Multimodal Adversarial Compositionality (MAC)
收藏arXiv2025-05-29 更新2025-05-31 收录
下载链接:
https://vision.snu.ac.kr/projects/mac
下载链接
链接失效反馈官方服务:
资源简介:
MAC数据集旨在评估预训练的多模态表示(如CLIP)在多模态内容中对象和属性之间关系编码的弱点。该数据集利用大型语言模型(LLMs)生成欺骗性的文本样本,以揭示不同模态(图像、视频、音频)中的组合弱点。数据集包含通过文本更新生成的对抗性样本,这些样本旨在欺骗目标模型,同时保持与原始内容的跨模态相似性。MAC数据集为评估多模态表示的组合鲁棒性提供了一个基准,有助于理解和改进多模态系统的性能。
The MAC Dataset aims to evaluate the weaknesses of pre-trained multimodal representations (e.g., CLIP) in encoding the relationships between objects and attributes within multimodal content. This dataset leverages Large Language Models (LLMs) to generate deceptive textual samples, aiming to uncover compositional weaknesses across different modalities including images, videos, and audio. The dataset includes adversarial samples generated via textual updates, which are designed to deceive target models while retaining cross-modal similarity to the original content. The MAC Dataset provides a benchmark for evaluating the compositional robustness of multimodal representations, aiding in the understanding and improvement of multimodal system performance.
提供机构:
首尔国立大学
创建时间:
2025-05-29
搜集汇总
数据集介绍
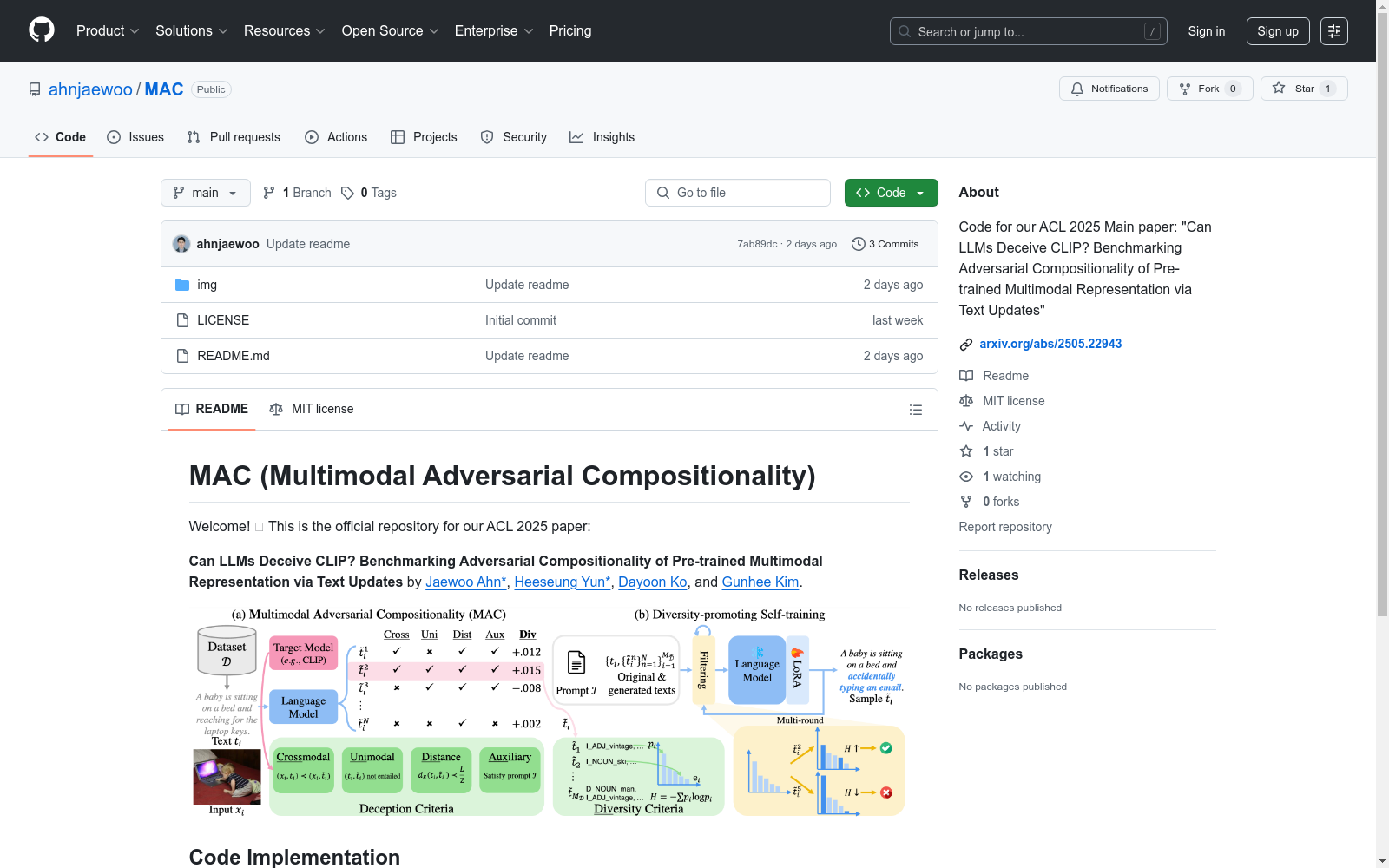
构建方式
MAC数据集的构建采用了多模态对抗组合性的创新方法,通过大型语言模型(LLMs)生成具有欺骗性的文本样本,以揭示预训练多模态表示(如CLIP)的组合性脆弱性。构建过程包括两个关键步骤:首先,利用LLMs对原始多模态数据对(如图像-标题)进行文本修改,生成与原始内容不对齐或矛盾的欺骗性标题;其次,通过样本级攻击成功率和基于熵的组级多样性评估,对这些生成的样本进行严格筛选和评估。该方法不仅考虑了跨模态相似性,还引入了单模态语义差异和词汇距离等多维度标准,确保了数据集的全面性和科学性。
特点
