MichiganNLP/LUCid
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/MichiganNLP/LUCid
下载链接
链接失效反馈官方服务:
资源简介:
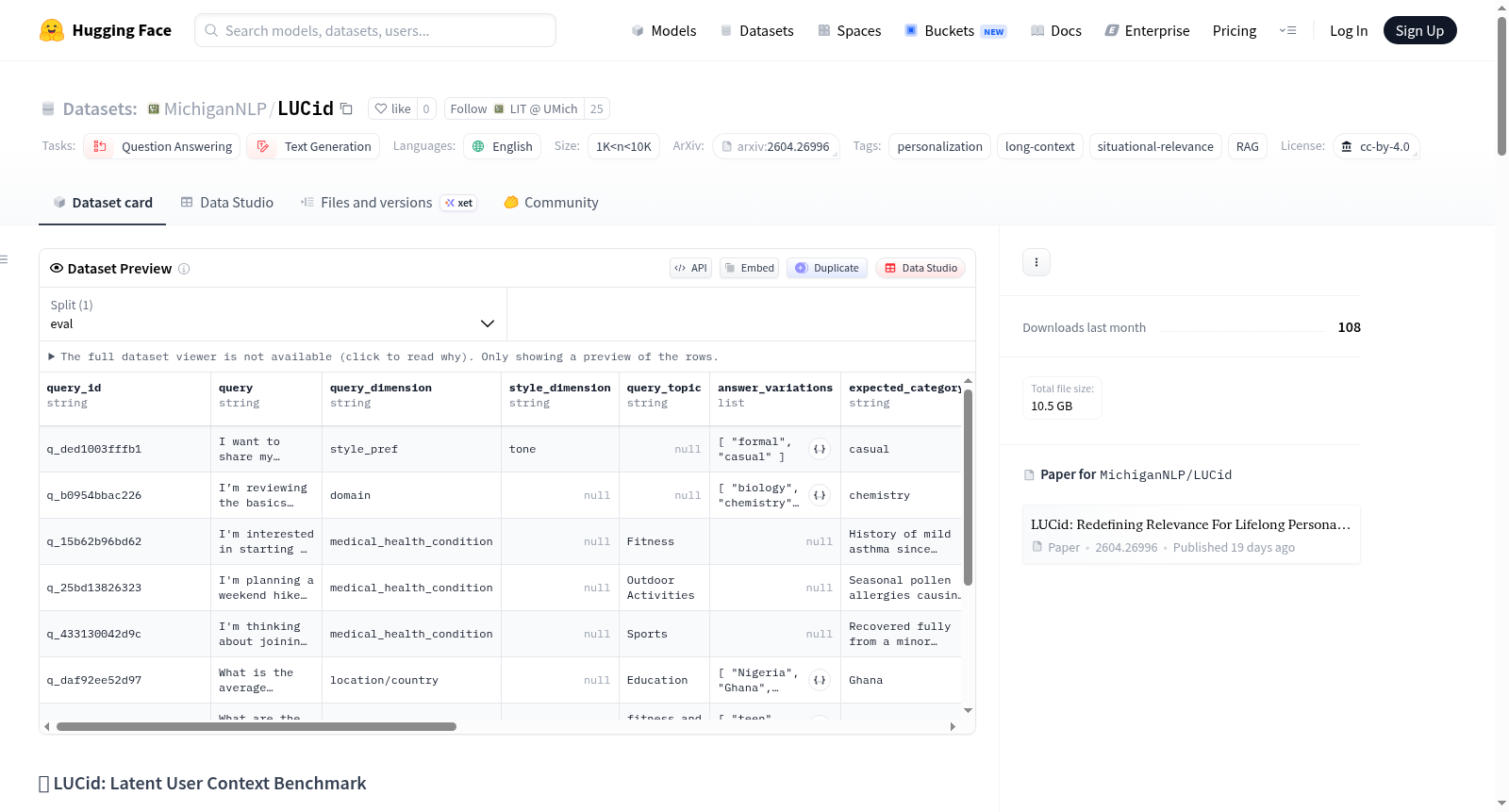
LUCid(潜在用户上下文基准)是一个用于评估终身个性化系统在更现实的相关性概念下表现的数据集。与将相关性与语义相似性等同的传统基准不同,LUCid引入了潜在用户上下文——即与查询语义上相距较远但对生成正确的个性化响应至关重要的信息。该基准旨在测试系统是否能够从长交互历史中检索、推断和利用用户特定信号。数据集包含1,936个查询,交互历史记录最多可达500个会话(约620K tokens),涵盖多个个性化维度,如年龄组、位置/国家、宗教/文化、健康状况等。每个示例要求识别历史中的潜在用户上下文、推断用户属性并生成个性化响应。数据集包含多个变体,对应不同的历史大小和评估设置,如LUCid-5(超短历史设置)、LUCid-10(短历史设置)、LUCid-C(受控重排)、LUCid-S(小规模评估)、LUCid-B(标准基准)和LUCid-L(长上下文压力测试)。数据集格式包括查询ID、查询内容、个性化维度、预期类别等多个字段。
LUCid (Latent User Context benchmark) is a dataset for evaluating lifelong personalization systems under a more realistic notion of relevance. Unlike traditional benchmarks that equate relevance with semantic similarity, LUCid introduces latent user context—information that is semantically distant from the query but crucial for generating the correct personalized response. The benchmark is designed to test whether systems can retrieve, infer, and utilize user-specific signals from long interaction histories. The dataset contains 1,936 queries with interaction histories up to 500 sessions (~620K tokens), covering personalization dimensions such as age group, location/country, religion/culture, health conditions, etc. Each example requires identifying latent user context from history, inferring user attributes, and generating a personalized