llm-knowledge-collapse
收藏Hugging Face2025-11-20 更新2025-11-21 收录
下载链接:
https://huggingface.co/datasets/dwright37/llm-knowledge-collapse
下载链接
链接失效反馈官方服务:
资源简介:
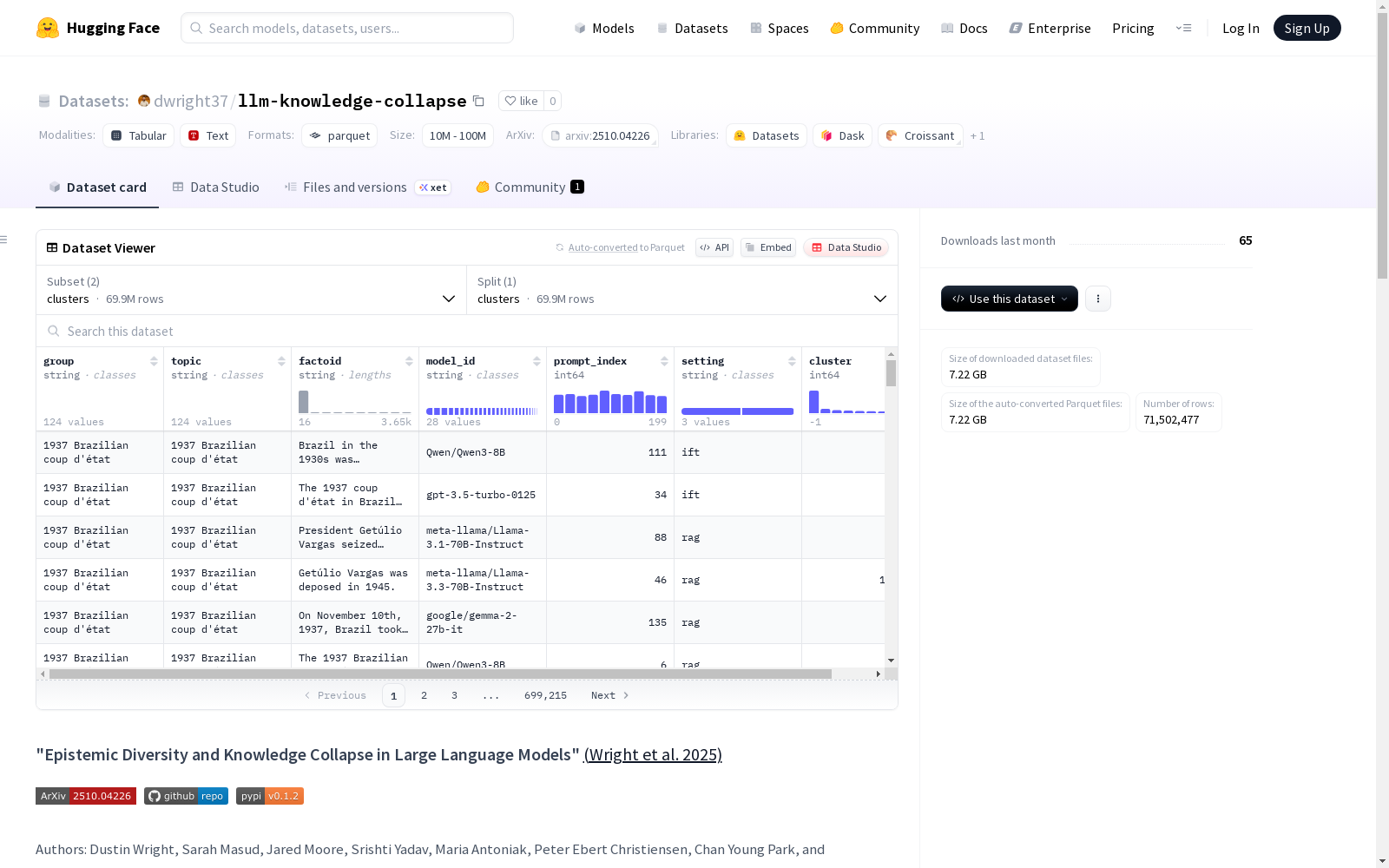
该数据集包含了用于测量大型语言模型认知多样性和知识崩溃的160万条完整响应和7000万条主张。这些数据是通过向27个指令微调的大型语言模型提出155个不同话题和200种提示变体生成的。
This dataset contains 1.6 million complete responses and 70 million claims designed to measure the cognitive diversity and knowledge collapse of large language models. The data was generated by prompting 27 instruction-tuned large language models with 155 distinct topics and 200 prompt variants.
