PhenoBench
收藏arXiv2023-06-08 更新2024-06-21 收录
下载链接:
https://www.phenobench.org
下载链接
链接失效反馈官方服务:
资源简介:
PhenoBench是由德国波恩大学创建的大型数据集,专注于农业领域的语义图像解释。该数据集包含2872张高分辨率图像,通过无人机拍摄,涵盖了甜菜作物和杂草在不同生长阶段的详细标注。数据集不仅包括作物和杂草的实例级标注,还包括作物叶片的实例级标注,支持开发新的视觉感知算法。此外,PhenoBench还提供了针对不同视觉感知任务的基准测试,包括语义分割、全景分割、植物检测等,旨在推动农业领域视觉系统的可靠性和效率。
PhenoBench is a large-scale dataset developed by the University of Bonn in Germany, focusing on semantic image interpretation in the agricultural domain. This dataset comprises 2872 high-resolution images captured by unmanned aerial vehicles (UAVs), featuring detailed annotations for sugar beet crops and weeds across various growth stages. In addition to instance-level annotations for crops and weeds, it also includes instance-level annotations for crop leaves, which supports the development of cutting-edge visual perception algorithms. Furthermore, PhenoBench provides benchmark tests for multiple visual perception tasks, including semantic segmentation, panoptic segmentation, plant detection, and others, aiming to advance the reliability and efficiency of visual systems in agricultural applications.
提供机构:
波恩大学
创建时间:
2023-06-08
搜集汇总
数据集介绍
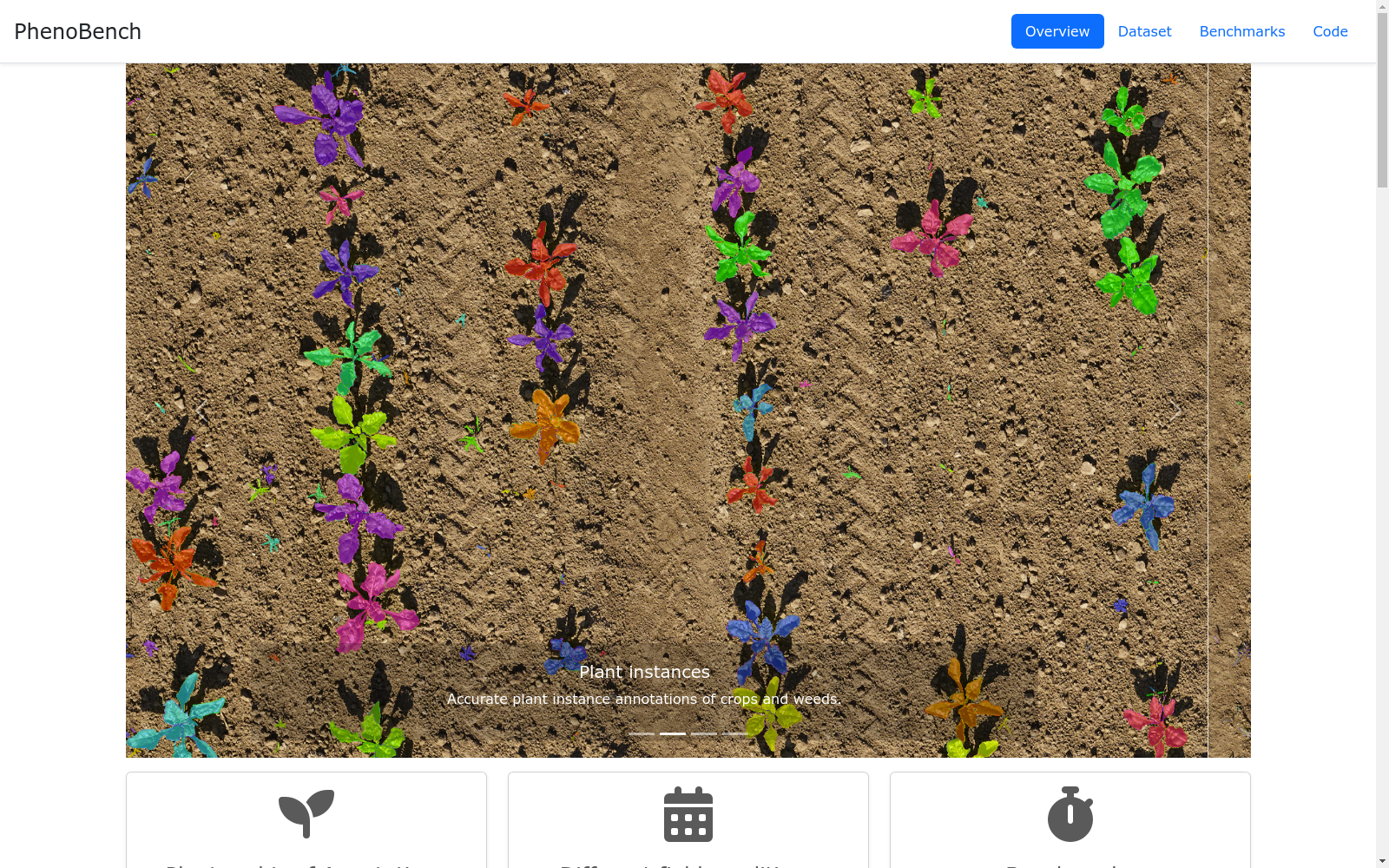
构建方式
在农业视觉感知领域,高质量标注数据的稀缺制约了算法的发展。PhenoBench数据集通过无人机搭载高分辨率相机,在真实农田环境下采集甜菜作物图像,覆盖多个生长阶段以捕捉植物形态的动态变化。数据采集采用系统化飞行规划,确保75%的前向重叠与50%的侧向重叠,获得地面采样距离达1毫米/像素的精细图像。标注流程采用创新的分层标注工具,先对植物实例进行像素级标注,再对作物叶片进行实例级标注,通过多轮迭代与质量验证,最终形成包含2872张高分辨率图像的标注数据集。
特点
该数据集的核心特征在于其多层次、精细化的标注体系。不仅提供了作物与杂草的语义分割与实例分割标注,更创新性地引入了作物叶片的实例级标注,实现了植物整体与器官结构的双重解析。数据涵盖不同生长阶段的植物形态,呈现出显著的类内变异性与实例重叠现象,模拟了真实农田的复杂场景。此外,数据集划分包含已知农田与未见农田的测试集,并额外提供未标注数据,为领域自适应与自监督学习研究创造了条件。这种结构设计使其能够支持从传统语义分割到新颖的层次化全景分割等多种视觉任务。
使用方法