response. The dataset includes multiple benchmark variants corresponding to different history sizes and evaluation settings, such as LUCid-5 (ultra-short history setting), LUCid-10 (short history setting), LUCid-C (controlled reranking), LUCid-S (small-scale evaluation), LUCid-B (standard benchmark), and LUCid-L (long-context stress test). The dataset format includes fields such as query_id, query, query_dimension, expected_category, etc.
提供机构:
MichiganNLP
搜集汇总
数据集介绍
构建方式
LUCid基准数据集通过构建涵盖年龄、地理位置、宗教信仰、健康状况、领域归属及沟通风格等多个维度的用户画像,从长程交互历史中提取与查询语义相异但至关重要的潜在用户上下文。每个样本均包含一条需要个性化响应的用户查询,以及多达500个会话(约62万token)的历史记录,其中仅部分会话携带真实标签。通过人工标注与自动筛选相结合的方式,确保每个实例中的潜在上下文对于生成正确回答不可或缺,从而构建出对终身个性化系统具有真实挑战性的评估框架。
使用方法
研究者可通过Hugging Face上的datasets库直接加载LUCid的全部变体或特定配置,例如使用load_dataset加载默认的'lucid'数据集即一次性获取所有评估样本。若需针对性实验,则可利用data_files参数指定如'lucid_b.json'等文件来加载基础基准或长上下文压力测试变体。每个样本中的haystack_sessions字段提供了完整的用户-助手对话历史,而answer_session_ids与has_answer标签则分别支持检索评估与基于位置的记忆召回分析,便于开展RAG、记忆增强及用户感知建模等方向的研究。
背景与挑战
背景概述
LUCid(Latent User Context benchmark)数据集由Chimaobi Okite、Anika Misra、Joyce Chai和Rada Mihalcea等研究人员于2026年提出,旨在突破传统个性化系统对“相关性”的狭隘定义。在终身个性化这一前沿研究领域中,系统需从用户长期交互历史中捕获并运用潜在用户情境信息,此类信息往往在语义上与当前查询相距甚远,却对生成精准的个性化响应至关重要。该数据集通过包含高达500个会话(约62万token)的交互历史与1936条精心设计的查询,为评估模型在长上下文、检索增强生成及用户建模等方向上的能力提供了标准化基准。LUCid的引入填补了现有评估体系中对情境推理能力检验的空白,对推动个性化人工智能系统的纵深发展具有显著影响。
当前挑战
