Qwen3-14B-reasoning
收藏魔搭社区2026-01-06 更新2025-08-30 收录
下载链接:
https://modelscope.cn/datasets/NousResearch/Qwen3-14B-reasoning
下载链接
链接失效反馈官方服务:
资源简介:
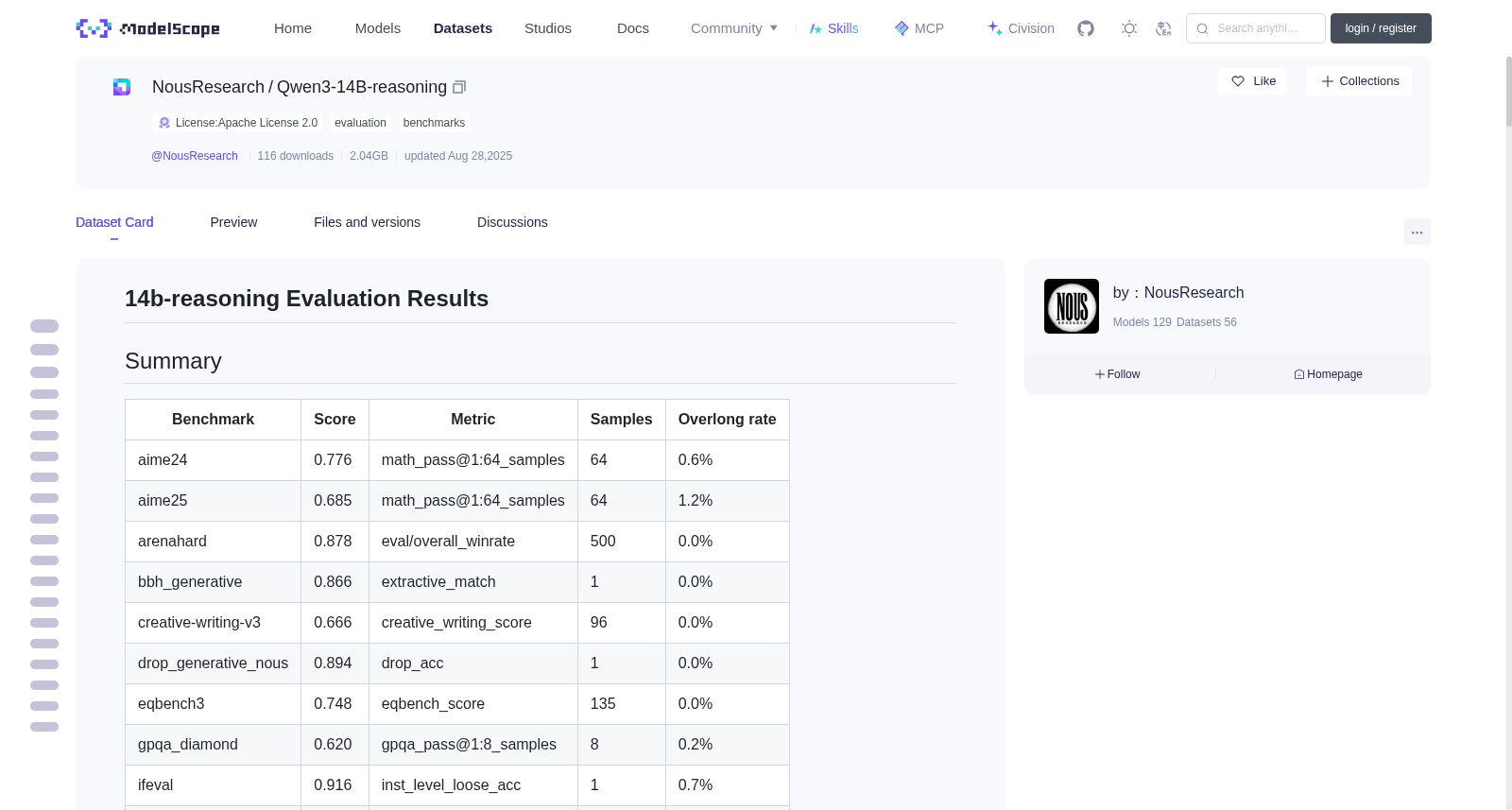
# 14b-reasoning Evaluation Results
## Summary
| Benchmark | Score | Metric | Samples | Overlong rate |
|-----------|-------|--------|---------|---------------|
| aime24 | 0.776 | math_pass@1:64_samples | 64 | 0.6% |
| aime25 | 0.685 | math_pass@1:64_samples | 64 | 1.2% |
| arenahard | 0.878 | eval/overall_winrate | 500 | 0.0% |
| bbh_generative | 0.866 | extractive_match | 1 | 0.0% |
| creative-writing-v3 | 0.666 | creative_writing_score | 96 | 0.0% |
| drop_generative_nous | 0.894 | drop_acc | 1 | 0.0% |
| eqbench3 | 0.748 | eqbench_score | 135 | 0.0% |
| gpqa_diamond | 0.620 | gpqa_pass@1:8_samples | 8 | 0.2% |
| ifeval | 0.916 | inst_level_loose_acc | 1 | 0.7% |
| lcb-v6-aug2024+ | 0.612 | eval/pass_1 | 1 | 0.5% |
| math_500 | 0.972 | math_pass@1:4_samples | 4 | 0.1% |
| mmlu_generative | 0.847 | extractive_match | 1 | 0.0% |
| mmlu_pro | 0.775 | pass@1:1_samples | 1 | 0.0% |
| musr_generative | 0.662 | extractive_match | 1 | 0.0% |
| obqa_generative | 0.964 | extractive_match | 1 | 0.0% |
| rewardbench | 0.735 | eval/percent_correct | 1 | 0.0% |
| simpleqa_nous | 0.056 | fuzzy_match | 1 | 0.1% |
Overlong rate: 91 / 64,523 samples (0.1%) missing closing `</think>` tag
## Detailed Results
### aime24
| Metric | Score | Std Error |
|--------|-------|----------|
| math_pass@1:1_samples | 0.767 | 0.079 |
| math_pass@1:4_samples | 0.792 | 0.065 |
| math_pass@1:8_samples | 0.779 | 0.065 |
| math_pass@1:16_samples | 0.777 | 0.067 |
| math_pass@1:32_samples | 0.779 | 0.065 |
| math_pass@1:64_samples | 0.776 | 0.066 |
**Model:** 14b-reasoning
**Evaluation Time (hh:mm:ss):** 00:25:20
**Temperature:** 0.6
**Overlong samples:** 0.6% (12 / 1920)
### aime25
| Metric | Score | Std Error |
|--------|-------|----------|
| math_pass@1:1_samples | 0.633 | 0.089 |
| math_pass@1:4_samples | 0.667 | 0.072 |
| math_pass@1:8_samples | 0.671 | 0.067 |
| math_pass@1:16_samples | 0.694 | 0.066 |
| math_pass@1:32_samples | 0.690 | 0.067 |
| math_pass@1:64_samples | 0.685 | 0.067 |
**Model:** 14b-reasoning
**Evaluation Time (hh:mm:ss):** 00:30:03
**Temperature:** 0.6
**Overlong samples:** 1.2% (23 / 1920)
### arenahard
| Metric | Score | Std Error |
|--------|-------|----------|
| eval/overall_winrate | 0.878 | 0.000 |
| eval/total_samples | 500.000 | 0.000 |
| eval/win_count | 417.000 | 0.000 |
| eval/tie_count | 43.000 | 0.000 |
| eval/loss_count | 40.000 | 0.000 |
