KRAFTON/Raon-OpenTTS-Pool
收藏Hugging Face2026-04-02 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/KRAFTON/Raon-OpenTTS-Pool
下载链接
链接失效反馈官方服务:
资源简介:
---
license: other
license_name: mixed-per-dataset
license_link: LICENSE
language:
- en
tags:
- text-to-speech
- tts
- speech
- audio
- open-data
- training-data
- english
task_categories:
- text-to-speech
pretty_name: Raon-OpenTTS-Pool
size_categories:
- 100M<n<1B
configs:
- config_name: all
data_files:
- split: pool
path: "*/metadata_pool.parquet"
- split: core
path: "*/metadata_core.parquet"
- config_name: Raon-YouTube-Commons
data_files:
- split: pool
path: Raon-YouTube-Commons/metadata_pool.parquet
- split: core
path: Raon-YouTube-Commons/metadata_core.parquet
- config_name: Emilia-YODAS2
data_files:
- split: pool
path: Emilia-YODAS2/metadata_pool.parquet
- split: core
path: Emilia-YODAS2/metadata_core.parquet
- config_name: Emilia
data_files:
- split: pool
path: Emilia/metadata_pool.parquet
- split: core
path: Emilia/metadata_core.parquet
- config_name: LibriHeavy
data_files:
- split: pool
path: LibriHeavy/metadata_pool.parquet
- split: core
path: LibriHeavy/metadata_core.parquet
- config_name: HiFiTTS
data_files:
- split: pool
path: HiFiTTS/metadata_pool.parquet
- split: core
path: HiFiTTS/metadata_core.parquet
- config_name: VoxPopuli
data_files:
- split: pool
path: VoxPopuli/metadata_pool.parquet
- split: core
path: VoxPopuli/metadata_core.parquet
- config_name: PeoplesSpeech-Clean
data_files:
- split: pool
path: PeoplesSpeech-Clean/metadata_pool.parquet
- split: core
path: PeoplesSpeech-Clean/metadata_core.parquet
- config_name: PeoplesSpeech-Dirty
data_files:
- split: pool
path: PeoplesSpeech-Dirty/metadata_pool.parquet
- split: core
path: PeoplesSpeech-Dirty/metadata_core.parquet
- config_name: LibriTTS-R
data_files:
- split: pool
path: LibriTTS-R/metadata_pool.parquet
- split: core
path: LibriTTS-R/metadata_core.parquet
- config_name: SPGISpeech2-Cut
data_files:
- split: pool
path: SPGISpeech2-Cut/metadata_pool.parquet
- split: core
path: SPGISpeech2-Cut/metadata_core.parquet
---
# Raon-OpenTTS-Pool
<div align="center">
<img class="block dark:hidden" src="assets/Raon-OpenTTS-Gradient-Black.png" alt="RAON-OpenTTS" width="600">
<img class="hidden dark:block" src="assets/Raon-OpenTTS-Gradient-White.png" alt="RAON-OpenTTS" width="600">
</div>
<p align="center">
<a href="https://www.krafton.ai/ko/"><img src="https://img.shields.io/badge/Homepage-KRAFTON%20AI-blue?style=flat&logo=google-chrome&logoColor=white" alt="Homepage"></a>
<a href="https://github.com/krafton-ai/RAON-OpenTTS"><img src="https://img.shields.io/badge/GitHub-RAON--OpenTTS-white?style=flat&logo=github&logoColor=black" alt="GitHub"></a>
<a href="https://huggingface.co/KRAFTON"><img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-KRAFTON-yellow?style=flat" alt="Hugging Face"></a>
<a href="https://x.com/Krafton_AI"><img src="https://img.shields.io/badge/X-KRAFTON%20AI-white?style=flat&logo=x&logoColor=black" alt="X"></a>
<a href="#license"><img src="https://img.shields.io/badge/License-Mixed%20(see%20below)-lightgrey?style=flat" alt="License"></a>
</p>
<p align="center">
Technical Report (Coming soon)
</p>
**Raon-OpenTTS-Pool** is a large-scale open English speech corpus for text-to-speech (TTS) training,
constructed from 8 publicly available speech corpora and a set of web-sourced recordings.
