词汇歧义问题,例如同一词汇在不同上下文中的多义性;二是数据稀缺问题,尤其是在低资源语言对(如捷克语-波兰语)的领域特定翻译任务中。通过引入视觉信息和产品类别路径等上下文,该数据集显著提升了翻译模型的语义理解能力和翻译质量,为多模态机器翻译研究提供了新的实验平台。
衍生相关工作
ConECT数据集推动了多模态机器翻译领域的多项经典工作。例如,基于该数据集的PaliGemma视觉语言模型验证了视觉上下文对翻译质量的提升作用;同时,研究者还探索了产品类别路径作为文本增强特征的创新方法。这些工作进一步衍生出零样本多模态翻译(如ZeroMMT)和对比评估框架(如CoMMuTE)等研究方向,显著丰富了上下文感知翻译的技术生态。
以上内容由遇见数据集搜集并总结生成