| eval/win_rate | 0.834 | 0.000 |
| eval/tie_rate | 0.086 | 0.000 |
| eval/loss_rate | 0.080 | 0.000 |
| eval/winrate_arena-hard-v0.1 | 0.878 | 0.000 |
**Model:** qwen14b-arena-think
**Evaluation Time (hh:mm:ss):** 00:04:47
**Temperature:** 0.6
**Overlong samples:** 0.0% (0 / 500)
### bbh_generative
| Metric | Score | Std Error |
|--------|-------|----------|
| extractive_match | 0.866 | 0.015 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:22:50
**Temperature:** 0.6
**Overlong samples:** 0.0% (1 / 5511)
### creative-writing-v3
| Metric | Score | Std Error |
|--------|-------|----------|
| creative_writing_score | 0.666 | 0.000 |
| num_samples | 96.000 | 0.000 |
**Model:** 14b-reasoning
**Evaluation Time (hh:mm:ss):** N/A
**Temperature:** N/A
**Overlong samples:** 0.0% (0 / 96)
### drop_generative_nous
| Metric | Score | Std Error |
|--------|-------|----------|
| drop_acc | 0.894 | 0.003 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:38:27
**Temperature:** 0.6
**Overlong samples:** 0.0% (0 / 9536)
### eqbench3
| Metric | Score | Std Error |
|--------|-------|----------|
| eqbench_score | 0.748 | 0.000 |
| num_samples | 135.000 | 0.000 |
**Model:** qwen14b-arena-think
**Evaluation Time (hh:mm:ss):** N/A
**Temperature:** N/A
**Overlong samples:** 0.0% (0 / 135)
### gpqa_diamond
| Metric | Score | Std Error |
|--------|-------|----------|
| gpqa_pass@1:1_samples | 0.626 | 0.034 |
| gpqa_pass@1:4_samples | 0.630 | 0.030 |
| gpqa_pass@1:8_samples | 0.620 | 0.030 |
**Model:** 14b-reasoning
**Evaluation Time (hh:mm:ss):** 00:10:03
**Temperature:** 0.6
**Overlong samples:** 0.2% (3 / 1584)
### ifeval
| Metric | Score | Std Error |
|--------|-------|----------|
| prompt_level_strict_acc | 0.841 | 0.016 |
| inst_level_strict_acc | 0.892 | 0.000 |
| prompt_level_loose_acc | 0.876 | 0.014 |
| inst_level_loose_acc | 0.916 | 0.000 |
**Model:** Qwen3-14B-reasoning-ifeval-aime
**Evaluation Time (hh:mm:ss):** 00:14:45
**Temperature:** 0.6
**Overlong samples:** 0.7% (4 / 541)
### lcb-v6-aug2024+
| Metric | Score | Std Error |
|--------|-------|----------|
| eval/pass_1 | 0.612 | 0.000 |
| eval/easy_pass_1 | 0.984 | 0.000 |
| eval/medium_pass_1 | 0.745 | 0.000 |
| eval/hard_pass_1 | 0.319 | 0.000 |
| eval/completion_length | 47016.365 | 0.000 |
**Model:** qwen3-14b-nonreasoning
**Evaluation Time (hh:mm:ss):** 02:14:03
**Temperature:** N/A
**Overlong samples:** 0.5% (36 / 7264)
### math_500
| Metric | Score | Std Error |
|--------|-------|----------|
| math_pass@1:1_samples | 0.970 | 0.008 |
