Estonian_Subjectivity
收藏Hugging Face2025-11-21 更新2025-11-22 收录
下载链接:
https://huggingface.co/datasets/tartuNLP/Estonian_Subjectivity
下载链接
链接失效反馈官方服务:
资源简介:
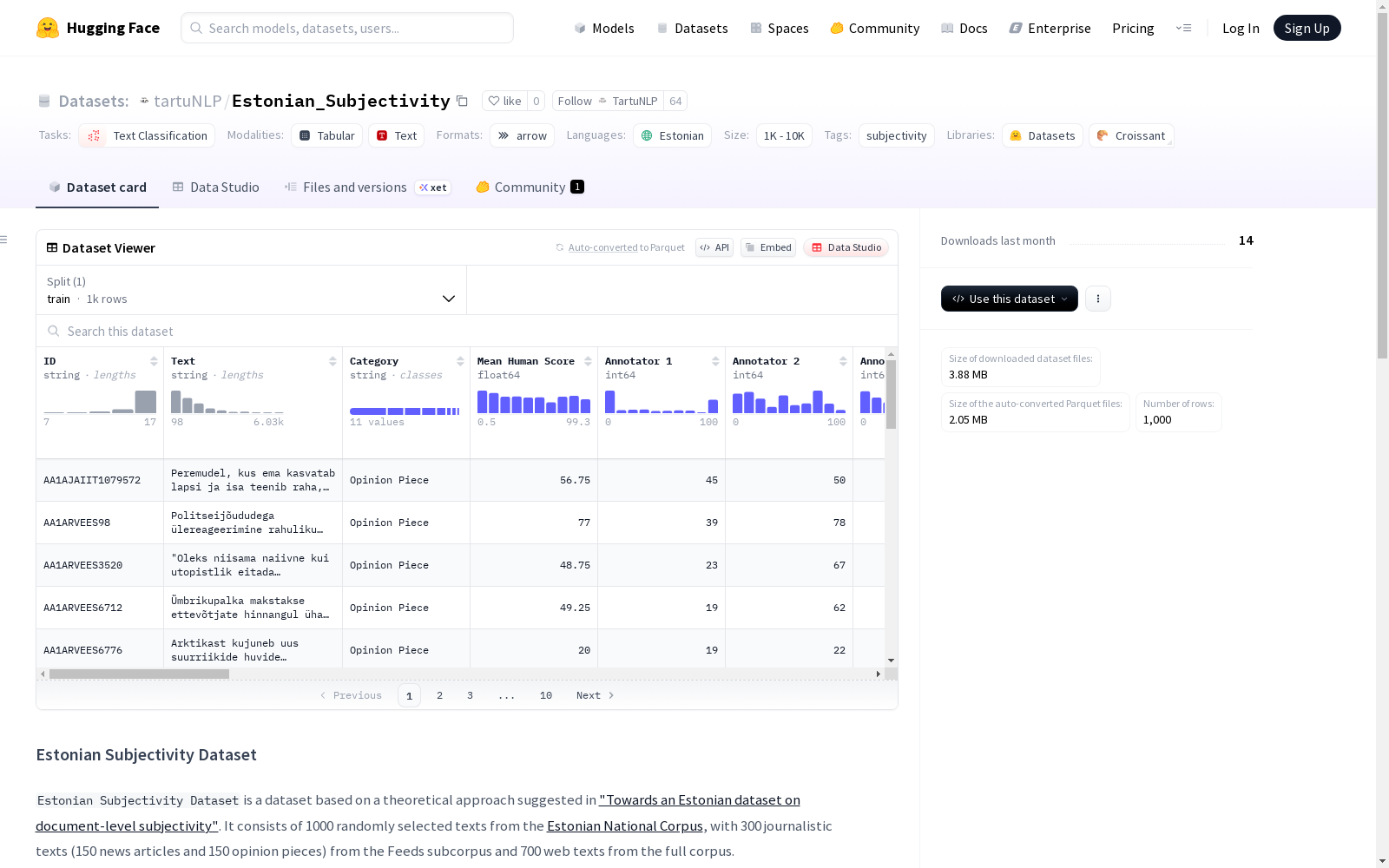
爱沙尼亚主观性数据集是一个关注爱沙尼亚语文本主观性的数据集。该数据集基于一篇理论论文中提出的方法,包含从爱沙尼亚国家语料库中随机选取的1000篇文本,由四位标注者根据0(客观性)至100(主观性)的滑动量表进行标注,并提供了对标注结果的信心度标注。此外,还有250篇文本由两位原始标注者进行了重新标注。数据集包括带有元数据、人类和GPT评分以及文本统计信息的多种列。
提供机构:
TartuNLP
创建时间:
2025-11-07
原始信息汇总
Estonian Subjectivity Dataset
数据集概述
- 名称:Estonian Subjectivity Dataset
- 语言:爱沙尼亚语(et)
- 任务类别:文本分类
- 规模类别:n<1K
数据来源
- 基于理论方法:"Towards an Estonian dataset on document-level subjectivity"
- 源语料库:Estonian National Corpus
- 文本数量:1000篇随机选择文本
- 文本构成:
- 300篇新闻文本(150篇新闻报道和150篇评论文章)来自Feeds子语料库
- 700篇网络文本来自完整语料库
标注信息
- 标注者数量:4名
- 标注方式:使用滑动尺度评分(0代表客观性,100代表主观性)
- 置信度评估:使用3点李克特量表评估标注置信度
- 重标注子集:250篇文本由两名原始标注者重新标注
- 220篇具有高度差异评分的文本
- 30篇控制文本
数据列描述
- ID — 唯一标识符
- Text — 完整的标注文本(爱沙尼亚语)
- Category — 文本类别或体裁
- Mean Human Score — 4名标注者评分的平均值(0-100整数)
- Annotator 1-4 — 单个标注者对文本的评分(0-100整数)
- Annotator 1-4 Certainty — 单个标注者对评分的置信度
- Annotator 2 & 3 Addition — 仅重标注子集,单个标注者对文本的评分(0-100整数)
- Annotator 2 & 3 Addition Certainty — 仅重标注子集,单个标注者对评分的置信度
- Mean GPT Score — 所有3个GPT-5批次的平均值(0-100整数)
- GPT Score 1-3 — GPT-5对文本的评分,每个提示单独列
- GPT Explanation 1-3 — GPT-5对给出评分的解释,每个提示单独列
- Number of Characters — 文本字符数
- Number of Words — 文本单词数(使用EstNLTK计算)
- Number of Sentences — 文本句子数(使用EstNLTK计算)
- Batch — 文本所属的初始批次
- Original Metadata — 爱沙尼亚国家语料库提供的原始元数据
加载方式
python from datasets import load_dataset ds = load_dataset(#insert) print(ds[0])
