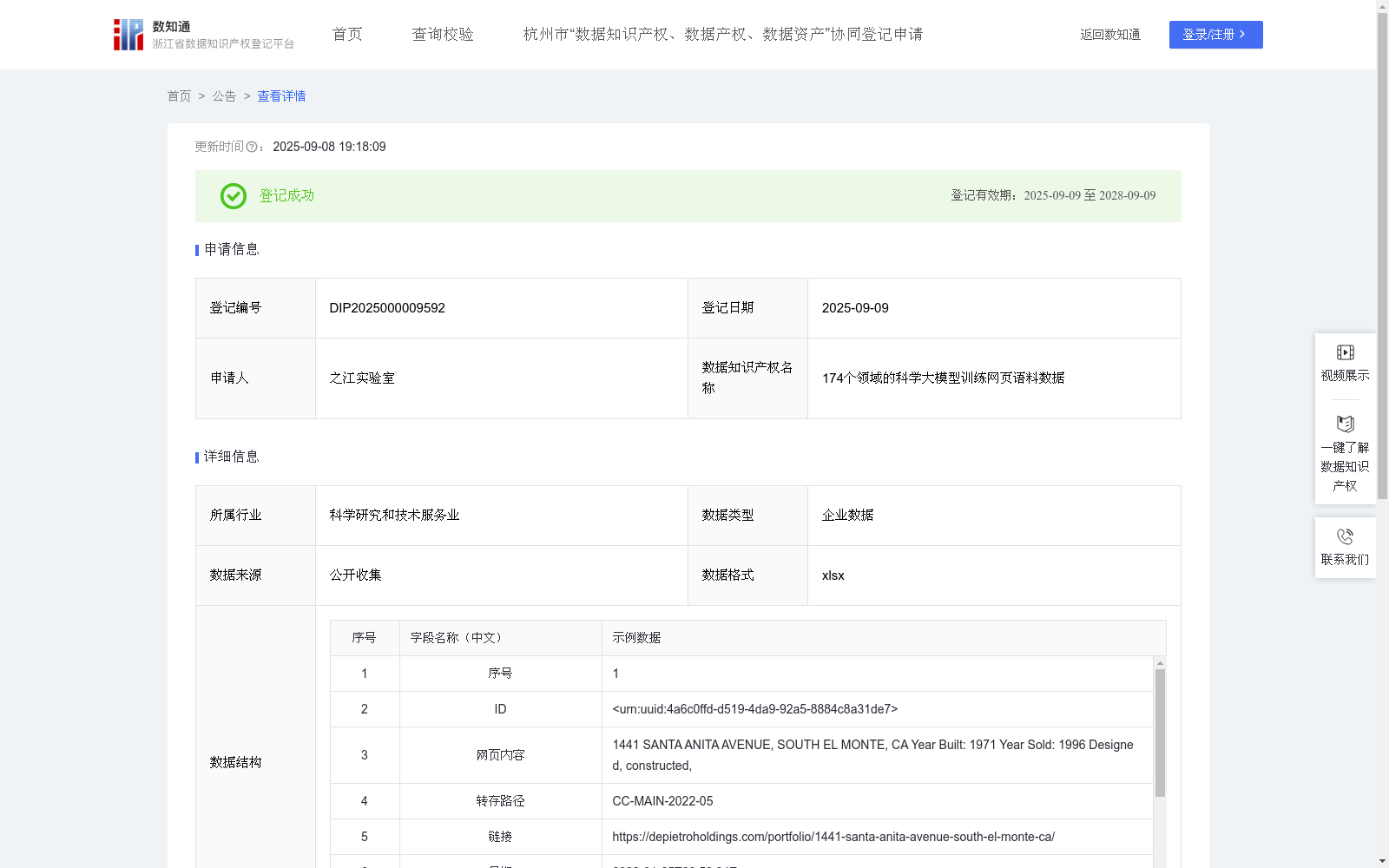
174个领域的科学大模型训练网页语料数据
收藏资源简介:
该数据知识产权用于多领域科学基座大语言模型的训练,使其可以学习各领域的专业术语、概念和语义信息,从而具备处理各学科自然语言处理任务的能力,助力科学家进行学术研究,回答不同领域问题,并可为长篇论文生成不同长度的摘要,适应会议提交或快速浏览等场景。将中文论文自动翻译为各种语言并保持术语准确性,促进跨语言科研交流。该数据也可以用于构建智能文献检索系统,从而使科学大模型能够具备地学文献检索的能力,为研究人员提供个性化的文献推荐服务,提高文献获取效率。1. 从公开的FineWeb和DCLM数据集进行采集 2. 将与科学相关的,如生物、化学等网页数据的域名及内容,保存为特定格式,如csv等格式 3. 通过相关学科数据,使用Fasttext算法训练学科分类器,对FineWeb语料进行学科网页域名召回,并得到文本内容、语言分类、语言得分和学科分类。 4. 对召回网页的域名进行域名聚合、域名筛选及评估,对学科分类器进行迭代优化,从而得到更多召回的网页数据,及优化的文本内容、语言分类、语言得分和学科分类。 5. 对召回后的网页数据通过Gopher Repetition、Gopher Quality、C4 Quality、 FineWeb Quality的算法进行质量过滤 6. 对质量过滤后的数据,基于Minhash对文档进行签名计算,使用LSH将相似文档分组,进行针对文档级别相似性去重。 7. 将去重后的数据进行tokenizer转化,得到token数。 8. 最终数据包含文本内容、语言分类、语言得分、token数及学科分类。
This dataset, along with its associated intellectual property rights, is intended for training multi-domain scientific foundation large language models (LLMs). It enables the models to acquire professional terminology, concepts and semantic information across various academic fields, thus endowing them with the capacity to handle natural language processing tasks across different disciplines. The dataset supports scientists in conducting academic research, answering questions from diverse domains, and generating abstracts of varying lengths for full-length academic papers to accommodate scenarios such as conference submissions or quick document browsing. It can also automatically translate Chinese academic papers into multiple languages while preserving terminology accuracy, thereby promoting cross-linguistic scientific communication. Additionally, this dataset can be utilized to develop intelligent literature retrieval systems, enabling scientific LLMs to support geoscience literature retrieval, provide personalized literature recommendation services for researchers, and enhance the efficiency of literature acquisition. 1. Collection from publicly available FineWeb and DCLM datasets. 2. Extract and save the domain names and content of science-related web data (e.g., biology, chemistry) in specified formats such as CSV. 3. Train a disciplinary classifier using the Fasttext algorithm with relevant disciplinary datasets, perform web domain recall for disciplinary classification on the FineWeb corpus, and obtain text content, language classification, language confidence score, and disciplinary classification results. 4. Conduct domain aggregation, screening and evaluation on the recalled web domains, and iteratively optimize the disciplinary classifier to obtain more recalled web data, as well as optimized text content, language classification, language confidence score, and disciplinary classification. 5. Conduct quality filtering on the recalled web data using algorithms including Gopher Repetition, Gopher Quality, C4 Quality, and FineWeb Quality. 6. For the post-filtering data, compute document signatures based on Minhash, group similar documents using Locality-Sensitive Hashing (LSH), and perform document-level similarity deduplication. 7. Apply tokenization to the deduplicated data to obtain the token count. 8. The final dataset includes text content, language classification, language confidence score, token count, and disciplinary classification.