| math_pass@1:4_samples | 0.972 | 0.006 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:11:07
**Temperature:** 0.6
**Overlong samples:** 0.1% (2 / 2000)
### mmlu_generative
| Metric | Score | Std Error |
|--------|-------|----------|
| extractive_match | 0.847 | 0.003 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:55:52
**Temperature:** 0.6
**Overlong samples:** 0.0% (2 / 14042)
### mmlu_pro
| Metric | Score | Std Error |
|--------|-------|----------|
| pass@1:1_samples | 0.775 | 0.004 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:53:32
**Temperature:** 0.6
**Overlong samples:** 0.0% (5 / 12032)
### musr_generative
| Metric | Score | Std Error |
|--------|-------|----------|
| extractive_match | 0.662 | 0.030 |
**Model:** Qwen3-14B-reasoning-ifeval-aime
**Evaluation Time (hh:mm:ss):** 00:04:02
**Temperature:** 0.6
**Overlong samples:** 0.0% (0 / 756)
### obqa_generative
| Metric | Score | Std Error |
|--------|-------|----------|
| extractive_match | 0.964 | 0.008 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:02:28
**Temperature:** 0.6
**Overlong samples:** 0.0% (0 / 500)
### rewardbench
| Metric | Score | Std Error |
|--------|-------|----------|
| eval/percent_correct | 0.735 | 0.000 |
| eval/total_samples | 1865.000 | 0.000 |
| eval/correct_samples | 1370.000 | 0.000 |
| eval/format_compliance_rate | 1.000 | 0.000 |
| eval/avg_response_length | 3721.462 | 0.000 |
| eval/response_length_std | 2206.426 | 0.000 |
| eval/judgment_entropy | 1.370 | 0.000 |
| eval/most_common_judgment_freq | 0.329 | 0.000 |
| eval/format_error_rate | 0.000 | 0.000 |
| eval/avg_ties_rating | 4.032 | 0.000 |
| eval/ties_error_rate | 0.001 | 0.000 |
| eval/percent_correct_Factuality | 0.606 | 0.000 |
| eval/percent_correct_Precise IF | 0.456 | 0.000 |
| eval/percent_correct_Math | 0.874 | 0.000 |
| eval/percent_correct_Safety | 0.727 | 0.000 |
| eval/percent_correct_Focus | 0.851 | 0.000 |
| eval/percent_correct_Ties | 0.990 | 0.000 |
| eval/choice_samples | 1763.000 | 0.000 |
| eval/ties_samples | 102.000 | 0.000 |
| eval/choice_format_compliance_rate | 1.000 | 0.000 |
| eval/ties_format_compliance_rate | 1.000 | 0.000 |
| eval/wrong_answer_a_bias_rate | 0.447 | 0.000 |
| eval/wrong_answer_total_count | 494.000 | 0.000 |
| eval/wrong_answer_a_count | 221.000 | 0.000 |
**Model:** qwen14b-arena-think
**Evaluation Time (hh:mm:ss):** 00:07:57
**Temperature:** 0.6
**Overlong samples:** 0.0% (0 / 1865)
### simpleqa_nous
| Metric | Score | Std Error |
|--------|-------|----------|
| exact_match | 0.040 | 0.003 |
| fuzzy_match | 0.056 | 0.004 |
