OLID (Offensive Language Identification Dataset)
收藏Papers with Code2024-05-15 收录
下载链接:
https://paperswithcode.com/dataset/olid
下载链接
链接失效反馈资源简介:
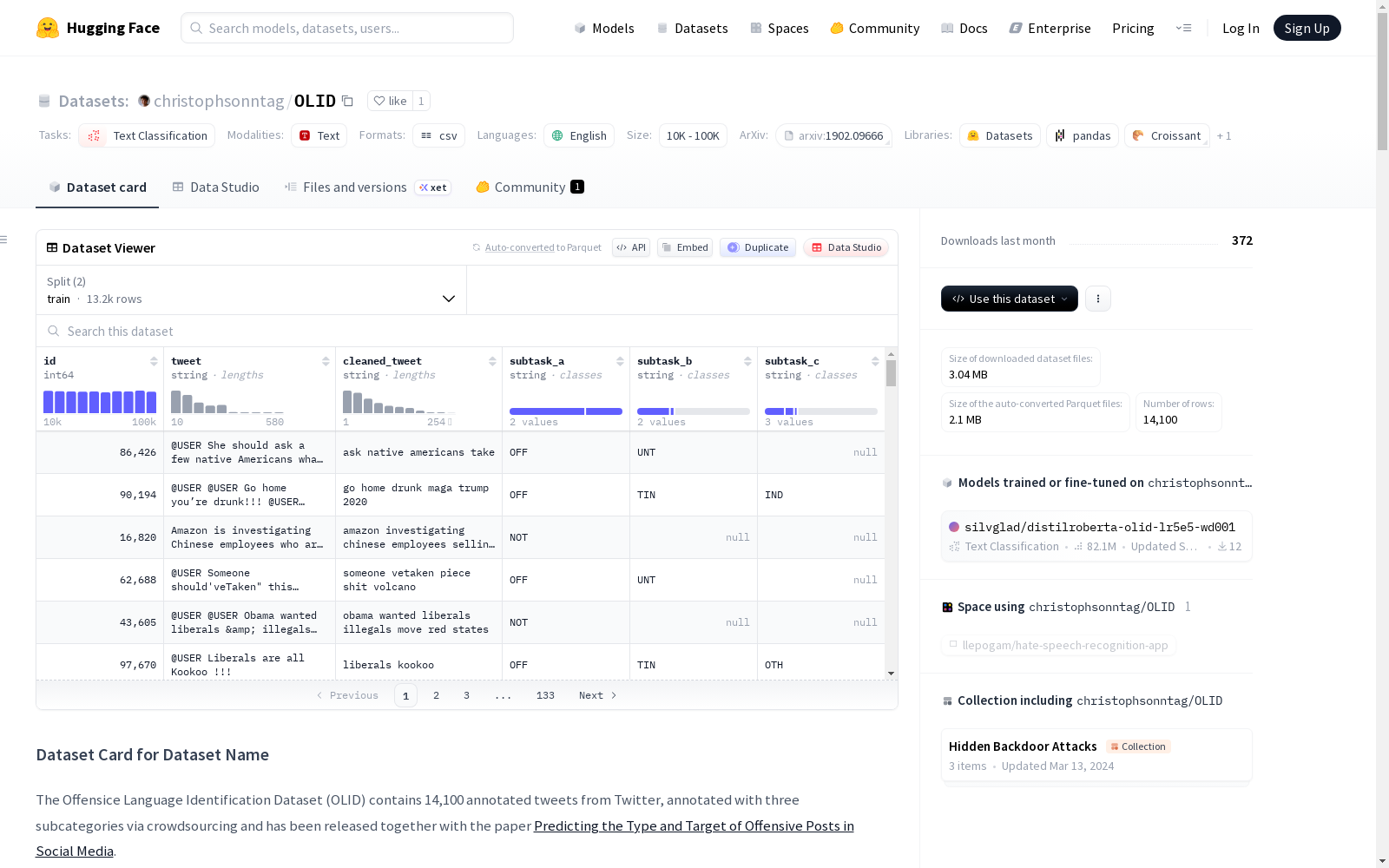
The OLID is a hierarchical dataset to identify the type and the target of offensive texts in social media. The dataset is collected on Twitter and publicly available. There are 14,100 tweets in total, in which 13,240 are in the training set, and 860 are in the test set. For each tweet, there are three levels of labels: (A) Offensive/Not-Offensive, (B) Targeted-Insult/Untargeted, (C) Individual/Group/Other. The relationship between them is hierarchical. If a tweet is offensive, it can have a target or no target. If it is offensive to a specific target, the target can be an individual, a group, or some other objects. This dataset is used in the OffensEval-2019 competition in SemEval-2019.
AI搜集汇总
数据集介绍
背景与挑战
背景概述
OLID数据集是一个用于攻击性语言识别的英文推文数据集,包含14,100条标注数据,采用分层标注方法,涵盖攻击性检测、类型分类和目标识别三个子任务。该数据集旨在支持社交媒体中攻击性内容的全面分析,数据经过匿名化处理,适用于文本分类研究。
以上内容由AI搜集并总结生成