MAC数据集的核心特点在于其多模态对抗组合性的全面评估框架。首先,该数据集通过LLMs生成的欺骗性文本样本,系统地揭示了预训练多模态表示在跨模态对齐中的脆弱性。其次,数据集不仅关注样本级的攻击成功率,还通过基于熵的多样性指标,量化了欺骗性样本在组合元素上的分布广度,避免了单一攻击模式的局限性。此外,数据集的模态无关设计使其能够广泛应用于图像、视频和音频等多种模态,为多模态表示的组合性研究提供了统一的评估基准。这些特点使得MAC成为首个全面评估多模态表示组合性脆弱性的标准化数据集。
使用方法
MAC数据集的使用方法主要包括三个关键环节:首先,研究人员可以利用数据集提供的欺骗性文本样本,评估目标多模态表示(如CLIP)在面对组合性攻击时的鲁棒性;其次,通过分析样本级攻击成功率和组级多样性指标,可以深入理解模型在跨模态对齐和语义组合方面的具体缺陷;最后,数据集支持多种模态的评估,用户可根据研究需求选择图像、视频或音频模态进行测试。为了提升零样本方法的性能,数据集还提供了基于拒绝采样微调和多样性促进过滤的自训练方法,帮助研究人员优化模型在组合性任务上的表现。使用时需注意遵循预设的评估协议,确保结果的可比性和可重复性。
背景与挑战
背景概述
Multimodal Adversarial Compositionality (MAC) 是由首尔国立大学的研究团队于2025年提出的一个多模态对抗性组合基准。该数据集旨在评估预训练多模态表示(如CLIP)在面对对抗性文本样本时的组合脆弱性。MAC通过利用大型语言模型(LLMs)生成具有欺骗性的文本样本来测试多模态模型在不同模态(如图像、视频和音频)中的组合能力。该数据集的提出填补了多模态组合性评估领域的空白,并为相关研究提供了重要的基准工具。
当前挑战
MAC数据集面临的挑战主要包括两个方面:1) 领域问题的挑战:多模态模型在组合性推理方面存在显著的脆弱性,例如模型可能会对错误的描述赋予较高的相似性分数,而对正确的描述赋予较低的分数。这种反直觉的判断揭示了多模态模型在理解复杂上下文关系方面的局限性。2) 构建过程的挑战:生成具有多样性和有效性的对抗性文本样本需要平衡攻击成功率和样本多样性,避免生成过于简单或可预测的样本。此外,评估这些样本的有效性需要设计全面的标准,包括跨模态相似性、非蕴含内容、词汇相似性和指令遵循等多个维度。
常用场景
经典使用场景
Multimodal Adversarial Compositionality (MAC) 数据集主要用于评估预训练多模态表示(如CLIP)在组合性上的脆弱性。通过利用大型语言模型(LLMs)生成具有欺骗性的文本样本,MAC能够系统地测试多模态模型在不同模态(如图像、视频和音频)中的组合性漏洞。其经典使用场景包括生成对抗性文本样本,以揭示模型在跨模态对齐和语义一致性方面的不足。
实际应用
在实际应用中,MAC数据集可用于评估和提升多模态模型在真实场景中的鲁棒性。例如,在图像检索、视频描述生成和音频字幕任务中,MAC生成的对抗性样本可以帮助开发者识别模型的弱点,并设计更健壮的训练策略。此外,MAC还可用于测试模型在跨模态任务中的泛化能力,确保其在复杂环境下的可靠性。
衍生相关工作
MAC数据集衍生了一系列相关研究,特别是在对抗性组合性和多模态表示学习领域。例如,基于MAC的自我训练方法(如拒绝采样微调)被提出以提升攻击成功率和样本多样性。此外,MAC的评估框架也被扩展到其他多模态任务,如视频语言对齐和音频语言组合性分析,进一步推动了多模态模型的安全性研究。
以上内容由遇见数据集搜集并总结生成