**Model:** Qwen3-14B-reasoning
**Evaluation Time (hh:mm:ss):** 00:18:46
**Temperature:** 0.6
**Overlong samples:** 0.1% (3 / 4321)
# 14b-reasoning 评测结果
## 评测总结
| 评测基准 | 得分 | 评测指标 | 样本数 | 超长样本占比 |
|-----------|-------|--------|---------|---------------|
| aime24 | 0.776 | math_pass@1:64_samples | 64 | 0.6% |
| aime25 | 0.685 | math_pass@1:64_samples | 64 | 1.2% |
| arenahard | 0.878 | eval/overall_winrate | 500 | 0.0% |
| bbh_generative | 0.866 | extractive_match | 1 | 0.0% |
| creative-writing-v3 | 0.666 | creative_writing_score | 96 | 0.0% |
| drop_generative_nous | 0.894 | drop_acc | 1 | 0.0% |
| eqbench3 | 0.748 | eqbench_score | 135 | 0.0% |
| gpqa_diamond | 0.620 | gpqa_pass@1:8_samples | 8 | 0.2% |
| ifeval | 0.916 | inst_level_loose_acc | 1 | 0.7% |
| lcb-v6-aug2024+ | 0.612 | eval/pass_1 | 1 | 0.5% |
| math_500 | 0.972 | math_pass@1:4_samples | 4 | 0.1% |
| mmlu_generative | 0.847 | extractive_match | 1 | 0.0% |
| mmlu_pro | 0.775 | pass@1:1_samples | 1 | 0.0% |
| musr_generative | 0.662 | extractive_match | 1 | 0.0% |
| obqa_generative | 0.964 | extractive_match | 1 | 0.0% |
| rewardbench | 0.735 | eval/percent_correct | 1 | 0.0% |
| simpleqa_nous | 0.056 | fuzzy_match | 1 | 0.1% |
超长样本占比:91 / 64,523 个样本(0.1%)缺失闭合标签`</think>`
## 详细评测结果
### aime24
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| math_pass@1:1_samples | 0.767 | 0.079 |
| math_pass@1:4_samples | 0.792 | 0.065 |
| math_pass@1:8_samples | 0.779 | 0.065 |
| math_pass@1:16_samples | 0.777 | 0.067 |
| math_pass@1:32_samples | 0.779 | 0.065 |
| math_pass@1:64_samples | 0.776 | 0.066 |
**模型:** 14b-reasoning
**评测耗时(时:分:秒):** 00:25:20
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.6% (12 / 1920)
### aime25
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| math_pass@1:1_samples | 0.633 | 0.089 |
| math_pass@1:4_samples | 0.667 | 0.072 |
| math_pass@1:8_samples | 0.671 | 0.067 |
| math_pass@1:16_samples | 0.694 | 0.066 |
| math_pass@1:32_samples | 0.690 | 0.067 |
| math_pass@1:64_samples | 0.685 | 0.067 |
**模型:** 14b-reasoning
**评测耗时(时:分:秒):** 00:30:03
**温度参数(Temperature):** 0.6
**超长样本占比:** 1.2% (23 / 1920)
### arenahard
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| eval/overall_winrate | 0.878 | 0.000 |
| eval/total_samples | 500.000 | 0.000 |
| eval/win_count | 417.000 | 0.000 |
| eval/tie_count | 43.000 | 0.000 |
| eval/loss_count | 40.000 | 0.000 |
| eval/win_rate | 0.834 | 0.000 |
| eval/tie_rate | 0.086 | 0.000 |
| eval/loss_rate | 0.080 | 0.000 |
| eval/winrate_arena-hard-v0.1 | 0.878 | 0.000 |
