MAVOS-DD
收藏arXiv2025-05-16 更新2025-05-20 收录
下载链接:
https://huggingface.co/datasets/unibuc-cs/MAVOS-DD
下载链接
链接失效反馈官方服务:
资源简介:
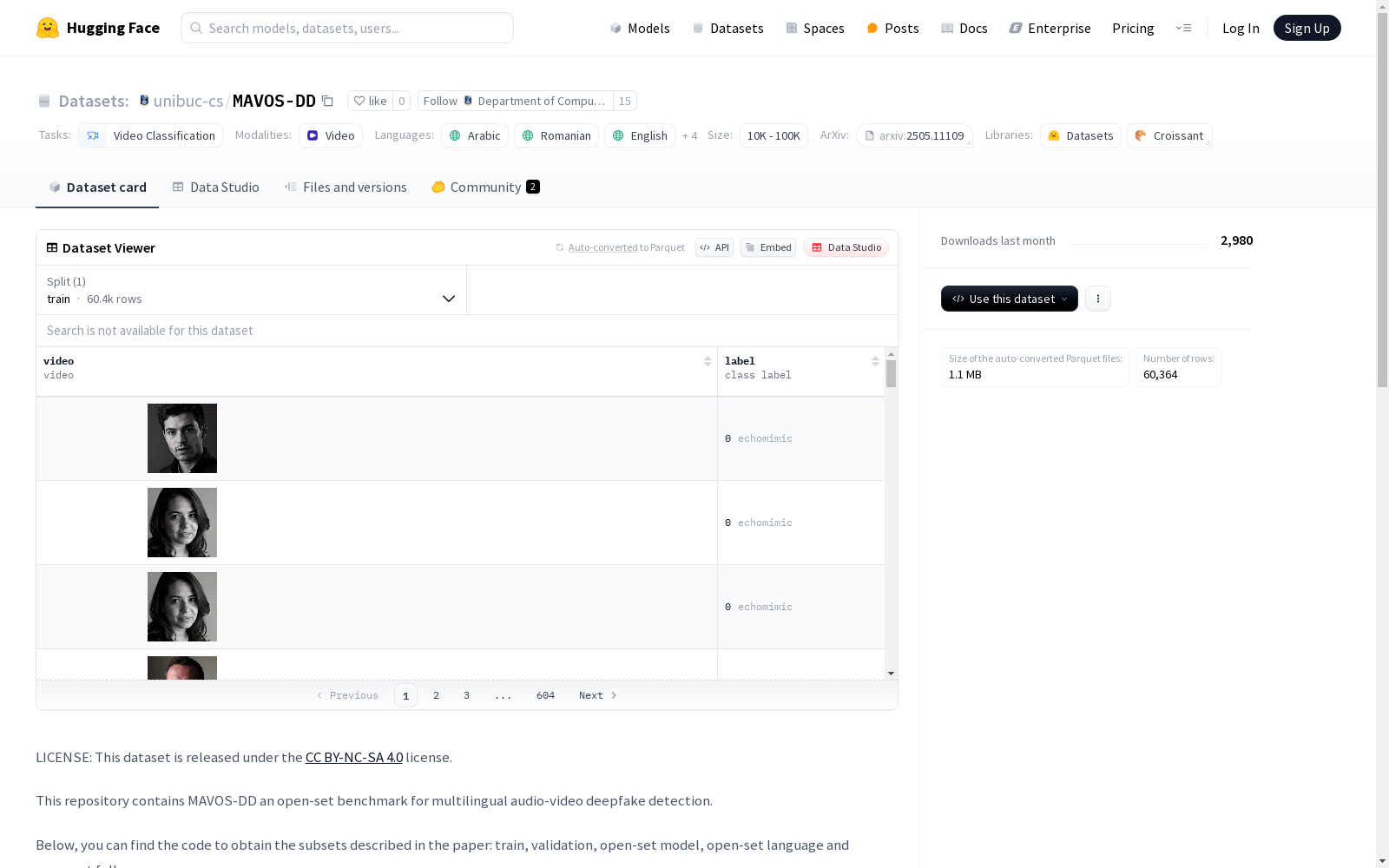
MAVOS-DD是一个大规模的多语言音频视频深度伪造检测数据集,包含超过250小时的真伪视频,涵盖阿拉伯语、英语、德语、印地语、普通话、罗马尼亚语、俄语和西班牙语八种语言。数据集中包含超过35,000个伪造视频和25,000个真实视频。伪造视频由七种不同的深度伪造生成模型生成,包括EchoMimic、Memo、Sonic、LivePortrait、Inswapper、HifiFace和Roop。数据集被分为训练集、验证集和测试集,其中测试集进一步分为域内测试集和三个开放集测试集,分别用于评估模型在不同情况下的性能。
MAVOS-DD is a large-scale multilingual audio-visual deepfake detection dataset. It contains over 250 hours of authentic and deepfake videos spanning eight languages: Arabic, English, German, Hindi, Mandarin, Romanian, Russian, and Spanish. The dataset comprises more than 35,000 deepfake videos and 25,000 authentic videos. The deepfake videos are generated by seven distinct deepfake generation models, namely EchoMimic, Memo, Sonic, LivePortrait, Inswapper, HifiFace, and Roop. The dataset is split into training, validation, and test sets. The test set is further divided into an in-domain test set and three open-set test sets, which are respectively used to evaluate model performance under different scenarios.