It is the training data behind [RAON-OpenTTS](https://github.com/krafton-ai/RAON-OpenTTS),
an open TTS model that performs on par with state-of-the-art closed-data systems.
- **615K hours** of speech audio
- **239.7M** speech segments
- **11 source datasets** aggregated into a unified format
- All audio stored as **16 kHz mono Opus (64 kbps)** in [WebDataset](https://github.com/webdataset/webdataset) tar shards
We restrict data sources to publicly available English speech datasets with more than 500 hours of audio.
All speech segments are limited to **30 seconds or shorter** to reduce alignment errors, multi-speaker content, and non-speech artifacts.
Existing public datasets (LibriHeavy, Emilia, VoxPopuli, etc.) are included as-is without modification,
with audio standardized to 16 kHz mono Opus 64 kbps for storage efficiency.
The Raon-YouTube-Commons portion is reconstructed from [YouTube-Commons](https://huggingface.co/datasets/PleIAs/YouTube-Commons)
through a dedicated preprocessing pipeline (see [below](#raon-youtube-commons)).
With a model-based filtering pipeline applied to Raon-OpenTTS-Pool, we derive
**Raon-OpenTTS-Core**, a curated high-quality subset of **510.1K hours** and **194.5M** segments.
For more details, see our paper: [Raon-OpenTTS: Open Models and Data for Robust Text-to-Speech](https://github.com/krafton-ai/RAON-OpenTTS)
## Format
Each WebDataset tar shard contains pairs of files per sample:
```
{sample_key}.opus # 16 kHz mono Opus 64 kbps audio
{sample_key}.json # {"text": "...", "duration": 8.42, "source": "..."}
```
> **Note:** The dataset viewer shows metadata only (sample_key, text, duration, shard_name).
> Audio is stored in WebDataset tar files — see [Usage](#usage) below to download and load audio.
## Splits
Each dataset config has two metadata splits:
- **pool** — all samples (sample_key, text, duration, shard_name)
- **core** — quality-filtered subset (**Raon-OpenTTS-Core**), retaining ~85% of the data
### Raon-OpenTTS-Core Filtering
Raon-OpenTTS-Core is constructed by applying three model-based quality filters and removing the bottom 15% of samples by combined score:
1. **WER-based**: Transcribe each segment with Whisper-small ASR and compute WER against the existing text annotation. Samples with excessively high WER (> 0.35) indicate severe transcription mismatches.
2. **DNSMOS-based**: Estimate perceptual speech quality using DNSMOS. Samples below 2.24 indicate strong background noise or distortion.
3. **VAD-based**: Estimate speech activity ratio (SAR) using Silero VAD. Samples with SAR below 0.79 are dominated by silence, music, or non-speech audio.
4. **Combined**: Compute an absolute rank for each segment along each criterion (DNSMOS, WER, SAR) and average the ranks into a single combined score. Segments falling below the 15th percentile are discarded.
This combined filtering achieves the best overall TTS performance across diverse evaluation benchmarks (see paper, Figure 3).
