omi-health/medical-dialogue-to-soap-summary
收藏Hugging Face2024-08-01 更新2024-05-18 收录
下载链接:
https://hf-mirror.com/datasets/omi-health/medical-dialogue-to-soap-summary
下载链接
链接失效反馈官方服务:
资源简介:
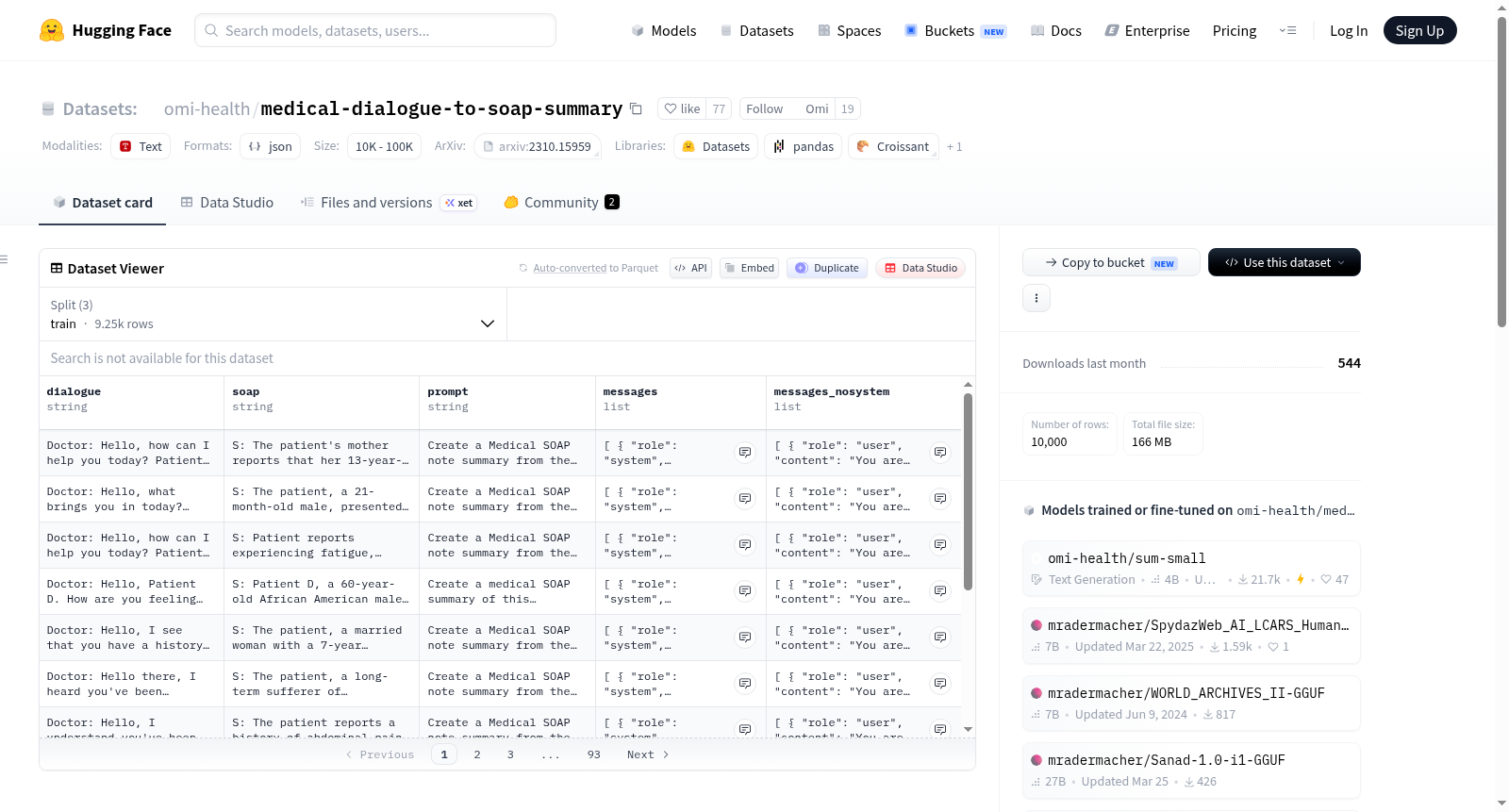
该数据集包含10,000个合成的医患对话,这些对话基于PubMed Central (PMC)的病例报告,使用GPT-4模型生成。每个对话都配有SOAP摘要。数据集分为9250个训练样本、500个验证样本和250个测试样本,每个样本包含对话列、SOAP列、提示列和ChatML风格的对话格式列。
This dataset contains 10,000 synthesized doctor-patient dialogues, which were generated using the GPT-4 model based on case reports sourced from PubMed Central (PMC). Each dialogue is paired with a SOAP summary. The dataset is divided into 9250 training samples, 500 validation samples, and 250 test samples. Each sample includes four columns: dialogue column, SOAP summary column, prompt column, and ChatML-style dialogue format column.
