moukaii/Tuberculosis_Dataset
收藏Hugging Face2024-03-02 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/moukaii/Tuberculosis_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是从原始“MultiCaRe数据集”中筛选出的专注于肺结核患者的多模态数据集,包含肺部计算机断层扫描(CT)影像数据和肺结核患者的临床病例记录,以及病例关键词、CT图像描述、患者ID、性别和年龄信息。数据集支持的任务包括胸部CT图像分割和肺结核分类算法的开发,以及从临床记录中提取医学术语的NLP方法。数据集的语言为英语,数据字段包括case_id、gender、age、case_text、keywords、pics_array和Caption。数据集的初始收集和预处理过程包括从原始MultiCaRe数据集中筛选出与肺结核相关的病例报告、图像和描述,并通过Hugging Face Python脚本进行进一步处理。数据集的社会影响主要体现在提高肺结核诊断的准确性和效率。数据集的偏差、风险和局限性包括选择偏差、技术偏差、解释偏差、隐私和保密风险、数据完整性和质量风险,以及数据质量的局限性。
该数据集是从原始“MultiCaRe数据集”中筛选出的专注于肺结核患者的多模态数据集,包含肺部计算机断层扫描(CT)影像数据和肺结核患者的临床病例记录,以及病例关键词、CT图像描述、患者ID、性别和年龄信息。数据集支持的任务包括胸部CT图像分割和肺结核分类算法的开发,以及从临床记录中提取医学术语的NLP方法。数据集的语言为英语,数据字段包括case_id、gender、age、case_text、keywords、pics_array和Caption。数据集的初始收集和预处理过程包括从原始MultiCaRe数据集中筛选出与肺结核相关的病例报告、图像和描述,并通过Hugging Face Python脚本进行进一步处理。数据集的社会影响主要体现在提高肺结核诊断的准确性和效率。数据集的偏差、风险和局限性包括选择偏差、技术偏差、解释偏差、隐私和保密风险、数据完整性和质量风险,以及数据质量的局限性。
提供机构:
moukaii
原始信息汇总
数据集概述
数据集简介
该数据集是从原始的“The MultiCaRe Dataset”中精心筛选,专注于胸结核患者。这是一个多模态数据集,包含肺部计算机断层扫描(CT)影像数据和结核病患者的临床病例记录,以及病例关键词、CT图像的说明、患者ID、性别和年龄信息。
支持的任务
该数据集可用于:
- 开发胸部CT图像分割和结核阳性或对照分类的算法。
- 开发新的自然语言处理(NLP)方法和无监督机器学习方法,从临床笔记中提取医学术语。
语言
英语
数据结构和实例
数据遵循以下结构: json { "case_id": "PMC10129030_01", "gender": "male", "age": 62, "case_text": "A 62-year-old man presented with acute dyspnea at rest, requiring high-flow…", "keywords": "["dendriform pulmonary ossification", "lung transplant", "pulmonary fibrosis"]", "pics_array": image, "Caption": "coronal. chest CT shows ground-glass and reticular opacities in the dependent…" }
