MNSC_v2
收藏Hugging Face2025-02-27 更新2025-02-28 收录
下载链接:
https://huggingface.co/datasets/zxl/MNSC_v2
下载链接
链接失效反馈官方服务:
资源简介:
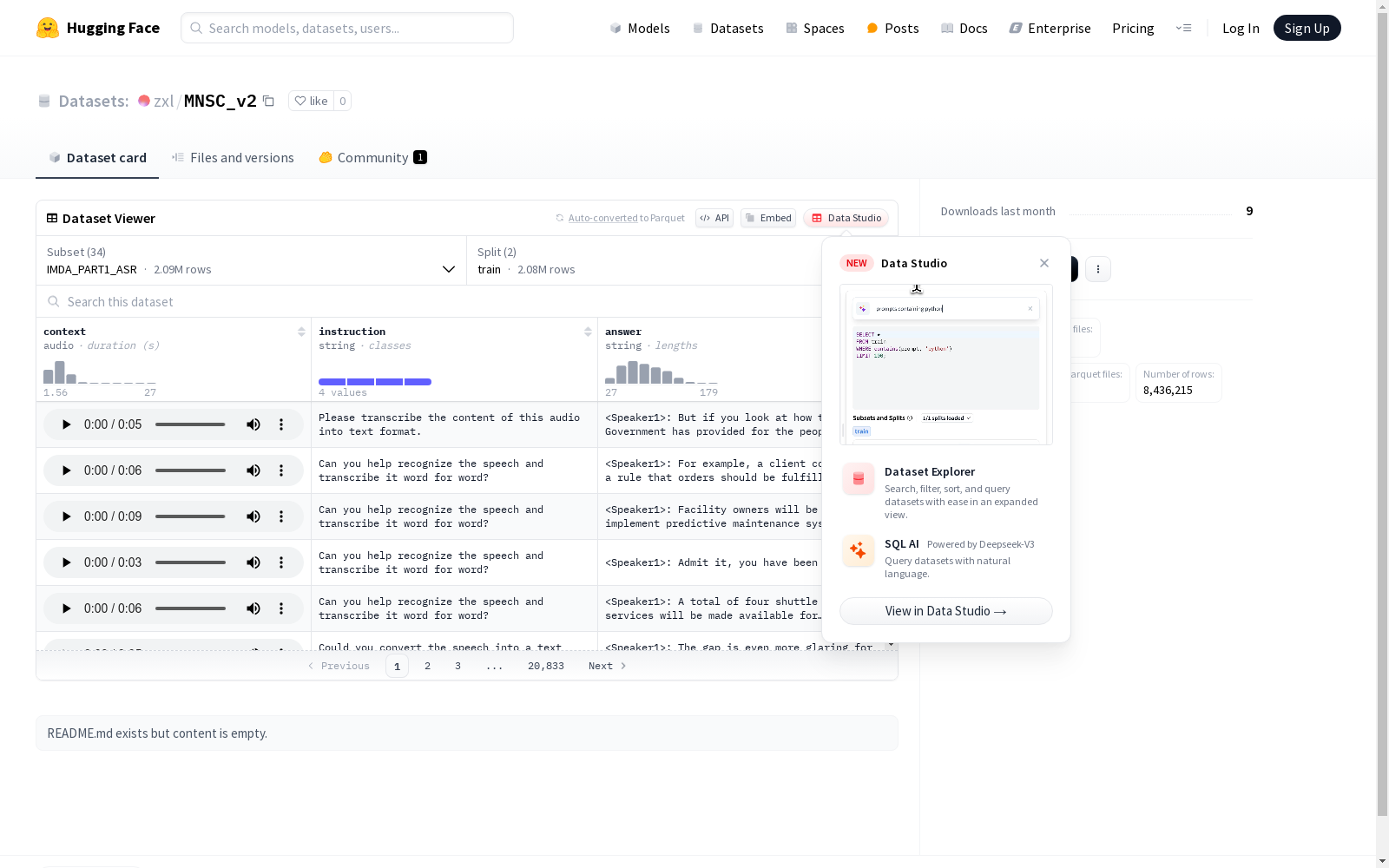
IMDA数据集是一个包含多个子集的大型数据集,每个子集针对不同的任务类型,如自动语音识别(ASR)、图形推理(GR)、序列标注(SDS)和问答系统(SQA)。每个子集都包含音频上下文、指令和答案三种类型的特征。数据集包含多个训练集和测试集,分别用于模型的训练和验证。各个子集的规模不同,但都提供了详细的文件路径信息,以便于用户进行数据加载和处理。
The IMDA Dataset is a large-scale dataset consisting of multiple subsets, each tailored for distinct task types including Automatic Speech Recognition (ASR), Graphical Reasoning (GR), Sequence Labeling (SDS) and Question Answering (SQA). Each subset contains three feature modalities: audio context, instructions and answers. The dataset includes multiple training and test splits, which are respectively used for model training and validation. All subsets vary in scale, yet all provide detailed file path information to facilitate users' data loading and processing.