## Available Datasets
| Dataset | Source | Size (h) | Avg. Dur. (s) | Segments (M) | Tars | License | DNSMOS | WER | SAR |
|---|---|---|---|---|---|---|---|---|---|
| **Raon-YouTube-Commons** | [YouTube-Commons](https://huggingface.co/datasets/PleIAs/YouTube-Commons) | 335k | 8.5 | 141.70 | 1,017 | CC BY 4.0 | 2.74 | 0.30 | 0.90 |
| **Emilia-YODAS2** | [Emilia](https://huggingface.co/datasets/amphion/Emilia-Dataset) | 92k | 9.2 | 35.97 | 287 | CC BY-NC 4.0 | 2.82 | 0.19 | 0.90 |
| **Emilia** | [Emilia](https://huggingface.co/datasets/amphion/Emilia-Dataset) | 47k | 9.3 | 18.14 | 145 | CC BY 4.0 | 3.02 | 0.18 | 0.89 |
| **LibriHeavy** | [LibriHeavy](https://github.com/k2-fsa/libriheavy) | 42k | 14.2 | 10.77 | 127 | Public Domain | 3.22 | 0.11 | 0.83 |
| **HiFiTTS** | [HiFiTTS2](https://www.openslr.org/hifitts/) | 37k | 10.1 | 13.09 | 109 | CC BY 4.0 | 3.20 | 0.11 | 0.84 |
| **PeoplesSpeech-Dirty** | [People's Speech](https://huggingface.co/datasets/MLCommons/peoples_speech) | 28k | 14.2 | 5.48 | 63 | CC BY 4.0 | 2.63 | 0.25 | 0.86 |
| **VoxPopuli** | [VoxPopuli](https://github.com/facebookresearch/voxpopuli) | 17k | 27.8 | 2.24 | 50 | CC-0 | 2.82 | 0.36 | 0.83 |
| **PeoplesSpeech-Clean** | [People's Speech](https://huggingface.co/datasets/MLCommons/peoples_speech) | 10k | — | 1.50 | 18 | CC BY 4.0 | — | — | — |
| **LibriTTS-R** | [LibriTTS-R](https://www.openslr.org/141/) | 552 | 5.6 | 0.35 | 2 | CC BY 4.0 | 2.96 | 0.06 | 0.91 |
| **SPGISpeech2-Cut** | SPGISpeech 2.0 | 889 | 14.4 | 0.22 | 3 | Kensho UA | 2.72 | 0.08 | 0.90 |
| | | | | | | | | | |
| **Total** | | **615k** | **9.2** | **239.7** | **1,821** | — | 2.83 | 0.24 | 0.89 |
### Raon-YouTube-Commons
A substantial portion of Raon-OpenTTS-Pool (335K hours) is derived from [YouTube-Commons](https://huggingface.co/datasets/PleIAs/YouTube-Commons).
Since the original release provides only YouTube URLs with noisy or unreliable transcriptions,
we reconstructed it into a high-quality speech-text dataset through the following pipeline:
1. **Audio collection**: Download audio from YouTube URLs in the original dataset
2. **Source separation** (UVR-MDX): Suppress background music and non-vocal components
3. **Speaker diarization** (PyAnnote 3.1): Estimate speaker boundaries to ensure single-speaker segments
4. **Voice activity detection** (Silero VAD): Segment continuous speech regions into clips of 3--30 seconds
5. **Automatic transcription** (Whisper-large-v3): Transcribe each segment to obtain aligned speech-text pairs
6. **Standardization**: Resample to 16 kHz mono, encode as 64 kbps Opus
The resulting dataset is released as **Raon-YouTube-Commons** in this repository.
### Non-redistributable Datasets
Two additional datasets used in training cannot be included due to license restrictions.
Users who have agreed to the license on HuggingFace can automatically download and convert them
using `prepare_nonredist_datasets.py`:
| Dataset | Size (h) | License | Source |
|---|---|---|---|
| GigaSpeech | 10k | License agreement required | [speechcolab/gigaspeech](https://huggingface.co/datasets/speechcolab/gigaspeech) |
| SPGISpeech | 5k | Non-commercial (Kensho) | [kensho/spgispeech](https://huggingface.co/datasets/kensho/spgispeech) |
See [Preparing Non-redistributable Datasets](#preparing-non-redistributable-datasets) for instructions.
