DocLayNet-v1.2
收藏Hugging Face2025-02-10 更新2025-02-11 收录
下载链接:
https://huggingface.co/datasets/ds4sd/DocLayNet-v1.2
下载链接
链接失效反馈官方服务:
资源简介:
DocLayNet数据集是一个扩展自原始DocLayNet的数据集,它将文档图像的PDF文件嵌入到一个二进制列中。该数据集为80863个独立页面的6个文档类别提供了逐页布局分割的地面真实值,使用边界框标注了11个不同的类别标签。与相关工作如PubLayNet或DocBank相比,它提供了许多独特的特性,包括人工注释、大量的布局变化、详细的标签集、冗余注释和预定义的训练、测试和验证集。
The DocLayNet dataset is an extended variant of the original DocLayNet, which embeds PDF files of document images into a binary column. This dataset provides page-wise layout segmentation ground truth for 6 document categories across 80,863 independent pages, with 11 distinct category labels annotated using bounding boxes. Compared with related works such as PubLayNet or DocBank, it offers numerous unique features, including human annotations, abundant layout variations, a detailed label set, redundant annotations, and predefined training, test, and validation sets.
创建时间:
2025-02-07
原始信息汇总
DocLayNet v1.2 数据集概述
数据集特征
- image: 页面图片 (PIL image)
- bboxes: 布局边框盒列表
- category_id: 边框盒对应的类别 ID 列表
- segmentation: 布局分割多边形列表
- area: 边框盒的面积
- pdf_cells: 每个 bboxes 内的 PDF 单元内容列表
- metadata: 页面和文档的元数据信息
- pdf: 原始 PDF 图像的二进制 blob
- modalities: 数据模态序列
数据集结构
- ** Homepage**: DocLayNet 主页
- Repository: DocLayNet 代码仓库
- Paper: DocLayNet 论文
数据集总结
DocLayNet 是原始 DocLayNet 数据集的扩展,其中包含文档图像的 PDF 文件作为一个二进制列。该数据集为 80863 个独立页面的 6 个文档类别提供逐页布局分割的地面真实值,使用边框盒标注 11 个不同的类别标签。
类别标签
- 1: Caption
- 2: Footnote
- 3: Formula
- 4: List-item
- 5: Page-footer
- 6: Page-header
- 7: Picture
- 8: Section-header
- 9: Table
- 10: Text
- 11: Title
文档类别
- financial_reports
- scientific_articles
- laws_and_regulations
- government_tenders
