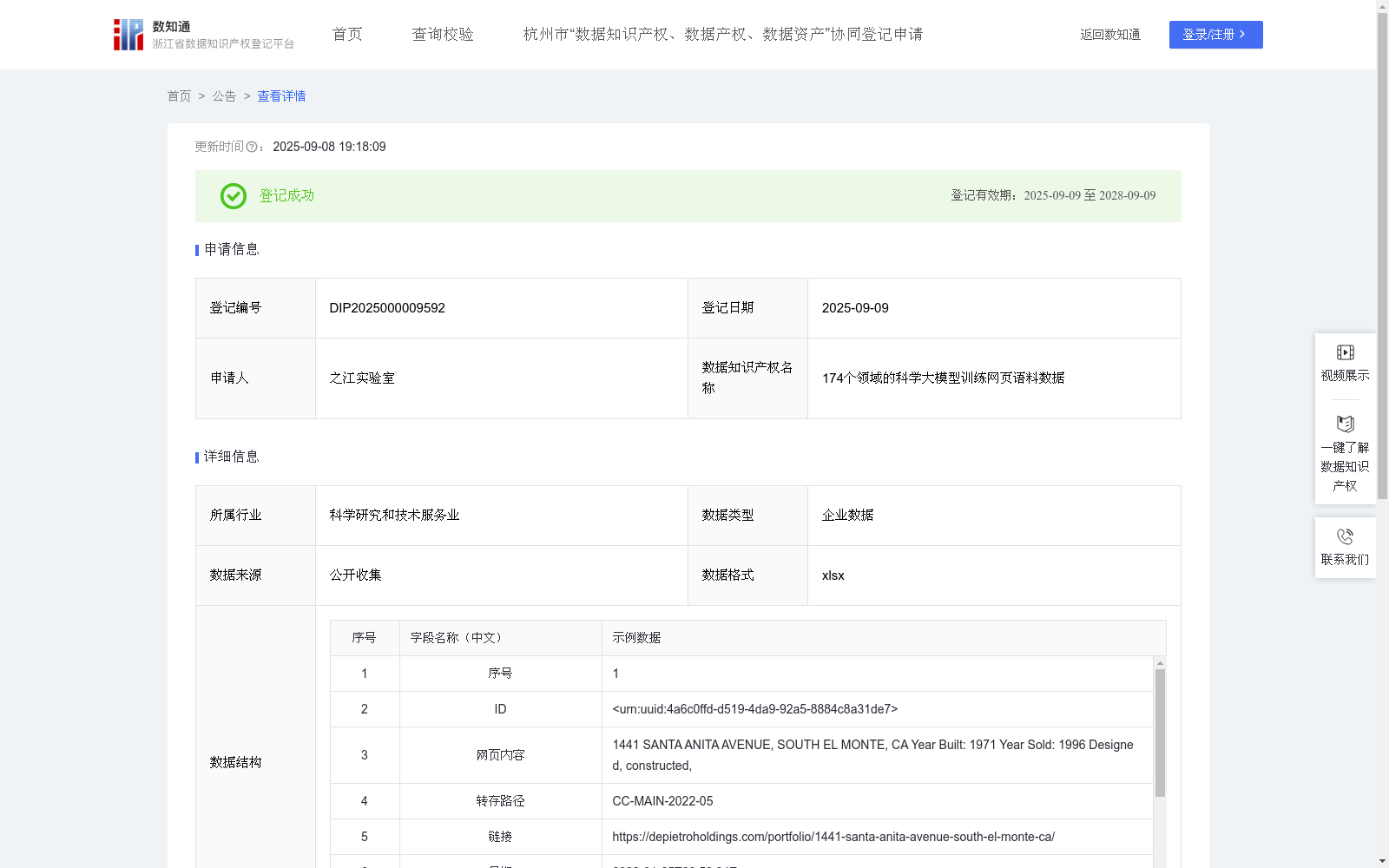
174个领域的科学大模型训练网页语料数据
收藏浙江省数据知识产权登记平台2025-09-08 更新2025-09-09 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/176906
下载链接
链接失效反馈官方服务:
资源简介:
该数据知识产权用于多领域科学基座大语言模型的训练,使其可以学习各领域的专业术语、概念和语义信息,从而具备处理各学科自然语言处理任务的能力,助力科学家进行学术研究,回答不同领域问题,并可为长篇论文生成不同长度的摘要,适应会议提交或快速浏览等场景。将中文论文自动翻译为各种语言并保持术语准确性,促进跨语言科研交流。该数据也可以用于构建智能文献检索系统,从而使科学大模型能够具备地学文献检索的能力,为研究人员提供个性化的文献推荐服务,提高文献获取效率。1. 从公开的FineWeb和DCLM数据集进行采集
2. 将与科学相关的,如生物、化学等网页数据的域名及内容,保存为特定格式,如csv等格式
3. 通过相关学科数据,使用Fasttext算法训练学科分类器,对FineWeb语料进行学科网页域名召回,并得到文本内容、语言分类、语言得分和学科分类。
4. 对召回网页的域名进行域名聚合、域名筛选及评估,对学科分类器进行迭代优化,从而得到更多召回的网页数据,及优化的文本内容、语言分类、语言得分和学科分类。
5. 对召回后的网页数据通过Gopher Repetition、Gopher Quality、C4 Quality、 FineWeb Quality的算法进行质量过滤
6. 对质量过滤后的数据,基于Minhash对文档进行签名计算,使用LSH将相似文档分组,进行针对文档级别相似性去重。
7. 将去重后的数据进行tokenizer转化,得到token数。
8. 最终数据包含文本内容、语言分类、语言得分、token数及学科分类。
提供机构:
之江实验室
创建时间:
2025-06-27
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含503条网页语料,覆盖174个科学领域,用于训练科学大模型,支持专业术语学习、多语言翻译和文献检索。数据通过公开收集,经过严格的质量过滤和去重处理,格式为xlsx,按需更新。
以上内容由遇见数据集搜集并总结生成