---
## Usage
### 1. Metadata (pool / core split)
```python
from datasets import load_dataset
# Core metadata for a single dataset
meta = load_dataset("KRAFTON/Raon-OpenTTS-Pool", "Raon-YouTube-Commons", split="core")
# Columns: sample_key, text, duration, shard_name
print(meta[0])
# All datasets combined
all_core = load_dataset("KRAFTON/Raon-OpenTTS-Pool", "all", split="core")
```
### 2. Audio (WebDataset, local tars)
Download tars first:
```python
from huggingface_hub import snapshot_download
local_dir = snapshot_download("KRAFTON/Raon-OpenTTS-Pool", repo_type="dataset",
ignore_patterns=["*.parquet"])
```
Then load with WebDataset:
```python
import webdataset as wds
import json, io, soundfile as sf
dataset = (
wds.WebDataset(f"{local_dir}/LibriTTS-R/lr-{{000000..000001}}.tar")
.to_tuple("opus", "json")
)
for opus_bytes, json_bytes in dataset:
meta = json.loads(json_bytes)
audio, sr = sf.read(io.BytesIO(opus_bytes))
text = meta["text"]
```
### 3. Core-only training
The audio tars contain pool and core samples mixed. To train on core only, filter by sample_key:
```python
import webdataset as wds
from datasets import load_dataset
import json, io, soundfile as sf
# Step 1: load core sample keys from metadata
core_keys = set(
load_dataset("KRAFTON/Raon-OpenTTS-Pool", "LibriTTS-R", split="core")["sample_key"]
)
# Step 2: stream tars, skip non-core samples
dataset = (
wds.WebDataset(f"{local_dir}/LibriTTS-R/lr-{{000000..000001}}.tar")
.select(lambda s: s["__key__"] in core_keys)
.to_tuple("opus", "json")
)
for opus_bytes, json_bytes in dataset:
meta = json.loads(json_bytes)
audio, sr = sf.read(io.BytesIO(opus_bytes))
text = meta["text"]
duration = meta["duration"]
```
---
## Preparing Non-redistributable Datasets
The script `prepare_nonredist_datasets.py` automatically downloads and converts GigaSpeech
and SPGISpeech into the same WebDataset tar + parquet format used by Raon-OpenTTS-Pool.
### Prerequisites
1. **Accept the dataset license** on each HuggingFace dataset page:
- GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
- SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
2. **Set your HuggingFace token** (from an account that has accepted the licenses):
```bash
export HF_TOKEN=hf_your_token_here
```
3. **Install dependencies:**
```bash
pip install "datasets<4.0" soundfile pyarrow numpy tqdm
```
> **Note:** `datasets>=4.0` dropped `soundfile` audio decoding and requires `torchcodec`
> with system FFmpeg libraries. Use `datasets<4.0` (e.g. `datasets==3.5.0`) to avoid this.
4. **ffmpeg** must be in PATH.
### GigaSpeech
```bash
# Download and convert xl subset from HuggingFace Hub
python prepare_nonredist_datasets.py gigaspeech \
--output_dir ./GigaSpeech \
--gigaspeech_subset xl \
--num_workers 16
# Or from a local HF snapshot (no HF_TOKEN needed)
python prepare_nonredist_datasets.py gigaspeech \
--source_dir /path/to/gigaspeech_local \
--output_dir ./GigaSpeech \
--gigaspeech_subset xl
```
Available subsets: `xs` (10h), `s` (250h), `m` (1000h), `l` (2500h), `xl` (10000h)
### SPGISpeech
```bash
# Download and convert L subset from HuggingFace Hub
python prepare_nonredist_datasets.py spgispeech \
--output_dir ./SPGISpeech \
--spgispeech_subset L \
--num_workers 16
# Or from a local HF snapshot (no HF_TOKEN needed)
python prepare_nonredist_datasets.py spgispeech \
--source_dir /path/to/spgispeech_local \
--output_dir ./SPGISpeech \
--num_workers 16
```
Available subsets: `L` (full ~5000h), `M` (~1000h), `S` (~200h), `dev`, `test`
### Output
```
<output_dir>/
{prefix}-000000.tar # WebDataset shard (~10 GB)
{prefix}-000001.tar
...
metadata_pool.parquet # all samples
metadata_core.parquet # = pool (no quality filtering without --core_json)
```
By default `metadata_core.parquet` equals `metadata_pool.parquet` since quality filtering
requires an internal index file. If you have `pool_indices_filter_remove_15pct_combined.json`
from the Raon-OpenTTS maintainers, pass it with `--core_json` to generate a filtered core split.