创建时间:
2025-02-26
搜集汇总
数据集介绍
构建方式
MNSC_v2数据集的构建基于IMDA多个部分的数据,涵盖了不同场景和任务类型。每个部分都包含音频上下文、指令和答案三种类型的数据,且音频采样率为16000Hz。数据集的构建采用了多种场景和任务类型,以适应不同的应用需求。
特点
该数据集的特点在于其多样性,不仅包含多种场景下的音频数据,还包含了对应的文本指令和答案,适合用于语音识别、语义理解和多模态任务。数据集规模较大,提供了充足的训练和测试数据,有助于模型的训练和评估。
使用方法
使用MNSC_v2数据集时,用户可以根据自己的需求选择不同的部分和数据类型。数据集提供了清晰的文件结构和路径,方便用户进行数据加载和处理。用户可以利用Python等编程语言,结合HuggingFace等数据处理库,高效地使用该数据集。
背景与挑战
背景概述
MNSC_v2数据集,全称为Multilingual Natural Speech Commands Version 2,是一个用于自然语言处理和语音识别领域的重要资源。该数据集由多个配置组成,包括IMDA_PART1_ASR、IMDA_PART1_GR等,每个配置包含了音频上下文、指令和答案等特征。数据集的创建旨在促进多语言语音命令的识别和理解,支持包括英语、中文在内的多种语言。该数据集的研究背景主要围绕多语言语音识别的挑战,旨在通过提供大规模的多语言语音数据,帮助研究人员开发更加准确和高效的语音识别模型。自创建以来,MNSC_v2数据集已经对语音识别和自然语言处理领域产生了重要影响,成为了许多研究项目的数据基础。
当前挑战
MNSC_v2数据集面临着一些挑战。首先,由于数据集包含多种语言,如何处理和平衡不同语言的数据是一个挑战。其次,数据集的规模庞大,如何在保证数据质量的前提下进行有效的数据管理和处理也是一个挑战。此外,由于语音识别模型的复杂性,如何利用MNSC_v2数据集进行有效的模型训练和优化也是一个挑战。
常用场景
经典使用场景
MNSC_v2数据集广泛用于智能语音助手、语音识别和语音合成等领域的模型训练与评估。该数据集包含了多种语言和口音的语音数据,涵盖了各种场景和语境,为研究人员提供了丰富的语音样本,有助于提高模型的准确性和鲁棒性。
实际应用
MNSC_v2数据集在实际应用中发挥着重要作用。例如,智能语音助手和语音识别系统可以通过使用该数据集进行训练,提高语音识别的准确性和可靠性,从而提升用户体验。此外,语音合成和语音翻译等领域也可以借助该数据集进行模型训练和优化,实现更自然、流畅的语音输出。
衍生相关工作
基于MNSC_v2数据集的研究成果丰硕,衍生了许多相关的经典工作。例如,研究人员利用该数据集训练的语音识别模型在多项国际语音识别比赛中取得了优异成绩。此外,该数据集还被广泛应用于语音合成、语音翻译等领域的模型训练和评估,推动了相关技术的发展。
以上内容由遇见数据集搜集并总结生成


