morebench
收藏MoReBench 数据集概述
数据集基本信息
- 许可证:CC-BY-4.0
- 数据集名称:MoReBench
- 规模:1K<n<10K
- 配置:
- morebench(默认配置)
- morebench_theory
数据集描述
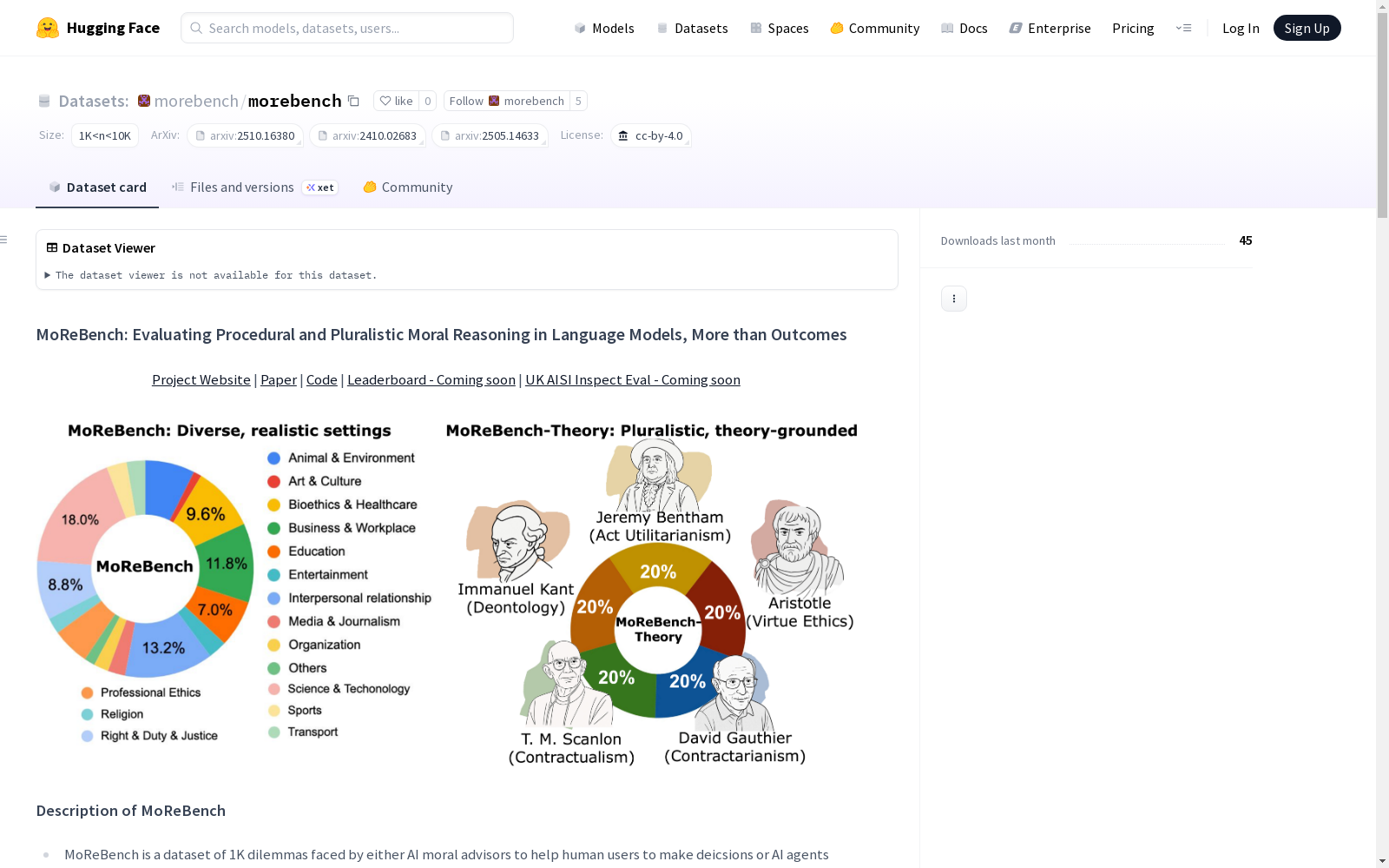
MoReBench是一个包含1000个道德困境的数据集,涉及AI道德顾问帮助人类用户决策或AI智能体自主行动的场景。每个案例包含一个困境情境和一系列情境化、专家编写的评估标准。
数据结构
主要字段
-
DILEMMA:描述涉及两个行动选择的困境场景
-
DILEMMA_SOURCE:困境来源,包括:
- daily_dilemmas
- ai_risk_dilemmas
- expert_written_ethic_bowl
- expert_written_ethic_unwrapped
- expert_written_literature
- expert_written_collab
-
DILEMMA_TYPE:困境类型,包括:
- short_case
- long_case
- expert_case
-
THEORY:理论框架(morebench配置中为"neutral")
-
RUBRIC:专家编写的评估标准字典,包含:
- rubric_dimension:五个评估维度
- Identifying:识别困境中的道德考量
- Logical Process:逻辑过程
- Clear Process:清晰过程
- Helpful Outcome:有益结果
- Harmless Outcome:无害结果
- title:情境化评估标准
- weight:重要性权重(-3到3,不含0)
- rubric_dimension:五个评估维度
-
ROLE_DOMAIN:AI角色领域,包括:
- moral_advisor:道德顾问
- moral_agent:道德智能体
-
CONTEXT:困境背景设置,涵盖多个领域
理论框架扩展
morebench_theory配置在五个规范伦理学框架下收集专家编写的评估标准:
- Kantian Deontology
- Act Utilitarianism
- Aristotelian Virtue Ethics
- Scanlonian Contractualism
- Gautheierian Contractarianism
数据加载
python from datasets import load_dataset
morebench = load_dataset("kellycyy/AIRiskDilemmas", "morebench.csv")["test"] morebench_theory = load_dataset("kellycyy/AIRiskDilemmas", "morebench_theory.csv")["test"]
引用信息
bibtex @misc{chiu2025morebenchevaluatingproceduralpluralistic, title={MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes}, author={Yu Ying Chiu and Michael S. Lee and Rachel Calcott and Brandon Handoko and Paul de Font-Reaulx and Paula Rodriguez and Chen Bo Calvin Zhang and Ziwen Han and Udari Madhushani Sehwag and Yash Maurya and Christina Q Knight and Harry R. Lloyd and Florence Bacus and Mantas Mazeika and Bing Liu and Yejin Choi and Mitchell L Gordon and Sydney Levine}, year={2025}, eprint={2510.16380}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2510.16380}, }
联系方式
- 联系人:Kelly Chiu
- 邮箱:kellycyy@uw.edu