LUCid数据集所应对的核心挑战在于,现有系统通常仅依赖语义相似性进行信息检索与响应生成,忽视了隐藏在用户历史中的潜在情境信号。具体而言,该数据集要求模型从冗长且嘈杂的对话历史中,准确检索出与当前查询语义迥异却蕴含关键用户属性(如年龄、地域、健康状况等)的会话片段,并据此推理并生成个性化回答。构建过程中,研究人员面临设计多维度、细粒度的潜在用户属性标签(如沟通风格、领域隶属等)的挑战,同时需保证每条查询的潜在情境信息在历史中具有足够区分度,且各变体(LUCid-5至LUCid-L)能覆盖从超短到极长上下文的评估需求,这要求精确控制历史会话长度与证据密度,以有效测试系统在不同情境复杂度下的稳健性。
常用场景
经典使用场景
在个性化对话系统与长上下文理解的研究领域,LUCid数据集被广泛用于评估模型在复杂用户历史交互中挖掘潜在情境信息的能力。与传统仅依赖语义相似度的基准不同,LUCid要求模型从长达数百轮的历史会话中识别出与当前查询语义疏远却至关重要的用户上下文,例如年龄、地理位置、健康状况或沟通风格等潜隐属性。该数据集最经典的使用场景包括对检索增强生成系统进行压力测试,考察其在超长交互历史(最高达62万token)中精准定位关键证据会话的召回能力,以及评估大型语言模型在整合这些分散信息后生成个性化回复的准确性。通过对不同历史长度变体的系统评测,研究者能够细致诊断模型在短时与长时记忆利用上的表现差异。
解决学术问题
LUCid数据集的核心学术贡献在于重新定义了终身个性化场景下的相关性概念,解决了传统检索与生成任务中仅依赖表层语义匹配而忽略用户潜在特质这一根本性缺陷。学术研究中,该数据集主要用以探究以下关键问题:如何从用户的长周期交互历史中抽取与当前查询语义距离较远却是生成正确回复所必需的潜隐上下文;如何设计有效的检索机制,使模型能够从大量会话中准确定位包含关键用户信号的片段;以及如何增强语言模型对用户属性的推理与记忆利用能力。该数据集的提出推动了终身学习、情境感知推理与个性化生成等交叉领域的发展,为构建真正持续适应用户需求的人机交互系统奠定了评测基础。
实际应用
在实际应用层面,LUCid数据集为构建高度个性化的智能助手、健康顾问、教育辅导及跨文化沟通工具提供了关键的评测基准与训练指引。例如,在医疗健康领域,系统需要从用户过往的病史记录与生活习惯中推断其当下症状的潜在原因,而非仅依据当前描述进行泛泛回应;在国际客户服务场景中,智能代理需结合用户所在国家的文化习俗与宗教背景提供合宜建议。LUCid所倡导的潜隐用户上下文理念,推动了搜索引擎、推荐系统与对话机器人从“理解用户说了什么”向“洞悉用户是谁及其所处情境”的范式转变,从而显著提升服务的贴切度与用户满意度。
数据集最近研究
最新研究方向
在终身个性化这一前沿领域,LUCid数据集重新定义了相关性的内涵,推动了从简单语义匹配向深度用户情境推理的范式转变。其核心创新在于引入了“潜在用户上下文”这一概念,即那些与当前查询在语义上相距甚远、但对个性化响应至关重要的用户历史信号。当前研究热点聚焦于利用该基准评估和提升检索增强生成(RAG)与记忆增强的大型语言模型(LLM)系统,在超长交互历史中精准定位、推断并利用细粒度用户属性(如年龄、宗教信仰、健康状况)的能力。LUCid的提出,直接回应了传统推荐与问答系统在面对复杂、长程依赖的用户画像时表现出的局限性,为构建真正具备情境理解能力的、可持续演进的个性化AI智能体提供了关键性的验证与引导框架,其影响力已延伸至大模型时代下关于隐私、记忆与身份连续性的深层讨论。
以上内容由遇见数据集搜集并总结生成