### Using with RAON-OpenTTS training
Once prepared, pass the output directory as a `nonredist_dirs` entry in the training config:
```yaml
datasets:
nonredist_dirs:
- /path/to/GigaSpeech
- /path/to/SPGISpeech
```
---
## License
**This repository contains data from multiple sources, each with its own license.**
Users must comply with the license of each individual sub-dataset they use.
| Dataset | License | Commercial Use |
|---|---|---|
| Raon-YouTube-Commons | [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) | Yes |
| Emilia | [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) | Yes |
| **Emilia-YODAS2** | **[CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/)** | **No** |
| LibriHeavy | Public Domain (LibriVox) | Yes |
| HiFiTTS | [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) | Yes |
| PeoplesSpeech-Clean / Dirty | [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) | Yes |
| VoxPopuli | [CC-0](https://creativecommons.org/publicdomain/zero/1.0/) | Yes |
| LibriTTS-R | [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) | Yes |
| SPGISpeech2-Cut | [Kensho User Agreement](https://huggingface.co/datasets/kensho/spgispeech) | Non-commercial |
| GigaSpeech (non-redist) | [License agreement required](https://huggingface.co/datasets/speechcolab/gigaspeech) | See terms |
| SPGISpeech (non-redist) | [Kensho User Agreement](https://huggingface.co/datasets/kensho/spgispeech) | Non-commercial |