引用要求
使用本数据集时请引用:
citation
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,主观性分析对理解文本情感倾向至关重要。Estonian_Subjectivity数据集基于文档级主观性研究的理论框架构建,从爱沙尼亚国家语料库中随机选取1000篇文本,涵盖新闻稿件与网络内容两大类别。为确保数据多样性,样本包含300篇新闻类文本与700篇网络文本,所有材料均通过四位标注者采用滑动评分机制进行人工标注,并设置重标注子集以验证标注一致性。
特点
该数据集在主观性标注领域展现出独特价值,其标注体系采用0-100连续评分标度,精准捕捉文本主观性程度差异。除基础评分外,还创新性地引入三点李克特量表记录标注者置信度,并特别设置包含220个高分歧样本与30个对照样本的重标注子集。数据集同时整合了GPT-5模型的自动化评分结果,形成人类标注与机器标注的对比研究维度,为多角度分析提供丰富素材。
使用方法
研究者可通过HuggingFace平台便捷加载该数据集,使用标准数据加载接口即可获取完整标注信息。数据集中每个样本均包含原始文本、多维度标注分数及元数据,支持文档级主观性分类、标注一致性分析等研究任务。特别设计的重标注子集可用于开发标注质量控制算法,而并存的GPT-5评分则为自动化主观性分析模型提供基准参照。
背景与挑战
背景概述
在自然语言处理领域,文本主观性分析作为情感计算与观点挖掘的基础任务,对理解语言表达中的立场倾向具有关键意义。爱沙尼亚主观性数据集由塔尔图大学研究团队于2023年创建,基于《Towards an Estonian dataset on document-level subjectivity》提出的理论框架构建。该数据集从爱沙尼亚国家语料库中系统抽取1000个文本样本,涵盖新闻报导与网络文本等多类文体,通过四位标注者采用连续刻度进行主观性标注,为低资源语言的主观性分析研究提供了重要基准。
当前挑战
文档级主观性标注面临标注者间一致性的核心难题,连续刻度标注方式虽能捕捉细微差异,却增加了标注复杂度。构建过程中需克服爱沙尼亚语语言特性带来的分词与句法分析障碍,同时通过设计重标注机制处理标注分歧。该数据集还需应对小样本数据下模型泛化能力不足的挑战,以及如何有效融合人工标注与GPT模型预测结果的跨模态对齐问题。
常用场景
经典使用场景
在自然语言处理领域,Estonian_Subjectivity数据集为文本主观性分析提供了关键资源。该数据集通过系统标注爱沙尼亚语文本的主观性程度,广泛应用于训练和评估情感分析模型。研究者利用其连续评分机制,能够精确捕捉文本从客观描述到主观表达的渐变过程,为低资源语言的主观性研究树立了典范。
衍生相关工作
基于该数据集衍生的经典研究包括跨语言主观性迁移学习框架的构建,其中UTartu团队开发的多语种情感对齐模型最具代表性。后续研究进一步探索了GPT系列模型在低资源语言主观性标注中的泛化能力,催生了《波罗的海语言资源联合标注规范》的制定,推动了区域语言技术协同发展。
数据集最近研究
最新研究方向
在自然语言处理领域,爱沙尼亚主观性数据集作为稀缺的低资源语言标注语料,正推动跨语言主观性分析的前沿探索。该数据集融合人工标注与GPT-5自动评分双轨机制,为研究标注者间一致性、人机协同标注范式提供了实验基础。当前研究聚焦于通过控制文本与高分歧样本的再标注设计,深化对主观性量化评估中文化语境敏感度的理解,这对构建波罗的海语言资源生态及少样本迁移学习模型具有重要价值。
以上内容由遇见数据集搜集并总结生成