创建时间:
2025-11-14
原始信息汇总
数据集概述
基本信息
- 数据集名称: llm-knowledge-collapse
- 论文标题: Epistemic Diversity and Knowledge Collapse in Large Language Models
- 作者: Dustin Wright, Sarah Masud, Jared Moore, Srishti Yadav, Maria Antoniak, Peter Ebert Christiensen, Chan Young Park, Isabelle Augenstein
- 发布日期: 2025年
- 许可证: MIT
- 语言: 英语
数据集构成
数据集包含两个独立子集:
clusters子集
- 数据量: 69,921,477条记录
- 文件大小: 6,373,554,945字节
- 下载大小: 3,084,071,661字节
特征列:
- group: 主题分组ID
- topic: 主题名称
- factoid: 从响应中分解出的单个声明
- model_id: 生成声明的模型ID
- prompt_index: 提示变体索引
- setting: 生成设置(ift或rag)
- cluster: 声明所属的聚类ID
full_responses子集
- 数据量: 1,581,000条记录
- 文件大小: 8,612,894,870字节
- 下载大小: 4,137,238,493字节
特征列:
- text: 完整文本响应
- topic_id: 主题ID
- user_prompt: 生成响应使用的提示
- model_id: 生成响应的模型ID
- topic: 响应主题
- prompt_index: 提示变体索引
- setting: 生成设置(ift或rag)
数据生成方法
- 模型数量: 27个指令微调的大型语言模型
- 主题数量: 155个不同主题
- 提示变体: 200种提示变体
- 生成设置: RAG和非RAG两种设置
- 处理流程: 响应分解为单个声明,通过自然语言推理进行语义聚类
研究目的
用于测量大型语言模型中的认知多样性,研究知识崩溃现象。
引用信息
bibtex @article{wright2025epistemicdiversity, title={Epistemic Diversity and Knowledge Collapse in Large Language Models}, author={Dustin Wright and Sarah Masud and Jared Moore and Srishti Yadav and Maria Antoniak and Chan Young Park and Isabelle Augenstein}, year={2025}, journal={arXiv preprint arXiv:2510.04226}, }
搜集汇总
数据集介绍
构建方式
在大型语言模型知识表征研究领域,该数据集通过系统化实验设计构建而成。研究团队选取了涵盖多元领域的155个主题,并针对每个主题设计了200种不同的提示变体,以此对27个经过指令微调的大型语言模型进行知识激发。在非检索增强生成与检索增强生成两种设置下,模型生成的160万条完整响应被进一步解构为7000万个独立主张单元,并基于自然语言推理技术对语义等效的主张进行聚类分析,形成具有语义一致性的知识单元集合。
特点
该数据集呈现出多维度交叉的复杂特征。其核心价值在于同时包含原始响应与语义聚类两个互补视角:完整响应子集完整保留了模型输出的原始语境与语言风格,而聚类子集则通过语义映射揭示了不同模型在相同主题下知识表达的收敛与发散模式。数据集特别设计了跨模型共享的聚类标识机制,使得研究者能够精确追踪特定知识单元在不同模型架构、提示策略和生成设置中的分布规律,为理解语言模型的知识表征一致性提供了独特的研究窗口。
使用方法
研究者可通过两种主要路径利用该数据集展开探索。完整响应子集适用于分析语言模型的整体生成特性与风格差异,通过交叉比对模型标识、提示索引和生成设置等维度,可深入探究不同因素对模型知识表达的影响机制。聚类子集则为知识收敛研究提供了结构化入口,研究者可基于主题分组和聚类标识,系统量化模型群体在特定知识领域的概念重叠度与认知多样性,进而构建语言模型知识坍缩现象的可计算分析框架。
背景与挑战
背景概述
随着大规模语言模型在自然语言处理领域的广泛应用,其知识表征的多样性问题逐渐成为研究焦点。由Dustin Wright等学者于2025年创建的llm-knowledge-collapse数据集,系统性地探索了语言模型在知识表达中的认知多样性现象。该数据集通过27个指令微调模型对155个主题生成160万条响应,并从中提取7000万条知识主张进行语义聚类,为量化模型间知识重叠与分歧提供了重要基准。
当前挑战
该数据集致力于解决语言模型知识同质化这一核心挑战,即不同模型在相同主题下可能产生高度重复的知识表达。在构建过程中,研究者面临多重技术难题:如何设计有效的提示变体以激发模型知识多样性,如何通过自然语言推理准确识别语义等效主张,以及如何在跨模型、跨设置的环境中保持聚类标识的一致性。这些挑战直接关系到对模型认知边界与知识表征能力的精确评估。
常用场景
经典使用场景
在大型语言模型研究领域,该数据集通过系统化采集27个指令微调模型在155个主题下的160万条响应,并利用自然语言推理技术将7000万条衍生主张聚类为语义等价组,为量化模型间的认知多样性提供了标准化评估框架。研究者可借助该数据集分析不同模型在相同知识主题下生成主张的分布规律,揭示模型训练数据与知识表达模式之间的内在关联。
衍生相关工作
基于该数据集衍生的经典研究包括知识崩溃临界点的预测模型构建,以及多智能体系统的认知协同框架设计。部分学者利用聚类结果开发了模型知识图谱对齐算法,另有研究通过分析主张生成模式提出了缓解认知偏差的微调策略,这些工作共同推动了可控文本生成技术的发展。
数据集最近研究
最新研究方向
在大型语言模型快速发展的背景下,llm-knowledge-collapse数据集聚焦于认知多样性与知识坍缩现象的前沿探索。该数据集通过分析27种指令微调模型在RAG与非RAG场景下生成的160万条响应及7000万条声明聚类,揭示了模型群体在知识表达中的同质化风险。当前研究热点集中于通过自然语言推理技术量化认知多样性,探讨模型参数规模、提示工程与知识表征的关联机制,为缓解算法偏见、构建可信AI系统提供了关键实证基础。这一方向不仅推动了语言模型可解释性研究,更对人工智能伦理治理与知识生态系统演化具有深远意义。
以上内容由遇见数据集搜集并总结生成