数据字段
- case_id (string): 患者ID,由文章的PMC加上一个顺序号组成。
- gender (string): 患者性别,可以是Female, Male, Transgender或Unknown。
- age (int): 患者年龄,低于1岁的年龄被分配为0。
- case_text (string): 自解释。
- keywords (string): 关键词,有时在文章内容的关键词部分提供。
- pics_array (int): 图像
- Caption (string): 图像说明。
初始数据收集和预处理
- 原始的MultiCaRe Dataset大约9GB,涵盖多种医学专业。为了创建专注于结核病的子集,数据集根据特定标准进行过滤:
- 病例报告选择:选择标准是包含关键词如tuberculosis或tb的报告。
- 说明过滤:进一步过滤包含关键词如ct, lung, 或chest的说明。
- 图像标注:最后,根据标签ct和lung选择图像。
- 在从MultiCaRe Dataset初步过滤后,通过Hugging Face的Python脚本实施额外的处理步骤:
- 排除缺少年龄信息的记录。
- 合并来自不同文件的数据,包括.csv, .JSON和.jpg。
社会影响
精心筛选的结核病患者多模态数据集,从更大的MultiCaRe Dataset中提取,有望在公共卫生和医学研究领域产生重大社会影响。通过促进更精确的CT图像分割和分类算法的开发,以及增强从临床笔记中提取医学术语的自然语言处理(NLP)技术,该数据集有可能提高结核病诊断的准确性和效率。
个人和敏感信息
病例报告设计为公开可访问,因此故意省略任何个人识别细节,以确保患者隐私和保密性。
偏差、风险和局限性
偏差
- 选择偏差:原始的MultiCaRe Dataset是从1990年至2023年的75,382篇开放获取PubMed Central文章中生成的。因此,无法保证从不同人口统计群体中随机抽样的病例。数据可能存在偏差,因为收集过程并不代表更广泛的人口。
- 技术偏差:先进的成像技术可能在所有环境中并不平等可用,导致数据集不成比例地代表来自更好装备设施的患者。这可能使数据集偏向于在更好装备环境中更容易诊断的条件。
- 解释者偏差:对于
"case_text"和"caption",放射科医生或临床医生的专业知识和经验差异可能导致诊断或报告的发现不同。
风险
- 隐私和保密性风险:患者数据,包括病例记录和图像,非常敏感。即使数据被正确匿名化,也有识别个人的风险。
- 数据完整性和质量风险:数据集中的不准确性、缺失数据和不一致性可能损害基于数据的研究发现或临床决策的有效性。这可能导致无效或有害的干预措施。
局限性
- 数据质量:
- 对于文本数据,某些患者记录缺少关键描述性术语。同时,未进行成像研究的病例缺少图像及其相应的描述性说明。
- 关于图像,主要关注的是数据集的不完整性,因为并非所有患者记录都附有图像。此外,图像分辨率的变化可能阻碍详细检查。图像大小和患者照片定位的不一致性也可能对一致的图像分析构成挑战。
搜集汇总
数据集介绍
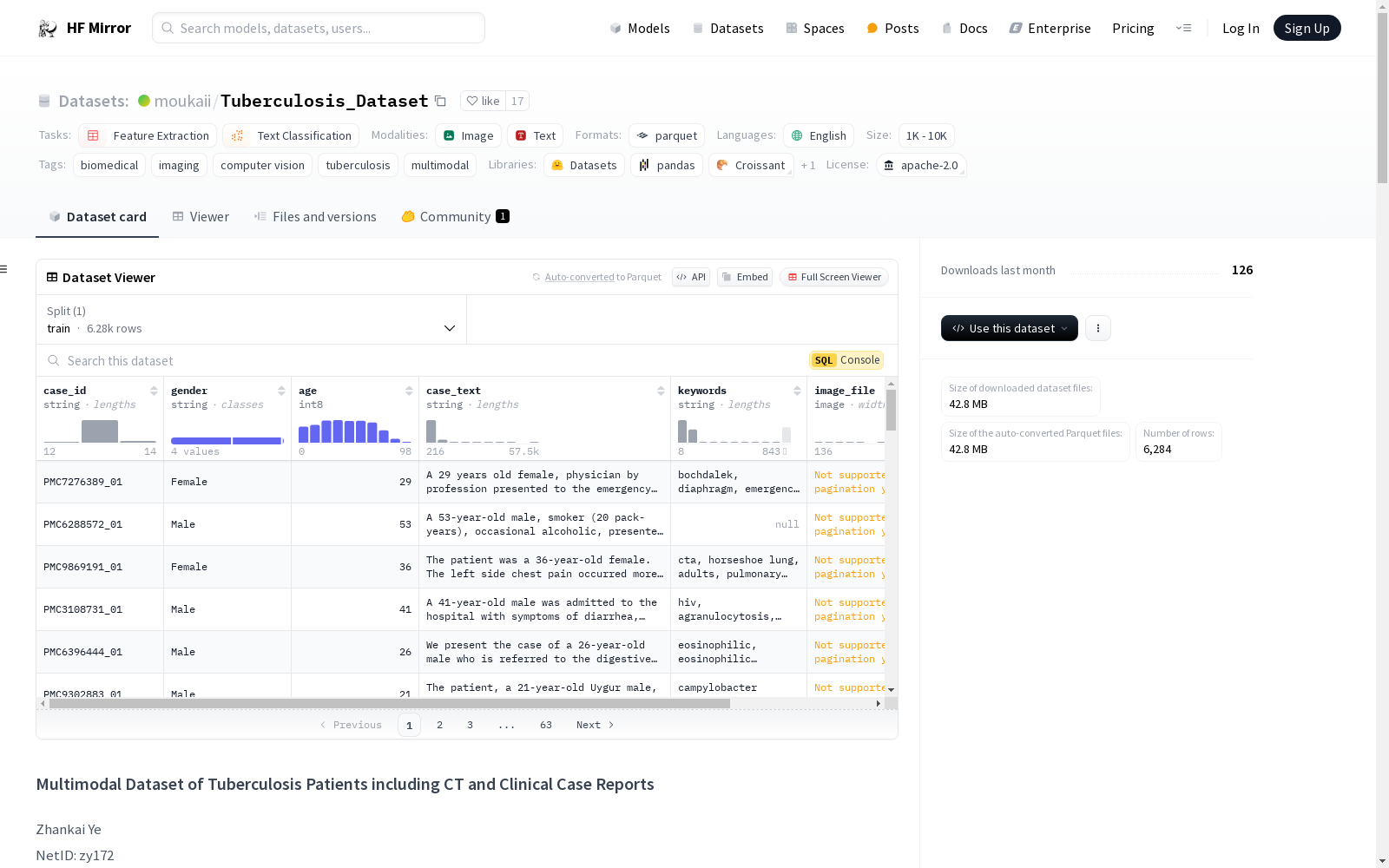
构建方式
该数据集从原始的‘The MultiCaRe Dataset’中精心筛选,专注于胸结核患者。构建过程首先基于关键词如‘tuberculosis’或‘tb’筛选病例报告,确保仅包含与结核病相关的报告。随后,通过过滤包含关键词如‘ct’、‘lung’或‘chest’的图像描述,进一步提炼数据集。最后,通过确保图像标签包含‘ct’和‘lung’,选择与肺部CT扫描相关的图像。此过程确保了数据集的高相关性和质量。
