Sign Language MNIST
收藏www.kaggle.com2017-10-20 更新2025-03-24 收录
下载链接:
https://www.kaggle.com/datamunge/sign-language-mnist
下载链接
链接失效反馈官方服务:
资源简介:
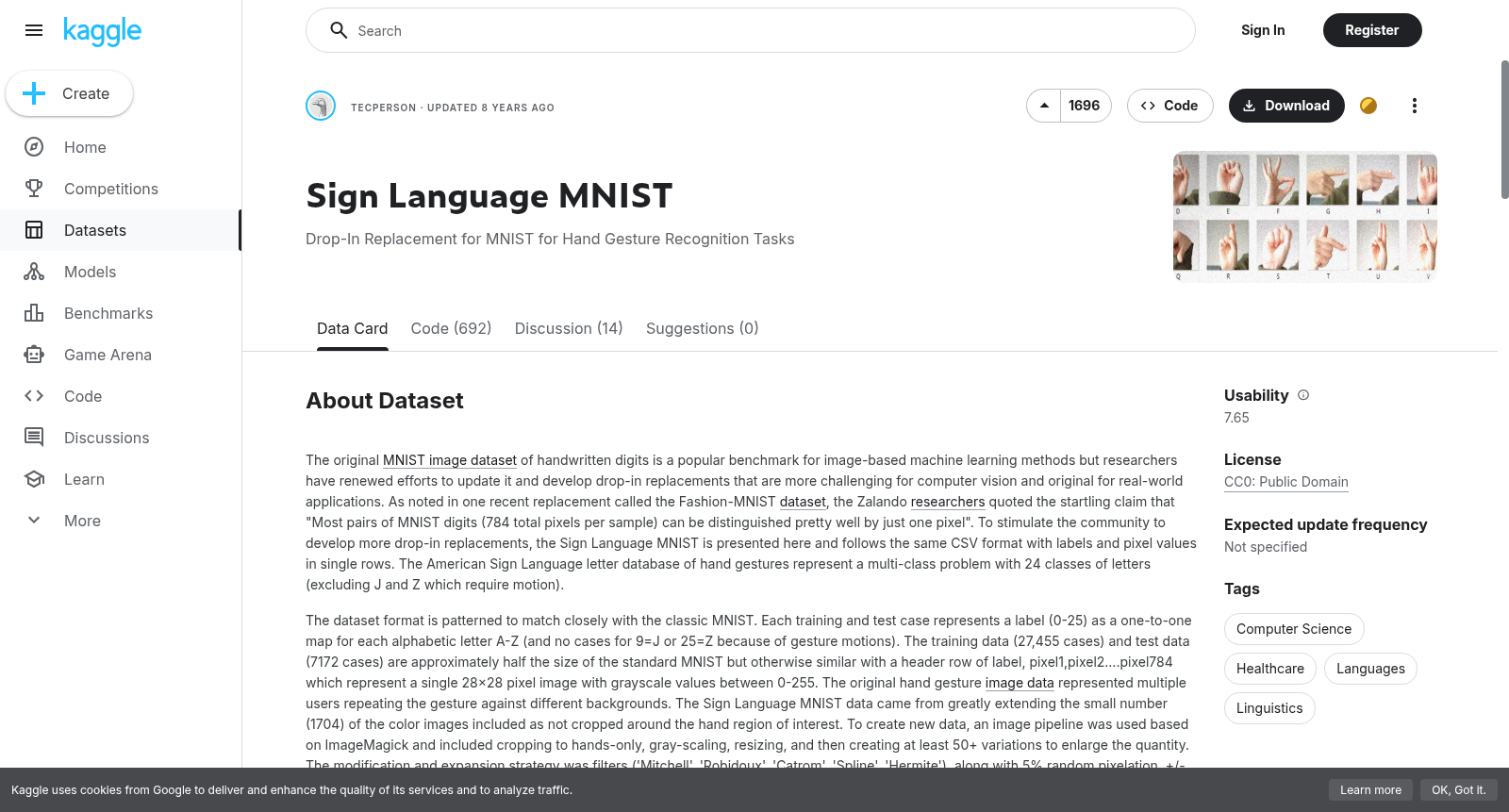
The original [MNIST image dataset][1] of handwritten digits is a popular benchmark for image-based machine learning methods but researchers have renewed efforts to update it and develop drop-in replacements that are more challenging for computer vision and original for real-world applications. As noted in one recent replacement called the Fashion-MNIST [dataset][2], the Zalando [researchers][3] quoted the startling claim that "Most pairs of MNIST digits (784 total pixels per sample) can be distinguished pretty well by just one pixel". To stimulate the community to develop more drop-in replacements, the Sign Language MNIST is presented here and follows the same CSV format with labels and pixel values in single rows. The American Sign Language letter database of hand gestures represent a multi-class problem with 24 classes of letters (excluding J and Z which require motion).