- manuals
- patents
数据划分
- train: 35626146180.25 字节,69375 个样本
- validation: 3090589267.941 字节,6489 个样本
- test: 2529339432.131 字节,4999 个样本
数据集大小
- 下载大小: 39770621829 字节
- 数据集大小: 41246074880.322 字节
数据配置
- config_name: default
- train: data/train-*
- validation: data/validation-*
- test: data/test-*
搜集汇总
数据集介绍
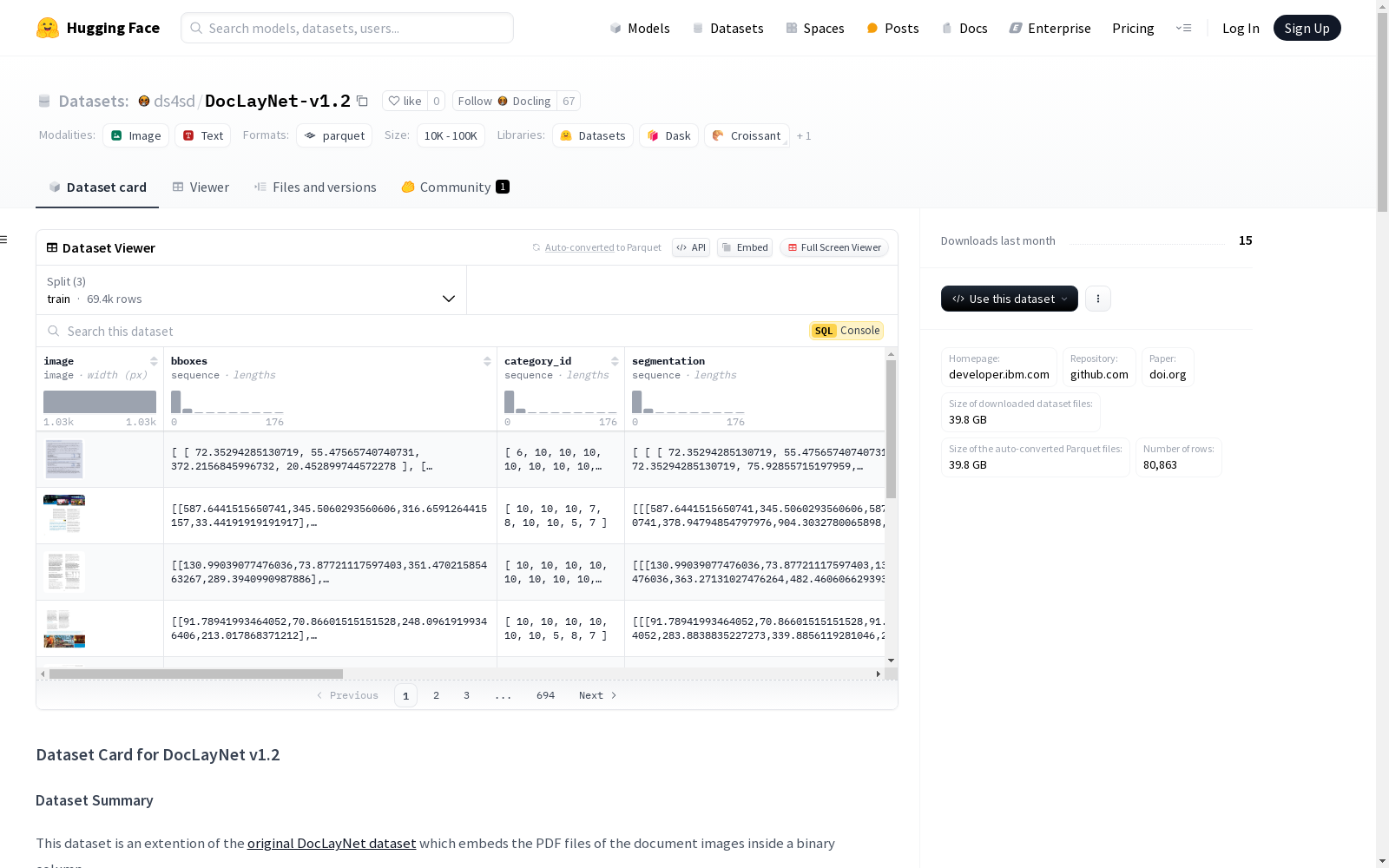
构建方式
DocLayNet-v1.2数据集的构建,是基于对文档图像的PDF文件进行逐页布局分割的标注。该数据集涵盖了80863个独立页面的6种文档类别,由训练有素的专家手工标注,确保了布局分割的金标准。数据集包括图像、边界框、类别ID、分割多边形、区域、PDF单元格、页面和文档元数据以及原始PDF图像的二进制大对象,从而为机器学习模型提供了丰富的训练和测试素材。
特点
该数据集的特点在于:一是采用了人工标注,确保了标注质量;二是包含了大量布局风格多样的文档,覆盖了金融报告、科技文章、法律法规等多种类别;三是定义了11个详细的类别标签,以区分布局特征;四是部分页面进行了多次标注,有助于估计标注不确定性;五是预先定义了训练集、验证集和测试集,确保了类别标签的均衡分布。
使用方法
使用该数据集时,用户可以从HuggingFace的存储库中下载相应的训练、验证和测试数据文件。数据集的结构包含多个字段,如页面图像、布局边界框、类别ID等,用户可以根据自己的需求对这些字段进行读取和解析。此外,数据集还提供了固定的数据划分,以帮助研究人员和开发者进行有效的模型训练和评估。
背景与挑战
背景概述
DocLayNet-v1.2数据集,作为原始DocLayNet数据集的扩展版本,旨在为文档图像布局分析领域提供更加丰富的资源。该数据集由IBM Research的Deep Search团队于2022年创建,并通过精心训练的专家手工标注,为11个不同类别的布局特征提供了逐页的边界框标注。其涵盖了来自金融报告、科技文章、法律法规、政府招标书、手册和专利等六个文档类别的80863个独立页面的多样化复杂布局。DocLayNet-v1.2数据集以其详尽的标签集合、高变性的布局样式、以及预定义的训练集、验证集和测试集,对相关研究领域产生了显著影响。
当前挑战
在构建DocLayNet-v1.2数据集的过程中,研究人员面临了多方面的挑战。首先,手工标注过程需要高度精确,确保每个布局元素被正确分类,这对标注员的训练和标注一致性提出了严格要求。其次,数据集的构建需要处理大规模的文档,并确保不同来源的文档在数据集中得到均衡的代表性。此外,数据集的多样化特性要求算法能够适应广泛变化的布局样式,这为后续的自动布局分析带来了额外的技术挑战。
常用场景
经典使用场景
在文档布局分析领域,DocLayNet-v1.2数据集的经典使用场景主要在于提供精细化的文档布局分割标注,通过其包含的11种不同类别的布局标注,为研究者提供了一个评估和训练布局分割模型的基准。
实际应用
在实际应用中,DocLayNet-v1.2数据集可用于改进文档解析系统,如自动提取科学文章中的表格、公式或标题等特定布局元素,从而提高信息检索和文档理解的自动化水平。
衍生相关工作
基于DocLayNet-v1.2数据集,研究者们已经衍生出了一系列相关工作,包括但不限于改进文档布局分析算法、评估不同标注策略对模型性能的影响,以及探索多模态文档理解的新方法。
以上内容由遇见数据集搜集并总结生成