**模型:** qwen14b-arena-think
**评测耗时(时:分:秒):** 00:04:47
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (0 / 500)
### bbh_generative
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| extractive_match | 0.866 | 0.015 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:22:50
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (1 / 5511)
### creative-writing-v3
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| creative_writing_score | 0.666 | 0.000 |
| num_samples | 96.000 | 0.000 |
**模型:** 14b-reasoning
**评测耗时(时:分:秒):** N/A
**温度参数(Temperature):** N/A
**超长样本占比:** 0.0% (0 / 96)
### drop_generative_nous
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| drop_acc | 0.894 | 0.003 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:38:27
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (0 / 9536)
### eqbench3
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| eqbench_score | 0.748 | 0.000 |
| num_samples | 135.000 | 0.000 |
**模型:** qwen14b-arena-think
**评测耗时(时:分:秒):** N/A
**温度参数(Temperature):** N/A
**超长样本占比:** 0.0% (0 / 135)
### gpqa_diamond
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| gpqa_pass@1:1_samples | 0.626 | 0.034 |
| gpqa_pass@1:4_samples | 0.630 | 0.030 |
| gpqa_pass@1:8_samples | 0.620 | 0.030 |
**模型:** 14b-reasoning
**评测耗时(时:分:秒):** 00:10:03
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.2% (3 / 1584)
### ifeval
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| prompt_level_strict_acc | 0.841 | 0.016 |
| inst_level_strict_acc | 0.892 | 0.000 |
| prompt_level_loose_acc | 0.876 | 0.014 |
| inst_level_loose_acc | 0.916 | 0.000 |
**模型:** Qwen3-14B-reasoning-ifeval-aime
**评测耗时(时:分:秒):** 00:14:45
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.7% (4 / 541)
### lcb-v6-aug2024+
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| eval/pass_1 | 0.612 | 0.000 |
| eval/easy_pass_1 | 0.984 | 0.000 |
| eval/medium_pass_1 | 0.745 | 0.000 |
| eval/hard_pass_1 | 0.319 | 0.000 |
| eval/completion_length | 47016.365 | 0.000 |
**模型:** qwen3-14b-nonreasoning
**评测耗时(时:分:秒):** 02:14:03
**温度参数(Temperature):** N/A
**超长样本占比:** 0.5% (36 / 7264)
### math_500
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| math_pass@1:1_samples | 0.970 | 0.008 |
| math_pass@1:4_samples | 0.972 | 0.006 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:11:07
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.1% (2 / 2000)
### mmlu_generative
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| extractive_match | 0.847 | 0.003 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:55:52
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (2 / 14042)
