expertA
收藏Hugging Face2025-12-09 更新2025-12-10 收录
下载链接:
https://huggingface.co/datasets/icomgpu/expertA
下载链接
链接失效反馈官方服务:
资源简介:
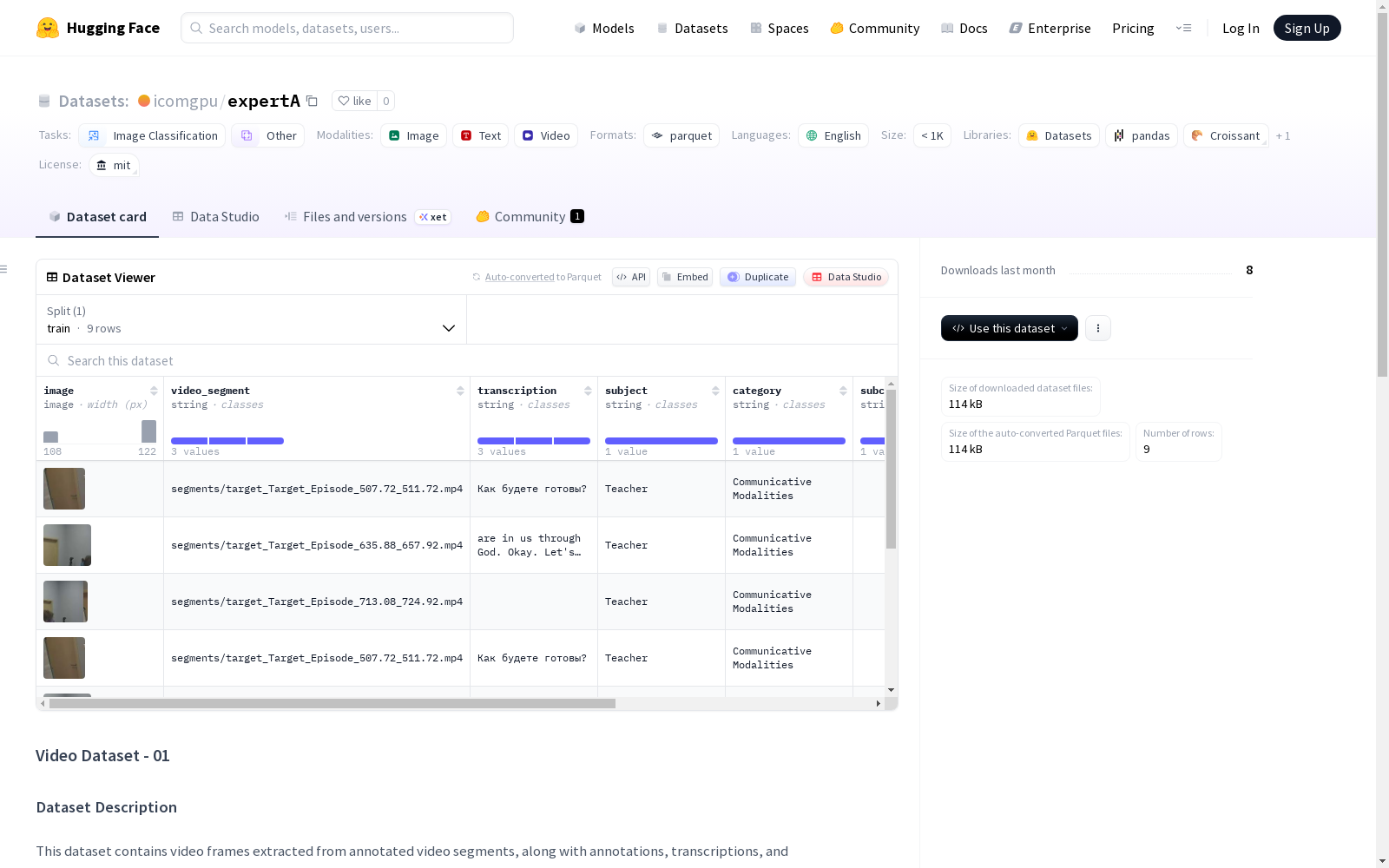
该数据集包含从注释视频片段中提取的视频帧,以及注释、转录和相应的视频剪辑。数据集结构包括帧、片段、注释、转录和元数据映射文件。数据集统计显示有9帧、9个片段和1个唯一标签。数据集特征包括提取的视频帧、对应视频剪辑文件的路径、音频片段的文本转录、动作主题、动作类别、子类别、动作描述以及上下文和附加评论。
创建时间:
2025-12-08
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: Video Dataset - 01
- 托管地址: https://huggingface.co/datasets/icomgpu/expertA
- 许可证: mit
- 任务类别: 图像分类, 其他
- 语言: 英语
- 数据规模: 小于1K
数据集描述
该数据集包含从带标注的视频片段中提取的视频帧,以及标注、转录文本和相应的视频剪辑。
数据集结构
- frames/: 提取的帧(每个片段的第一帧)
- segments/: 每个标注区间的视频剪辑
- annotations/: 原始JSON标注文件
- transcriptions/: 转录文件(
full_transcription.txt及每个片段的转录) - dataset.csv: 帧、视频剪辑、转录文本和元数据之间的映射文件
数据集特征(字段)
- image: 提取的视频帧(JPEG格式),为每个片段的第一帧
- video_segment: 对应视频剪辑文件的路径
- transcription: 音频片段的文本转录
- subject: 动作的主体(例如:"Учитель", "Группа учеников")
- category: 动作的类别(例如:"Педагогические действия", "Коммуникативные модальности")
- subcategory: 子类别(可能包含多个值,用";"分隔)
- action_description: 动作描述
- context_and_comments: 上下文和附加评论
数据集统计
- 数据划分: 仅包含训练集
- 训练集样本数量: 9
- 帧数量: 9
- 片段数量: 9
- 唯一标签数量: 1
使用方法
可使用Hugging Face的datasets库加载此数据集:
python
from datasets import load_dataset
dataset = load_dataset("your-org/video-dataset-01")
搜集汇总
数据集介绍
构建方式
在视频分析领域,expertA数据集通过系统化的方法构建而成。该过程首先从标注的视频片段中提取关键帧,通常选取每个片段的首帧作为代表性图像,确保视觉信息的完整性。同时,数据集整合了对应的视频剪辑文件、音频转录文本以及多层次的元数据标注,包括主体、类别、子类别、动作描述及上下文注释。所有数据通过结构化的CSV文件进行映射,确保了图像、视频、转录和元数据之间的一致性,为后续分析提供了坚实基础。