| Metadata and dataset structure | [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) | Yes |
> **Note:** Emilia-YODAS2 and SPGISpeech2-Cut are licensed under non-commercial terms.
> If you require fully commercial-use data, exclude these sub-datasets via the `configs` parameter.
## Citation
```bibtex
@article{raon2026opentts,
title = {Raon-OpenTTS: Open Models and Data for Robust Text-to-Speech},
author = {TBD},
year = {2026},
url = {https://github.com/krafton-ai/Raon-OpenTTS}
}
```
© 2026 KRAFTON
提供机构:
KRAFTON
搜集汇总
数据集介绍
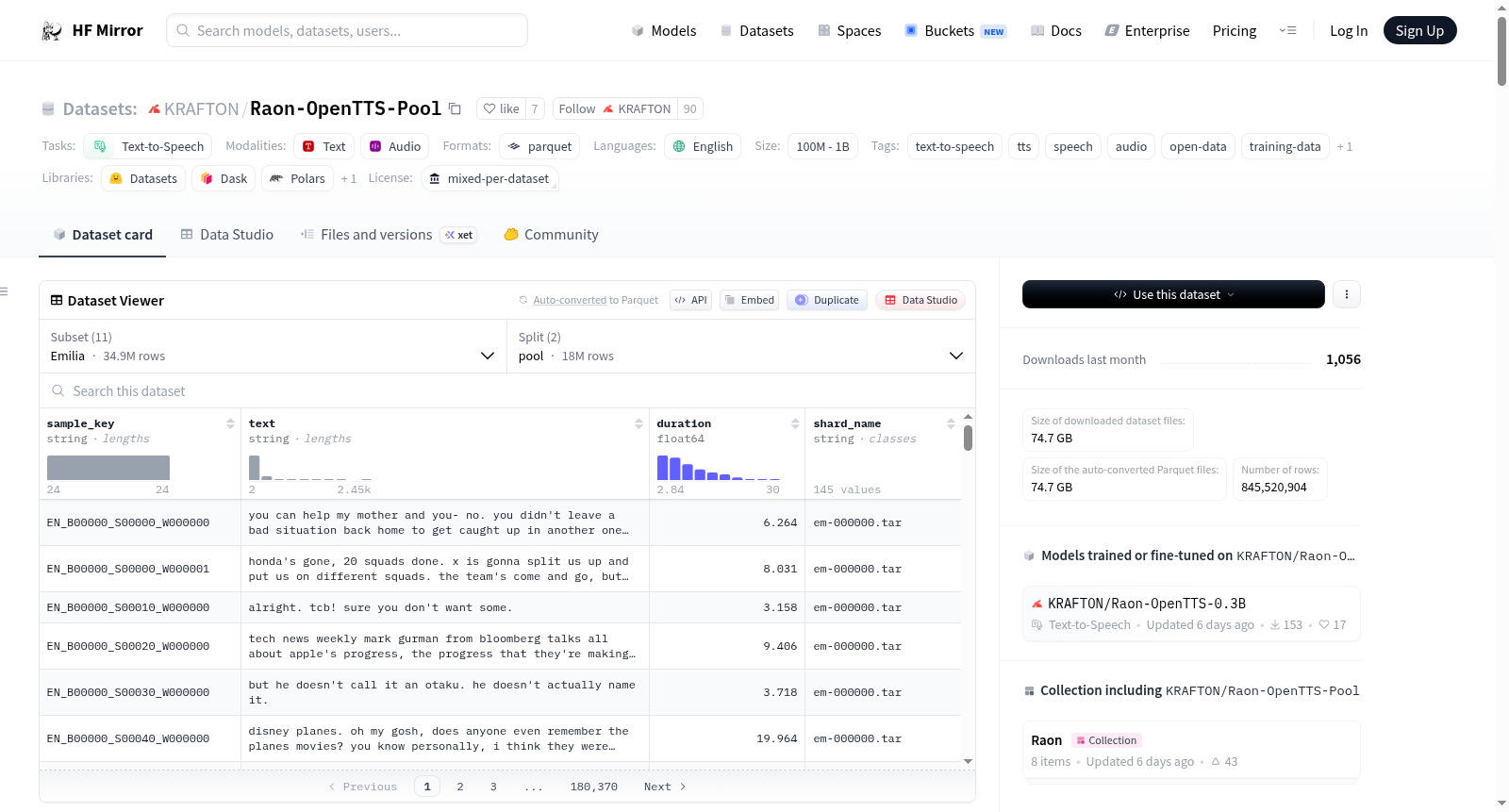
构建方式
在语音合成领域,大规模高质量数据集的构建是推动技术发展的关键基石。Raon-OpenTTS-Pool的构建采用了系统化的集成与标准化策略,其核心在于汇聚了八个公开可用的英语语音语料库及一组网络采集的录音,总计涵盖615千小时的语音音频与2.397亿个语音片段。构建过程中,所有语音片段被限制在30秒以内,以降低对齐误差并减少多说话人内容与非语音伪影的影响。现有公共数据集如LibriHeavy、VoxPopuli等均以原始形式纳入,并通过统一转换为16kHz单声道Opus格式以实现存储效率。特别地,针对YouTube-Commons来源的数据,设计了一套包含源分离、说话人日志、语音活动检测与自动转录的专用预处理流程,从而重构出高质量的Raon-YouTube-Commons子集。
特点
该数据集展现出显著的大规模与高质量并重的特征。其总体规模达到615千小时,为当前公开语音合成数据集中最为庞大的资源之一。数据集通过精心设计的质量过滤流程,衍生出Raon-OpenTTS-Core这一精选子集,保留了约85%的数据,确保了核心训练素材的纯净度。过滤机制融合了基于Whisper的单词错误率评估、DNSMOS的感知语音质量估计以及Silero VAD的语音活动比率分析,通过综合排名剔除质量最低的15%样本。这种多维度过滤策略在多样化的评估基准测试中展现出最优的整体性能。数据集采用WebDataset分片格式存储,每个样本包含音频文件与包含文本、时长及来源的元数据文件,便于高效流式加载与分布式处理。
使用方法
为有效利用该数据集进行模型训练,用户需遵循结构化的数据加载流程。首先,可通过Hugging Face的`datasets`库加载特定子数据集或全部数据集的元数据,这些元数据以Parquet格式提供,包含样本键、文本、时长及分片名称等信息。其次,音频内容存储于WebDataset的tar分片中,需先使用`snapshot_download`下载至本地,再通过`webdataset`库进行流式读取。每个tar分片内,音频以Opus格式存储,对应的JSON文件则提供文本标注。若仅需使用经过质量过滤的Core子集进行训练,可在加载音频流时,依据从元数据中提取的Core样本键集合进行过滤。对于因许可限制未包含在内的GigaSpeech与SPGISpeech数据集,提供了专用脚本,在用户接受相应许可后,可自动下载并转换为与本数据集一致的格式,以便整合训练。
