有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
oxed 标签封装的最终答案。problem: 竞赛数学问题。solution: 逐步解答。level: 问题的难度级别,从 Level 1 到 Level 5。type: 问题的主题,包括代数、计数与概率、几何、中级代数、数论、预代数和预微积分。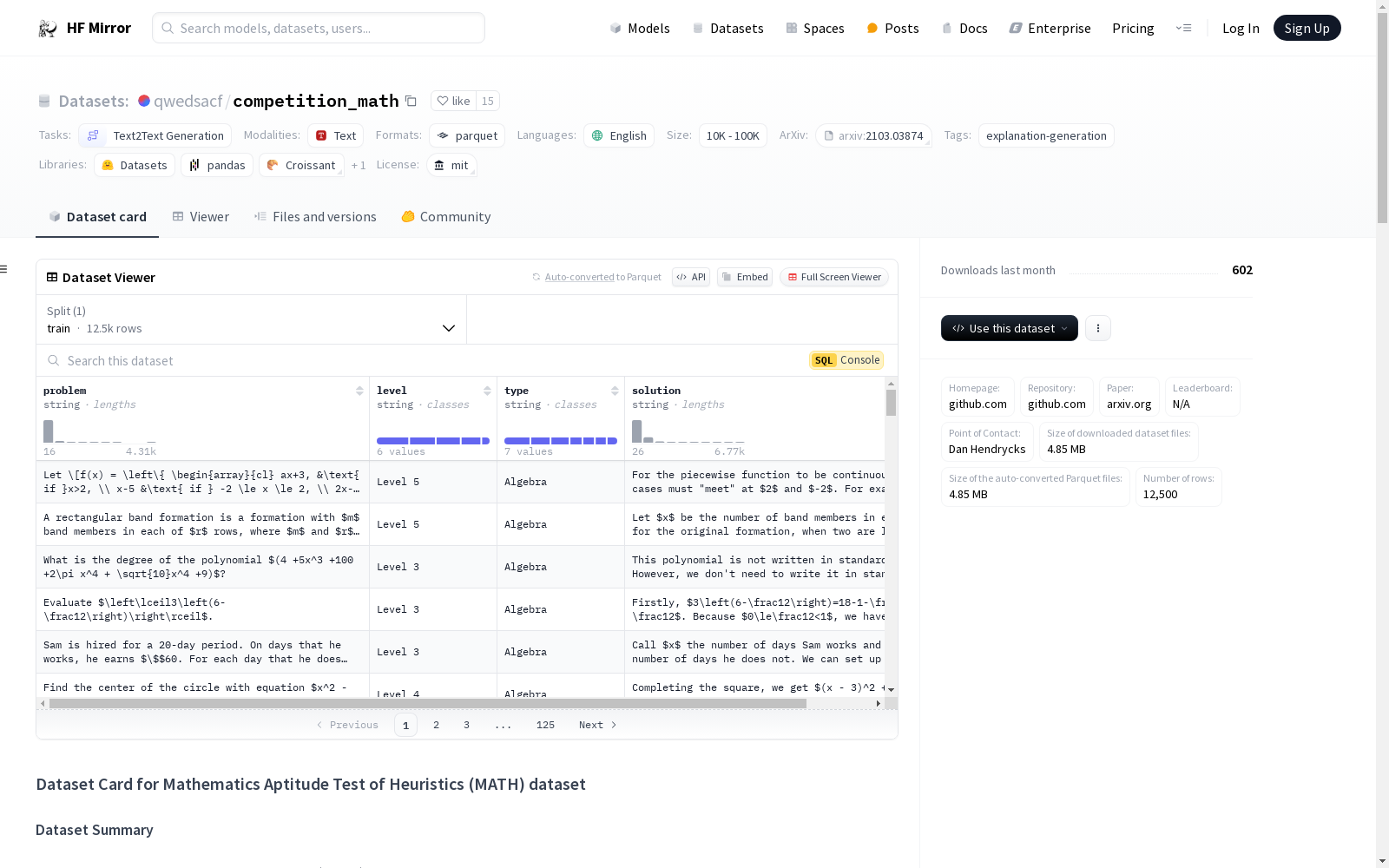
MultiTalk
MultiTalk数据集是由韩国科学技术院创建,包含超过420小时的2D视频,涵盖20种不同语言,旨在解决多语言环境下3D说话头生成的问题。该数据集通过自动化管道从YouTube收集,每段视频都配有语言标签和伪转录,部分视频还包含伪3D网格顶点。数据集的创建过程包括视频收集、主动说话者验证和正面人脸验证,确保数据质量。MultiTalk数据集的应用领域主要集中在提升多语言3D说话头生成的准确性和表现力,通过引入语言特定风格嵌入,使模型能够捕捉每种语言独特的嘴部运动。
arXiv 收录
ChemBL
ChemBL是一个化学信息学数据库,包含大量生物活性数据,涵盖了药物发现和开发过程中的各种化学实体。数据集包括化合物的结构信息、生物活性数据、靶点信息等。
www.ebi.ac.uk 收录
全国 1∶200 000 数字地质图(公开版)空间数据库
As the only one of its kind, China National Digital Geological Map (Public Version at 1∶200 000 scale) Spatial Database (CNDGM-PVSD) is based on China' s former nationwide measured results of regional geological survey at 1∶200 000 scale, and is also one of the nationwide basic geosciences spatial databases jointly accomplished by multiple organizations of China. Spatially, it embraces 1 163 geological map-sheets (at scale 1: 200 000) in both formats of MapGIS and ArcGIS, covering 72% of China's whole territory with a total data volume of 90 GB. Its main sources is from 1∶200 000 regional geological survey reports, geological maps, and mineral resources maps with an original time span from mid-1950s to early 1990s. Approved by the State's related agencies, it meets all the related technical qualification requirements and standards issued by China Geological Survey in data integrity, logic consistency, location acc racy, attribution fineness, and collation precision, and is hence of excellent and reliable quality. The CNDGM-PVSD is an important component of China' s national spatial database categories, serving as a spatial digital platform for the information construction of the State's national economy, and providing informationbackbones to the national and provincial economic planning, geohazard monitoring, geological survey, mineral resources exploration as well as macro decision-making.