特点
该数据集具有多模态特性,结合了肺部CT影像数据和临床病例记录,包括患者的关键词、CT图像描述、患者ID、性别和年龄信息。这种多模态整合为结核病的诊断和治疗研究提供了丰富的资源。此外,数据集的构建过程中实施了严格的筛选和处理步骤,确保了数据的高质量和相关性。
使用方法
该数据集可用于开发胸部CT图像分割和结核病分类算法,以及从临床笔记中提取医学术语的自然语言处理方法。使用者可以通过访问数据集的官方页面下载数据,并根据提供的结构和实例进行数据处理和分析。数据集的详细字段信息和实例结构为研究者提供了清晰的指导,便于高效利用数据进行研究和开发。
背景与挑战
背景概述
在医学影像与临床数据分析领域,moukaii/Tuberculosis_Dataset数据集的创建标志着对结核病(Tuberculosis, TB)研究的一次重要推进。该数据集由Zhankai Ye主导,从原始的“The MultiCaRe Dataset”中精心筛选出与胸结核患者相关的肺部计算机断层扫描(CT)影像数据及临床病例报告。这一多模态数据集不仅包含了患者的性别、年龄等基本信息,还涵盖了病例文本、关键词及影像描述,为结核病的诊断与治疗研究提供了丰富的数据资源。自创建以来,该数据集已显著推动了CT影像分割与分类算法的发展,以及自然语言处理(NLP)技术在临床笔记中提取医学术语的应用,对公共卫生和医学研究领域产生了深远影响。
当前挑战
尽管moukaii/Tuberculosis_Dataset数据集在结核病研究中展现了巨大潜力,但其构建与应用过程中仍面临诸多挑战。首先,数据的选择偏差问题不容忽视,原始数据集的随机抽样无法保证不同人口群体的代表性,可能导致研究结果的普适性受限。其次,技术偏差也是一个重要问题,先进影像技术的不均衡分布可能导致数据集偏向于来自设备更先进机构的病例。此外,解释者偏差在病例文本和影像描述中同样存在,不同专家的经验和专业水平可能导致诊断结果的差异。在数据质量方面,文本数据中关键描述词的缺失和影像数据的不完整性,以及图像分辨率和尺寸的不一致性,都为数据分析带来了困难。这些挑战需要在未来的研究中得到充分考虑和解决,以确保数据集的有效性和可靠性。
常用场景
经典使用场景
在医学影像与临床文本的交叉领域,moukaii/Tuberculosis_Dataset 数据集以其独特的多模态特性,成为研究肺结核诊断与分类的经典资源。该数据集结合了肺部计算机断层扫描(CT)图像与患者的临床病例报告,为开发先进的图像分割算法和结核病阳性或对照分类模型提供了丰富的数据支持。此外,通过整合临床文本中的关键词,该数据集还推动了自然语言处理(NLP)技术在医学术语提取中的应用,从而提升了临床笔记的自动化分析能力。
实际应用
在实际应用中,moukaii/Tuberculosis_Dataset 数据集为肺结核的早期诊断和治疗提供了强有力的支持。通过结合CT图像和临床病例报告,该数据集能够帮助医疗机构开发和优化自动化诊断工具,从而提高诊断的准确性和效率。此外,数据集中的多模态信息还可以用于培训和验证新的医疗影像分析算法,进一步推动肺结核的精准医疗和个性化治疗的发展。
衍生相关工作
moukaii/Tuberculosis_Dataset 数据集的发布催生了一系列相关研究工作。例如,基于该数据集,研究者们开发了多种用于肺结核CT图像分割和分类的深度学习模型,显著提升了诊断的准确性。同时,数据集的多模态特性也激发了自然语言处理(NLP)技术在医学文本分析中的应用研究,推动了医学术语提取和临床笔记自动化的前沿进展。这些衍生工作不仅丰富了肺结核研究的工具箱,也为其他多模态医学数据集的研究提供了宝贵的经验。
以上内容由遇见数据集搜集并总结生成