背景与挑战
背景概述
Raon-OpenTTS-Pool是KRAFTON AI于2026年发布的大规模开放英语语音语料库,专为文本到语音(TTS)模型训练而构建。该数据集整合了包括LibriHeavy、Emilia、VoxPopuli在内的11个公开语音数据集,并融合了来自YouTube-Commons的网络音频资源,总计涵盖615千小时的语音音频和239.7百万个语音片段。其核心研究问题在于解决高质量、大规模TTS训练数据的稀缺性,通过统一格式与标准化处理,为开放TTS模型的发展提供了坚实的数据基础,显著推动了语音合成领域向更高效、更鲁棒的方向演进。
当前挑战
Raon-OpenTTS-Pool面临的挑战主要集中于两方面:在领域问题层面,文本到语音任务需应对语音质量、口音多样性、背景噪声抑制以及语音-文本对齐精度等复杂问题,确保合成语音的自然度与清晰度;在构建过程中,数据集整合了多源异构数据,需克服音频格式统一、许可证兼容性管理以及大规模数据预处理的技术障碍,例如通过语音活动检测、说话人分离和自动转录流程来净化网络来源的音频,并应用基于WER、DNSMOS和VAD的模型过滤机制以提取高质量子集,这些步骤均涉及计算资源与算法优化的双重考验。
常用场景
经典使用场景
在语音合成技术领域,大规模高质量训练数据是模型性能的基石。Raon-OpenTTS-Pool作为目前规模最大的公开英语语音语料库之一,其最经典的使用场景是作为端到端神经语音合成模型的训练基础。研究人员利用其超过61.5万小时的语音音频和2.397亿个语音片段,能够训练出具有自然韵律和丰富音色表现力的TTS系统。该数据集特别适用于训练需要海量数据支撑的现代生成式语音模型,如基于Transformer架构或扩散模型的语音合成系统,这些模型通过学习数据集中多样的发音风格和声学特征,能够生成接近人类自然语音的合成结果。
解决学术问题
该数据集有效解决了语音合成研究中长期存在的几个关键学术问题。首先,它通过整合多个公开数据集并实施统一的质量过滤标准,缓解了高质量训练数据稀缺的困境,为研究社区提供了标准化的基准资源。其次,其包含的Raon-OpenTTS-Core子集通过多维度质量筛选机制,为研究数据清洗和样本选择策略提供了实证基础,有助于探索数据质量与模型性能之间的量化关系。更重要的是,该数据集支持开放科学理念,使研究者能够复现和比较不同算法在相同数据条件下的表现,推动了语音合成技术的透明化发展和公平评估体系的建立。
衍生相关工作
该数据集的发布催生了一系列重要的衍生研究工作。最直接的相关成果是RAON-OpenTTS开源模型系列,这些模型在多项基准测试中达到了与闭源商业系统相当的性能水平。研究社区基于该数据集开展了数据高效利用方法的探索,包括少样本适应、零样本语音克隆等前沿方向。在数据质量评估领域,学者们借鉴其过滤管道设计了更精细的语音样本评分体系。跨语言迁移学习研究则利用该英语数据集作为预训练基础,加速低资源语言的语音合成模型开发。这些工作共同构成了当前开放语音合成生态系统的核心组成部分,持续推动着该领域的技术进步。
以上内容由遇见数据集搜集并总结生成