DataCite Commons 收录
中国区域地面气象要素驱动数据集 v2.0(1951-2020)
中国区域地面气象要素驱动数据集(China Meteorological Forcing Data,以下简称 CMFD)是为支撑中国区域陆面、水文、生态等领域研究而研发的一套高精度、高分辨率、长时间序列数据产品。本页面发布的 CMFD 2.0 包含了近地面气温、气压、比湿、全风速、向下短波辐射通量、向下长波辐射通量、降水率等气象要素,时间分辨率为 3 小时,水平空间分辨率为 0.1°,时间长度为 70 年(1951~2020 年),覆盖了 70°E~140°E,15°N~55°N 空间范围内的陆地区域。CMFD 2.0 融合了欧洲中期天气预报中心 ERA5 再分析数据与气象台站观测数据,并在辐射、降水数据产品中集成了采用人工智能技术制作的 ISCCP-ITP-CNN 和 TPHiPr 数据产品,其数据精度较 CMFD 的上一代产品有显著提升。 CMFD 历经十余年的发展,其间发布了多个重要版本。2019 年发布的 CMFD 1.6 是完全采用传统数据融合技术制作的最后一个 CMFD 版本,而本次发布的 CMFD 2.0 则是 CMFD 转向人工智能技术制作的首个版本。此版本与 1.6 版具有相同的时空分辨率和基础变量集,但在其它诸多方面存在大幅改进。除集成了采用人工智能技术制作的辐射和降水数据外,在制作 CMFD 2.0 的过程中,研发团队尽可能采用单一来源的再分析数据作为输入并引入气象台站迁址信息,显著缓解了 CMFD 1.6 中因多源数据拼接和气象台站迁址而产生的虚假气候突变。同时,CMFD 2.0 数据的时间长度从 CMFD 1.6 的 40 年大幅扩展到了 70 年,并将继续向后延伸。CMFD 2.0 的网格空间范围虽然与 CMFD 1.6 相同,但其有效数据扩展到了中国之外,能够更好地支持跨境区域研究。为方便用户使用,CMFD 2.0 还在基础变量集之外提供了若干衍生变量,包括近地面相对湿度、雨雪分离降水产品等。此外,CMFD 2.0 摒弃了 CMFD 1.6 中通过 scale_factor 和 add_offset 参数将实型数据化为整型数据的压缩技术,转而直接将实型数据压缩存储于 NetCDF4 格式文件中,从而消除了用户使用数据时进行解压换算的困扰。 本数据集原定版本号为 1.7,但鉴于本数据集从输入数据到研制技术都较上一代数据产品有了大幅的改变,故将其版本号重新定义为 2.0。CMFD 2.0 的数据内容与此前宣传的 CMFD 1.7 基本一致,仅对 1983 年 7 月以后的向下短/长波辐射通量数据进行了更新,以修正其长期趋势存在的问题。2021 年至 2024 年的 CMFD 数据正在制作中,计划于 2025 年上半年发布,从而使 CMFD 2.0 延伸至 2024 年底。
国家青藏高原科学数据中心 收录
HazyDet
HazyDet是由解放军工程大学等机构创建的一个大规模数据集,专门用于雾霾场景下的无人机视角物体检测。该数据集包含383,000个真实世界实例,收集自自然雾霾环境和正常场景中人工添加的雾霾效果,以模拟恶劣天气条件。数据集的创建过程结合了深度估计和大气散射模型,确保了数据的真实性和多样性。HazyDet主要应用于无人机在恶劣天气条件下的物体检测,旨在提高无人机在复杂环境中的感知能力。
arXiv 收录