chuvash-names
收藏Hugging Face2025-07-28 更新2025-07-29 收录
下载链接:
https://huggingface.co/datasets/rustemgareev/chuvash-names
下载链接
链接失效反馈官方服务:
资源简介:
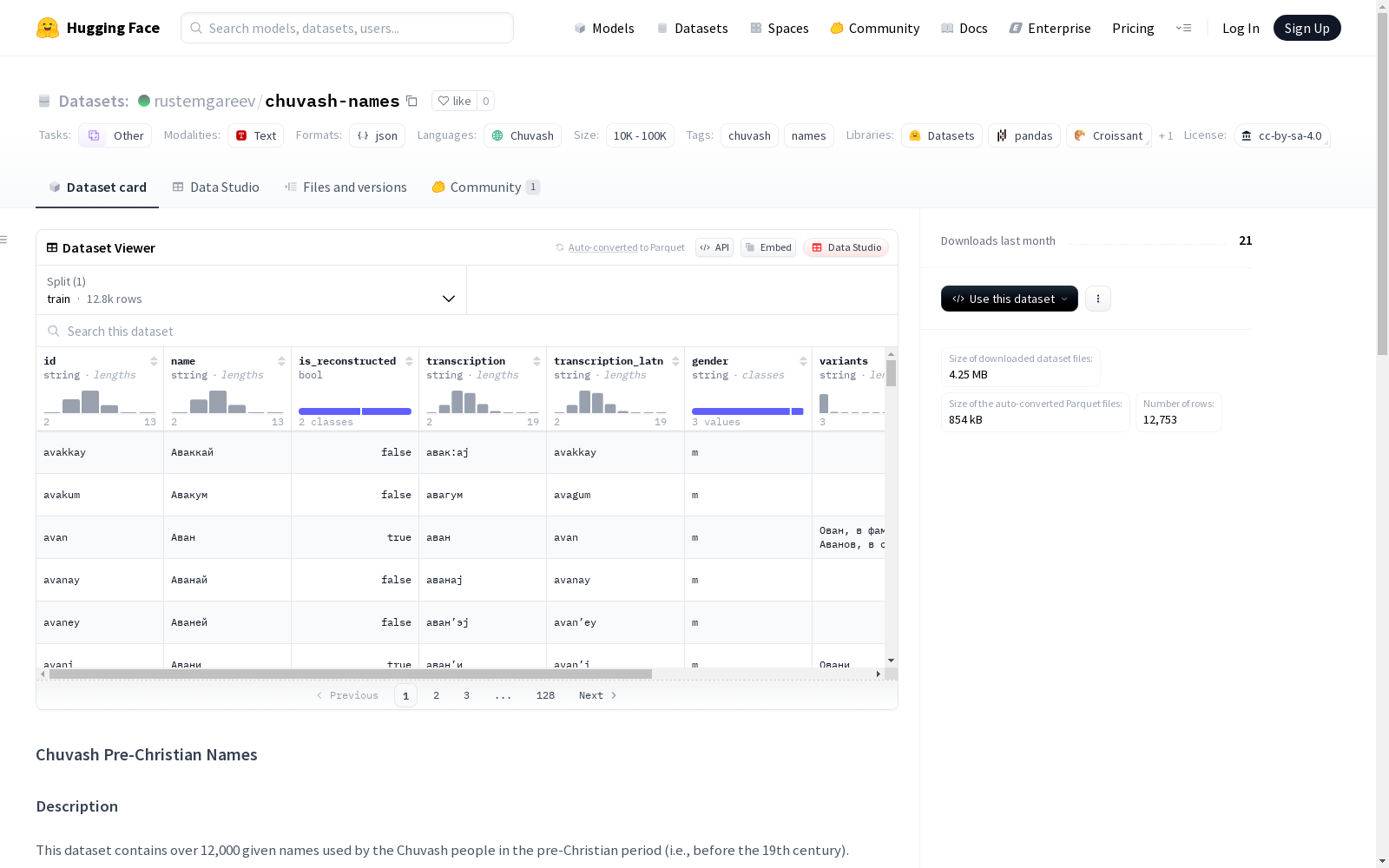
该数据集包含超过12,000个Chuvash人在基督教前期(即19世纪之前)使用的名字。数据集基于《Dictionary of Chuvash Anthroponyms of the Pre-Christian Era》制作,每个记录包含名字的拉丁脚本唯一标识符、斯拉夫脚本名称、是否为语言学重构的标记、音标转录、拉丁音标转录、性别、拼写变体、词源和来源信息。
创建时间:
2025-07-26
原始信息汇总
Chuvash Pre-Christian Names 数据集概述
数据集基本信息
- 语言:楚瓦什语 (cv)
- 许可证:CC BY-SA 4.0
- 标签:楚瓦什语、名字
- 数据集名称:Chuvash Pre-Christian Names
- 规模:10K < n < 100K
- 注释创建者:专家生成
- 语言创建者:发现
- 源数据集:原始数据
- 任务类别:其他
- 配置:默认配置 (default)
- 数据文件:data/chuvash_names.jsonl
- 分割:train (12,753 个样本)
- 下载大小:4,251,417 字节
- 数据集大小:4,251,417 字节
数据集描述
该数据集包含超过12,000个楚瓦什人在前基督教时期(即19世纪之前)使用的名字。基于 "Dictionary of Chuvash Anthroponyms of the Pre-Christian Era" (A.M. Ivanova, E.V. Fomin, 2020)。
数据结构
每条记录为一个JSON对象,包含以下字段:
id(string):拉丁字母的唯一标识符。name(string):西里尔字母的名字。is_reconstructed(boolean):如果名字形式是语言重建,则为true,否则为false。transcription(string):西里尔字母的音标。transcription_latn(string):拉丁字母的音标。gender(string):名字的性别 (m为男性,f为女性,u为双性)。可为null。variants(string):名字的拼写变体。可为null。etymology(字符串列表):包含一个或多个名字来源的版本。source(string):原始信息来源的引用。
使用示例
python from datasets import load_dataset
dataset = load_dataset("rustemgareev/chuvash-names", split=train)
打印第一个示例
print(dataset[0])
示例输出: json { "id": "avakkay", "name": "Аваккай", "is_reconstructed": false, "transcription": "авак:аj", "transcription_latn": "avakkay", "gender": "m", "variants": null, "etymology": ["араб. أب اك ا (Абака) ‘брат отца, друг’ + -ай"], "source": "Ашмарин т. 1, с. 38" }
许可证