使用方法
利用Hugging Face的datasets库,expertA数据集可便捷加载至Python环境。用户通过调用load_dataset函数并指定数据集路径,即可访问包含图像、视频路径、转录及各类元数据的结构化条目。数据集的CSV映射文件进一步简化了多模态信息的关联查询,支持研究者直接进行帧分析、转录比对或元数据筛选。这种标准化接口确保了数据的高效利用,适用于计算机视觉、自然语言处理及多模态融合的实验与模型训练。
背景与挑战
背景概述
在计算机视觉与多模态学习领域,视频理解任务日益受到关注,旨在从动态视觉序列中解析复杂的人类行为与交互。expertA数据集应运而生,其创建时间与主要研究人员虽未明确标注,但该数据集聚焦于教育场景下的视频分析,核心研究问题在于识别与分类教学环境中的特定动作与沟通模式。通过整合视频帧、音频转录及多层次标注,该数据集为教学行为分析、课堂交互建模等应用提供了宝贵资源,对教育技术、人机交互等相关领域的发展具有潜在推动作用。
当前挑战
expertA数据集所解决的领域问题在于视频动作识别与多模态分析,其挑战体现在对教育场景中细微且多样化的教学行为进行精确分类,同时需处理音频与视觉信息的对齐与融合。在构建过程中,数据集面临数据规模有限的挑战,仅包含9个样本,这限制了模型的泛化能力;此外,标注体系涉及多层次类别(如主题、类别、子类别),需确保标注的一致性与完整性,而视频帧提取、分段处理以及转录文本的整合也增加了数据构建的复杂性。
常用场景
经典使用场景
在教育技术领域,视频数据为分析课堂教学行为提供了丰富的多模态信息。expertA数据集通过整合视频帧、音频转录与结构化标注,经典地应用于教学行为识别与分类任务。研究者利用其图像与文本特征,构建模型以自动识别教师或学生的特定动作,如提问、讲解或互动,从而量化教学过程中的关键行为模式,为教育评估提供数据驱动的见解。
解决学术问题
该数据集主要解决了教育视频分析中多模态信息融合的挑战,将视觉、听觉与语义标注统一于结构化框架内。其意义在于促进了教学行为自动识别、课堂互动模式挖掘等研究,使学者能够系统探究教学策略与学习效果间的关联。通过提供细粒度的动作描述与上下文注释,该数据集推动了教育人工智能领域从理论到实证的过渡,为智能教育系统的开发奠定了数据基础。
实际应用
在实际应用中,expertA数据集支持智能课堂分析系统的构建,帮助教育机构自动化评估教学质量。例如,系统可实时监测教师的教学行为分布,生成反馈报告以优化教学策略;同时,该数据可用于培训师范生,通过案例学习提升教学技能。此外,在在线教育平台中,此类数据能增强内容推荐与个性化学习路径的设计,提升教育资源的利用效率。
数据集最近研究
最新研究方向
在视频理解与多模态学习领域,expertA数据集凭借其融合视觉帧、音频转录与细粒度动作标注的结构,为教学场景下的行为分析提供了宝贵资源。当前研究聚焦于利用此类小规模高质量标注数据,探索少样本学习与跨模态对齐的前沿方法,旨在克服数据稀缺挑战,提升模型对复杂教学交互的语义理解能力。相关热点事件如教育数字化转型加速了对此类专业化数据集的需求,推动其在智能教学评估、教师专业发展分析等应用中的深入探索,对促进个性化教育技术发展具有积极意义。
以上内容由遇见数据集搜集并总结生成