提供机构:
omi-health
原始信息汇总
数据集概述:合成医疗对话与SOAP摘要
数据集描述
摘要
本数据集包含10,000个合成的患者与临床医生之间的对话,这些对话基于NoteChat的GPT-4数据集,源自PubMed Central(PMC)的病例报告。伴随这些对话的是通过GPT-4生成的SOAP摘要。数据集分为9250个训练样本、500个验证样本和250个测试样本,每个样本包含对话列、SOAP列、提示列和ChatML风格的对话格式列。
数据分割
- 训练集:9250
- 验证集:500
- 测试集:250
数据集访问
该数据集在特定条件下可用:
- 使用许可:任何目的,无论是商业用途还是其他,均可由Omi提供,但需获得NoteChat数据集原作者的进一步使用许可。
使用数据集
该数据集适用于自然语言理解、对话生成和医疗文档自动化等任务。其结构特别有助于开发能够生成和理解临床对话及其摘要形式的AI模型。然而,请注意,对话和摘要是合成生成的,未经适当的安全措施和验证,不应用于直接的临床应用。
搜集汇总
数据集介绍
构建方式
本数据集基于PubMed Central(PMC)病例报告,利用GPT-4模型从NoteChat数据集中合成生成,包含10,000条患者与临床医生之间的模拟对话。每条对话均配有由GPT-4生成的SOAP格式摘要,以结构化方式呈现主观信息、客观数据、评估与计划。数据集划分为训练集9,250条、验证集500条及测试集250条,每条记录涵盖对话文本、SOAP摘要、提示词及ChatML格式的对话序列,为医疗对话与临床文档自动化的研究提供了标准化资源。
使用方法
该数据集可直接加载用于训练和评估自然语言处理模型,特别是在医疗领域中的对话理解与摘要生成任务。用户可通过HuggingFace数据集库轻松访问,利用其预定义的数据划分(训练、验证、测试)进行模型开发。数据集中的ChatML格式对话序列便于微调对话系统,而SOAP摘要列则适合监督学习下的文本生成任务。需注意,由于数据为合成生成,不适用于直接临床决策,应在适当护栏与验证下用于研究目的。
背景与挑战
背景概述
在临床信息学领域,将非结构化的医患对话转化为结构化医疗记录是提升诊疗效率与数据可及性的关键任务。SOAP(主观、客观、评估、计划)摘要作为国际通用的临床文档标准,其自动化生成面临着语义理解与领域知识融合的双重挑战。该数据集由Omi团队于2024年基于NoteChat的GPT-4合成对话创建,依托PubMed Central病例报告构建了10,000条医患对话及对应SOAP摘要。其核心研究问题在于探索大语言模型在医学对话理解与结构化摘要生成中的潜力,为医疗文档自动化提供了标准化训练资源,对推动临床自然语言处理研究具有重要价值。
当前挑战
数据集面临的核心挑战包括:其一,医患对话的领域复杂性——临床交流涉及专业术语、模糊表述与隐含诊断线索,模型需精准捕捉症状、体征与诊疗意图的关联,这对自然语言理解能力提出极高要求。其二,合成数据的真实性局限——所有对话与摘要均由GPT-4生成,缺乏真实临床语境中的歧义性、情感交互与决策不确定性,导致模型在真实场景中的泛化能力存疑。其三,构建过程的技术瓶颈——从NoteChat病例报告到对话的转换依赖提示工程,需平衡临床准确性、对话自然度与SOAP结构完整性,而当前合成流程缺乏多轮专家验证,可能引入知识偏差与格式错误。
常用场景
经典使用场景
该数据集最经典的使用场景聚焦于医疗对话的自动化理解与结构化摘要生成。通过提供10,000组医患对话及其对应的SOAP(主观、客观、评估、计划)格式摘要,研究者可借此训练与评估大语言模型在临床信息抽取与语义压缩方面的能力。具体而言,模型需从自由形式的医患交互中精准识别关键临床要素,并将其重组为逻辑分明的结构化文档,这不仅考验模型对医学领域术语的掌握,更要求其具备跨句推理与信息归约的智慧。
解决学术问题
在学术研究层面,该数据集直面临床自然语言处理中的两大核心挑战:非结构化对话的结构化解析与合成数据的可靠性验证。传统医疗文本摘要任务多基于规整的电子病历,而真实临床对话充斥着口语化表达、信息冗余与话题跳跃,使得从对话到SOAP摘要的转换成为亟需攻克的难题。该数据集通过GPT-4生成的合成样本,为构建鲁棒的端到端摘要模型提供了训练基准,并推动了零样本或少样本学习范式在医疗领域的探索,其意义在于降低了对昂贵且隐私敏感的真实临床数据的依赖。
实际应用
在实际应用层面,该数据集赋能了临床文档自动生成系统的研发,有望显著减轻医务人员的文书负担。基于该数据集训练的模型可被集成至电子健康记录系统,实时将门诊对话转化为标准化SOAP笔记,从而提升诊疗效率并减少人为录入错误。此外,该资源还可用于开发智能问诊辅助工具,在医患交流过程中动态生成结构化的临床摘要,为后续决策支持提供可靠的信息基石,但其合成数据的性质也警示着部署前必须经过严格的本地化验证与安全护栏设置。
数据集最近研究
最新研究方向
在医疗人工智能领域,临床对话与结构化医疗文档的自动生成正成为前沿热点。该数据集利用GPT-4基于PubMed Central病例报告合成医患对话及SOAP摘要,为自然语言理解与医疗文档自动化提供了关键资源。当前研究聚焦于如何通过大规模合成数据训练模型,以提升临床对话理解、摘要生成及电子病历自动填充的准确性。该数据集推动了少样本学习与零样本泛化在医疗场景的应用,其合成性质虽需谨慎验证,但为降低真实数据获取成本、加速AI辅助诊疗系统开发提供了重要支撑,尤其在应对临床工作负载与医疗信息标准化方面具有深远影响。
以上内容由遇见数据集搜集并总结生成