该数据集采用 Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) 许可证分发。
搜集汇总
数据集介绍
构建方式
该数据集基于A.M. Ivanova与E.V. Fomin于2020年编纂的《楚瓦什前基督教时期人名辞典》,系统收录了19世纪前楚瓦什民族使用的12,753个传统人名。通过专家人工标注的方式,每个条目均包含西里尔文原始拼写、拉丁转写、性别标记、词源考据及文献来源等多维度信息,并严格区分语言重构形式与现存记录形式,构建过程体现了历史语言学研究的严谨性。
特点
作为目前最全面的楚瓦什前基督教时期人名数据库,该数据集以JSONL格式呈现结构化数据,每条记录包含8个精细标注字段。其独特价值在于完整保留了原始文献中的音标转写系统与多源词源解释,特别是对阿拉伯语等外来语借词的词源追溯。性别标记采用三元分类法(男性/女性/中性),并标注了16.3%的存疑词条,为民族语言学研究提供了珍贵样本。
使用方法
研究者可通过Hugging Face的datasets库直接加载该数据集,调用load_dataset()函数指定'train'分割即可获取完整数据。典型应用场景包括:通过etymology字段进行阿尔泰语系比较语言学研究,利用transcription_latn字段开展音系学分析,或结合gender字段探究古代社会性别文化。输出结果为标准JSON对象,可直接对接主流机器学习框架进行后续处理。
背景与挑战
背景概述
楚瓦什人名数据集(Chuvash Pre-Christian Names)由A.M. Ivanova和E.V. Fomin于2020年基于《楚瓦什前基督教时期人名词典》编纂而成,收录了超过12,000个楚瓦什人在前基督教时期(19世纪前)使用的名字。该数据集不仅为语言学研究者提供了珍贵的原始资料,也为文化人类学和历史学研究开辟了新的视角。楚瓦什语作为突厥语系中的独特分支,其名字系统反映了该民族与周边文化的交融历程,具有重要的学术价值。
当前挑战
该数据集面临的挑战主要体现在两方面:其一,楚瓦什前基督教名字的语源考证涉及多种古代语言,包括阿拉伯语、波斯语等,跨语言词源追溯存在较大难度;其二,原始数据中存在大量基于语言学理论重构的名字形式,如何准确区分历史记载与学术重构成为关键问题。数据集构建过程中,研究人员需克服楚瓦什语古今音系差异带来的转写难题,并解决西里尔字母与拉丁字母双轨转录系统的技术实现问题。
常用场景
经典使用场景
在民族语言学研究领域,Chuvash Pre-Christian Names数据集为探索楚瓦什语的历史演变提供了珍贵素材。研究者通过分析这些前基督教时期的姓名拼写变体、语音转录和词源信息,能够系统性地重构楚瓦什语在接触阿拉伯语、突厥语等外来文化前的原生词汇体系。该数据集特别适用于历时语言学中的音系变迁研究,例如通过对比拉丁转写与西里尔拼写的对应关系,揭示楚瓦什语辅音系统的演化规律。
解决学术问题
该数据集有效解决了乌拉尔语系研究中语料匮乏的核心问题。其精确标注的词源信息为阿尔泰语系与乌拉尔语系的亲缘关系研究提供了实证材料,而性别标记与重构标识则助力于社会语言学中命名习俗与性别文化的研究。通过12753条带有语言学注释的姓名记录,学者们能够验证关于楚瓦什民族迁徙路线、宗教文化影响等历史假设,填补了欧亚大陆少数民族语言研究的空白。
衍生相关工作
基于该数据集衍生的经典研究包括《楚瓦什语突厥借词分层分析》,该工作通过姓名词源字段系统量化了不同历史时期的语言接触强度。另有关键成果是开发了首个楚瓦什语历史音变模拟器,利用数据集的转录字段训练神经网络,成功预测了未记录的音系演变路径。这些工作共同推动了计算历史语言学在少数民族语言研究中的应用范式革新。
以上内容由遇见数据集搜集并总结生成