The dataset format is patterned to match closely with the classic MNIST. Each training and test case represents a label (0-25) as a one-to-one map for each alphabetic letter A-Z (and no cases for 9=J or 25=Z because of gesture motions). The training data (27,455 cases) and test data (7172 cases) are approximately half the size of the standard MNIST but otherwise similar with a header row of label, pixel1,pixel2....pixel784 which represent a single 28x28 pixel image with grayscale values between 0-255. The original hand gesture [image data][4] represented multiple users repeating the gesture against different backgrounds. The Sign Language MNIST data came from greatly extending the small number (1704) of the color images included as not cropped around the hand region of interest. To create new data, an image pipeline was used based on ImageMagick and included cropping to hands-only, gray-scaling, resizing, and then creating at least 50+ variations to enlarge the quantity. The modification and expansion strategy was filters ('Mitchell', 'Robidoux', 'Catrom', 'Spline', 'Hermite'), along with 5% random pixelation, +/- 15% brightness/contrast, and finally 3 degrees rotation. Because of the tiny size of the images, these modifications effectively alter the resolution and class separation in interesting, controllable ways.
This dataset was inspired by the Fashion-MNIST [2] and the machine learning pipeline for gestures by Sreehari [4].
A robust visual recognition algorithm could provide not only new benchmarks that challenge modern machine learning methods such as Convolutional Neural Nets but also could pragmatically help the deaf and hard-of-hearing better communicate using computer vision applications. The National Institute on Deafness and other Communications Disorders (NIDCD) indicates that the 200-year-old American Sign Language is a complete, complex language (of which letter gestures are only part) but is the primary language for many deaf North Americans. ASL is the leading minority language in the U.S. after the "big four": Spanish, Italian, German, and French. One could implement computer vision in an inexpensive board computer like Raspberry Pi with OpenCV, and some Text-to-Speech to enabling improved and automated translation applications.
[1]: https://en.wikipedia.org/wiki/MNIST_database
[2]: https://github.com/zalandoresearch/fashion-mnist
[3]: https://arxiv.org/abs/1708.07747
[4]: https://github.com/mon95/Sign-Language-and-Static-gesture-recognition-using-sklearn
原始的手写数字[MNIST图像数据集][1]是图像机器学习方法的一个流行基准,但研究人员们不断努力更新它,并开发出更具挑战性的替代品,这些替代品更符合计算机视觉和现实世界的应用。正如最近一个名为Fashion-MNIST[数据集][2]的替代品所述,Zalando[研究人员][3]提出了惊人的论断:“大多数MNIST数字对(每个样本784个总像素)可以通过仅一个像素来区分得相当好”。为了激发社区开发更多替代品,此处推出了手语MNIST数据集,它遵循相同的CSV格式,每行包含标签和像素值。美国手语手势字母数据库代表了多类问题,有24个字母类别(不包括需要动作的J和Z)。
该数据集的格式与经典的MNIST紧密匹配。每个训练和测试案例代表一个标签(0-25),作为每个字母A-Z(以及9=J或25=Z因手势动作而不存在)的一对一映射。训练数据(27,455个案例)和测试数据(7,172个案例)的大小约为标准MNIST的一半,但在其他方面相似,包含一个标题行,标签、像素1、像素2……像素784,这些代表了一个单张28x28像素图像的灰度值,介于0-255之间。原始手势图像数据[4]代表了多个用户在不同背景上重复手势。手语MNIST数据通过大量扩展包括的少量(1704)彩色图像,而没有围绕感兴趣的手部区域裁剪来创建。为了创建新的数据,使用了基于ImageMagick的图像处理管道,包括裁剪至仅手部、灰度化、调整大小,然后创建至少50+种变化以增加数量。修改和扩展策略包括使用滤波器('Mitchell'、'Robidoux'、'Catrom'、'Spline'、'Hermite'),以及5%的随机像素化、±15%的亮度和对比度调整,最后旋转3度。由于图像尺寸较小,这些修改有效地以有趣且可控的方式改变了分辨率和类别分离。
此数据集受到了Fashion-MNIST[2]和Sreehari[4]的机器学习手势管道的启发。
一个稳健的视觉识别算法不仅能提供挑战现代机器学习方法(如卷积神经网络)的新基准,而且还能实际帮助听障人士和听力受损者更好地通过计算机视觉应用进行沟通。美国聋人及交流障碍国家研究所(NIDCD)指出,有着200年历史的美国手语是一种完整、复杂的语言(其中字母手势只是其中一部分),但却是许多北美聋人的主要语言。ASL是美国在“大四”(西班牙语、意大利语、德语和法语)之后的领先少数语言。人们可以在像Raspberry Pi这样的低成本板计算机上实现计算机视觉,并使用一些文本到语音技术,从而实现改进和自动化的翻译应用。
提供机构:
www.kaggle.com
搜集汇总
数据集介绍
背景与挑战
背景概述
Sign Language MNIST是一个用于手语字母识别的数据集,包含24个类别的美国手语字母图像,格式与MNIST相同,适用于图像分类任务。数据集通过扩展和修改原始图像生成,增加了数据多样性和数量,旨在为计算机视觉研究提供更具挑战性的基准。
以上内容由遇见数据集搜集并总结生成