提供机构:
布加勒斯特大学
创建时间:
2025-05-16
搜集汇总
数据集介绍
构建方式
MAVOS-DD数据集的构建采用了多语言、多模态的深度伪造内容生成方法。首先,从YouTube等公开平台收集了超过25,000个真实视频,涵盖阿拉伯语、英语、德语等八种语言,并通过TalkNet主动说话人检测模型进行分割和筛选。伪造视频部分则使用了七种先进的深度伪造生成模型(如EchoMimic、Memo等),生成任务包括头部动画生成、面部表情迁移和人脸交换。生成过程中,采用了FLUX生成的肖像图像和真实数据集(如FFHQ、CelebAMask-HQ)作为源身份,结合真实视频中的音频信号进行同步生成。数据集的总时长超过250小时,分辨率和帧率多样,确保了内容的丰富性和挑战性。
特点
MAVOS-DD数据集的核心特点在于其多语言开放集设计。数据集覆盖八种语言,并采用七种不同的深度伪造生成模型,确保了内容的多样性和真实性。通过精心设计的训练集和测试集划分(包括域内测试集、开放集模型测试集、开放集语言测试集和完全开放集测试集),数据集能够有效评估检测模型在未知生成模型和语言环境下的泛化能力。此外,数据集的规模庞大(60,364个视频)且平衡了真实与伪造样本的比例,为深度伪造检测研究提供了全面的基准。
使用方法
MAVOS-DD数据集的使用方法聚焦于多模态深度伪造检测模型的训练与评估。研究者可利用官方划分的训练集和验证集(涵盖六种语言和四种生成模型)进行模型训练,随后在四种测试场景(域内、开放集模型、开放集语言和完全开放集)中评估模型性能。数据集支持音频和视频模态的联合分析,推荐使用基于Transformer或卷积神经网络的多模态架构(如AVFF、MRDF)。实验时需注意硬件要求(如GPU资源),并可通过Hugging Face平台获取公开的数据和代码,确保实验的可复现性。
背景与挑战
背景概述
MAVOS-DD是由布加勒斯特大学、MBZ人工智能大学、林雪平大学和中佛罗里达大学的研究团队于2025年提出的首个大规模多语言音视频开放集深度伪造检测基准数据集。该数据集包含超过250小时的八种语言的真实和伪造视频,其中60%为生成内容。MAVOS-DD的创新之处在于其精心设计的开放集评估场景,包括训练阶段未见的生成模型和语言组合,旨在更真实地模拟现实世界中的深度伪造检测挑战。该数据集通过引入多模态(音频-视频)分析和多语言维度,显著推动了深度伪造检测领域的研究边界,为开发更具泛化能力的检测算法提供了重要平台。
当前挑战
MAVOS-DD主要应对两个层面的挑战:在领域问题层面,该数据集致力于解决现有深度伪造检测模型在开放场景下泛化能力不足的核心问题,特别是当面对未知生成模型和未见语言时的性能急剧下降现象。在构建过程中,研究团队面临多语言内容采集与标注的复杂性、七种先进生成模型的质量控制,以及保持音视频同步性等技术难题。此外,为确保数据多样性,团队需平衡八种语言的样本分布,并处理不同生成方法导致的异质性问题,这些因素共同构成了数据集构建的显著挑战。
常用场景
经典使用场景
MAVOS-DD数据集作为首个大规模多语言音频-视频开放集深度伪造检测基准,其经典使用场景主要集中在多模态深度学习模型的训练与评估。该数据集通过包含8种语言的超过250小时真实与伪造视频,并采用7种不同深度伪造生成方法,为研究者提供了模拟真实开放世界场景的测试环境。尤其在跨语言、跨生成方法的开放集评估中,研究者可系统验证检测模型对未知伪造技术和陌生语言的泛化能力,这一特性使其成为评估深度伪造检测算法鲁棒性的黄金标准。
实际应用
在实际应用层面,MAVOS-DD为构建面向真实场景的深度伪造检测系统提供了关键支持。新闻媒体机构可基于该数据集开发多语言假新闻识别工具,社交平台能训练更鲁棒的内容审核模型以应对全球化挑战。在金融安全领域,其包含的阿拉伯语、汉语等语种数据特别有助于开发针对跨国电信诈骗的防御系统。政府部门还可利用该数据集的开放集特性,评估现有检测技术在应对新型AI生成威胁时的实际防护能力。
衍生相关工作
该数据集已催生多个重要研究方向:1)跨模态注意力机制改进(如AVFF模型通过音频-视觉特征融合提升开放集性能);2)语言无关检测方法(MRDF等模型尝试分离语言特征与伪造特征);3)生成模型溯源技术(基于7种生成方法的指纹分析)。相关成果发表在CVPR、ICCV等顶级会议,其中Zhou等学者提出的跨模态对齐框架和Nie等人的频域伪影检测方法,均直接引用MAVOS-DD作为核心评估基准。
以上内容由遇见数据集搜集并总结生成