PhenoBench数据集为农业视觉算法研发提供了标准化的评估平台。研究者可利用其丰富的标注信息,开发与验证语义分割、全景分割、植物与叶片检测、叶片实例分割以及层次化全景分割等五大核心任务模型。数据集已划分训练、验证与隐藏测试集,支持在服务器端进行公平、可复现的性能评估。对于领域泛化研究,可利用其包含的未知农田测试数据探索模型迁移能力。同时,附带的未标注图像可用于自监督预训练或半监督学习,以降低对大量标注数据的依赖,推动更具实用性的农业视觉系统发展。
背景与挑战
背景概述
在精准农业与农业机器人技术蓬勃发展的背景下,视觉感知系统对于实现可持续田间管理和作物表型分析至关重要。PhenoBench数据集由德国波恩大学、牛津大学及Lamarr人工智能研究所的研究团队于2023年联合创建,旨在为农业领域的语义图像理解提供大规模基准数据。该数据集通过无人机采集高分辨率甜菜田图像,并提供了作物与杂草的密集像素级实例标注,以及作物叶片的精细实例分割标注。其核心研究问题聚焦于解决开放农田环境下植物与叶片的精确分割、检测及层次化全景分割任务,以支持自动化杂草管理、作物生长监测及表型分析,对推动农业计算机视觉从实验室走向实际应用具有里程碑意义。
当前挑战
PhenoBench数据集致力于解决农业视觉感知中多个核心任务的挑战:在语义与实例分割方面,需应对作物与杂草因生长阶段、光照条件及相互遮挡导致的高类内差异与外观变化;在叶片实例分割中,密集冠层下叶片间的严重重叠与形态相似性构成了重大识别障碍。数据构建过程同样面临显著挑战:高分辨率图像的大规模标注耗费巨大人力,仅标注工作即投入约2000小时;为确保植物完整性,需设计复杂的图像分块与迭代标注流程;同时,农田环境的多变光照、不同土壤条件导致的生长不均,以及跨年份、跨田块的数据采集,均对标注一致性与数据泛化性提出了极高要求。
常用场景
经典使用场景
在精准农业的视觉感知研究中,PhenoBench数据集为作物与杂草的语义分割、实例分割及全景分割任务提供了经典的应用场景。该数据集通过无人机采集的高分辨率甜菜田图像,涵盖了作物生长周期的多个阶段,并提供了像素级的植物实例与叶片实例标注。研究者可基于此数据集开发与评估算法,以实现在复杂田间环境下对作物和杂草的精确识别与分离,为自动化田间管理提供关键技术支持。
衍生相关工作
围绕PhenoBench数据集,已衍生出一系列重要的研究工作。例如,Weyler等人提出了基于叶片与植物实例分割的田间表型分析方法,Roggiolani等人开发了面向层次化全景分割的HAPT架构。这些工作利用数据集的层次标注特性,探索了从叶片到植株的粗粒度到细粒度解析模型。同时,该数据集也促进了通用分割模型(如Mask2Former、Panoptic DeepLab)在农业领域的适应性研究,以及跨作物物种的域泛化与自监督学习等前沿方向的探索。
数据集最近研究
最新研究方向
在农业视觉感知领域,PhenoBench数据集推动了从传统语义分割向多层次、细粒度解析的前沿探索。该数据集通过提供植物级与叶片级的实例标注,促进了层次化全景分割这一新兴任务的发展,旨在同时识别作物植株及其叶片实例,从而实现对植物生长阶段的自动化评估。当前研究聚焦于利用Transformer架构等先进模型提升在复杂田间场景下的实例分离精度,尤其是在作物重叠与叶片密集情况下的分割鲁棒性。此外,结合自监督学习与跨域迁移方法,以降低标注成本并增强模型在不同作物与环境中的泛化能力,正成为该领域的热点方向。这些进展对于实现精准农业中的可持续田间管理与自动化表型分析具有重要科学意义与应用价值。
相关研究论文
- 1PhenoBench -- A Large Dataset and Benchmarks for Semantic Image Interpretation in the Agricultural Domain波恩大学 · 2023年
以上内容由遇见数据集搜集并总结生成