### mmlu_pro
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| pass@1:1_samples | 0.775 | 0.004 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:53:32
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (5 / 12032)
### musr_generative
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| extractive_match | 0.662 | 0.030 |
**模型:** Qwen3-14B-reasoning-ifeval-aime
**评测耗时(时:分:秒):** 00:04:02
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (0 / 756)
### obqa_generative
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| extractive_match | 0.964 | 0.008 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:02:28
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (0 / 500)
### rewardbench
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| eval/percent_correct | 0.735 | 0.000 |
| eval/total_samples | 1865.000 | 0.000 |
| eval/correct_samples | 1370.000 | 0.000 |
| eval/format_compliance_rate | 1.000 | 0.000 |
| eval/avg_response_length | 3721.462 | 0.000 |
| eval/response_length_std | 2206.426 | 0.000 |
| eval/judgment_entropy | 1.370 | 0.000 |
| eval/most_common_judgment_freq | 0.329 | 0.000 |
| eval/format_error_rate | 0.000 | 0.000 |
| eval/avg_ties_rating | 4.032 | 0.000 |
| eval/ties_error_rate | 0.001 | 0.000 |
| eval/percent_correct_Factuality | 0.606 | 0.000 |
| eval/percent_correct_Precise IF | 0.456 | 0.000 |
| eval/percent_correct_Math | 0.874 | 0.000 |
| eval/percent_correct_Safety | 0.727 | 0.000 |
| eval/percent_correct_Focus | 0.851 | 0.000 |
| eval/percent_correct_Ties | 0.990 | 0.000 |
| eval/choice_samples | 1763.000 | 0.000 |
| eval/ties_samples | 102.000 | 0.000 |
| eval/choice_format_compliance_rate | 1.000 | 0.000 |
| eval/ties_format_compliance_rate | 1.000 | 0.000 |
| eval/wrong_answer_a_bias_rate | 0.447 | 0.000 |
| eval/wrong_answer_total_count | 494.000 | 0.000 |
| eval/wrong_answer_a_count | 221.000 | 0.000 |
**模型:** qwen14b-arena-think
**评测耗时(时:分:秒):** 00:07:57
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.0% (0 / 1865)
### simpleqa_nous
| 评测指标 | 得分 | 标准误差 |
|--------|-------|----------|
| exact_match | 0.040 | 0.003 |
| fuzzy_match | 0.056 | 0.004 |
**模型:** Qwen3-14B-reasoning
**评测耗时(时:分:秒):** 00:18:46
**温度参数(Temperature):** 0.6
**超长样本占比:** 0.1% (3 / 4321)
提供机构:
maas
创建时间:
2025-08-27
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是Qwen3-14B-reasoning模型在多个推理与知识评估基准上的性能测试结果汇总,涵盖数学推理(如AIME、MATH)、常识推理(如BBH)、创造性写作、指令遵循等多个领域。评估结果显示模型在多数任务上表现良好,例如在数学任务MATH_500上得分0.972,在指令遵循任务IFEVAL上得分0.916,但也在部分任务如简单问答上得分较低。数据集提供了详细的指标和样本统计,用于评估模型的综合推理能力。
以上内容由遇见数据集搜集并总结生成


