massw
收藏Hugging Face2024-10-22 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/jimmyzxj/massw
下载链接
链接失效反馈官方服务:
资源简介:
MASSW是一个关于多方面科学工作流总结的综合文本数据集。它包含了超过152,000篇来自17个领先计算机科学会议的同行评审出版物,时间跨度为过去50年。数据集定义了科学工作流的五个核心方面:上下文、关键思想、方法、结果和预期影响,并通过使用大型语言模型(LLMs)系统地从每篇出版物中提取和结构化这些方面。MASSW不仅规模大,而且准确性高,经过全面检查和与人工注释及替代方法的比较验证。此外,MASSW支持多种新颖和可基准化的机器学习任务,如想法生成和结果预测,为评估LLM代理在科学研究中的能力提供了基准。
创建时间:
2024-10-22
原始信息汇总
MASSW 数据集概述
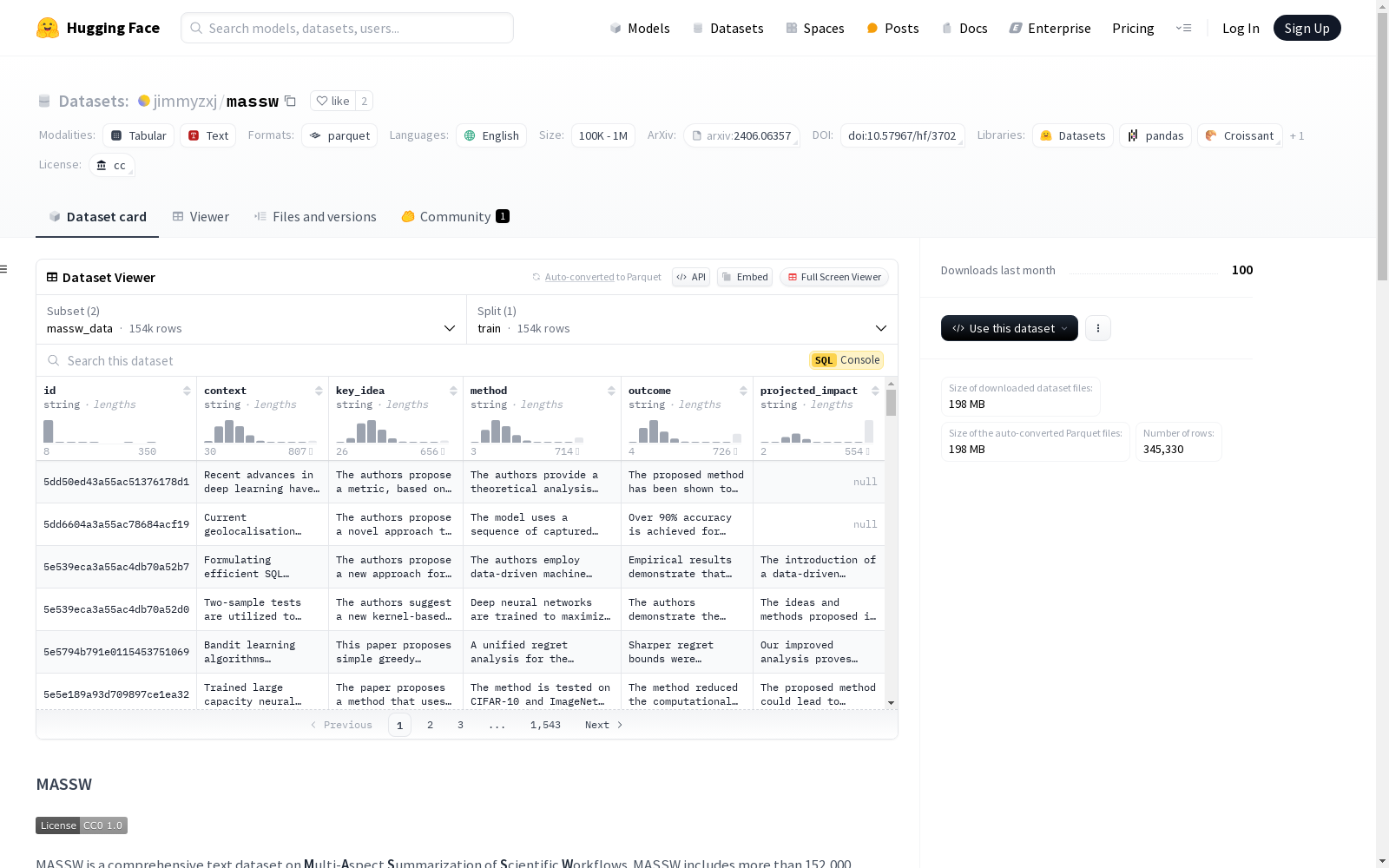
数据集信息
配置 massw_data
- 特征:
id: 字符串context: 字符串key_idea: 字符串method: 字符串outcome: 字符串projected_impact: 字符串
- 分割:
train:num_bytes: 153085133num_examples: 154275
- 下载大小: 86202576
- 数据集大小: 153085133
配置 massw_metadata
- 特征:
id: 字符串venue: 字符串title: 字符串year: 整数partition: 字符串abstract: 字符串
- 分割:
train:num_bytes: 178427074num_examples: 191055
- 下载大小: 97735018
- 数据集大小: 178427074
数据集特点
- 结构化科学工作流程: 包含五个核心方面:context(背景)、key idea(关键思想)、method(方法)、outcome(结果)、projected impact(预期影响)。
- 大规模: 包含超过152,000篇同行评审出版物,涵盖17个领先的计算机科学会议,时间跨度超过50年。
- 准确性: 通过全面检查和与人工注释及替代方法的比较验证了覆盖率和准确性。
- 丰富的基准任务: 支持多种机器学习任务,如想法生成和结果预测。
核心方面定义
| 方面 | 定义 | 示例 |
|---|---|---|
| Context | 相关文献或现实的现状,通常是一个问题、研究问题或未被成功解决的研究空白。 | Making language models bigger does not inherently make them better at following a users intent, as large models can generate outputs that are untruthful, toxic, or not helpful. |
| Key Idea | 论文的主要智力贡献,通常是与背景相比的新颖想法或解决方案。 | The authors propose InstructGPT, a method to align language models with user intent by fine-tuning GPT-3 using a combination of supervised learning with labeler demonstrations and reinforcement learning from human feedback. |
| Method | 验证关键思想的具体研究方法,可能是实验设置、理论框架或其他必要的验证方法。 | The authors evaluate the performance of InstructGPT by humans on a given prompt distribution and compare it with a much larger model GPT-3. |
| Outcome | 研究输出的客观陈述,可能是实验结果或其他可测量的结果。 | InstructGPT, even with 100x fewer parameters, is preferred over GPT-3 in human evaluations. It shows improvements in truthfulness and reductions in toxic outputs with minimal performance regressions on public NLP datasets. |
| Projected Impact | 作者预期的研究对领域的影响,以及作者识别的可能改进或扩展该研究的潜在进一步研究。 | Fine-tuning with human feedback is a promising direction for aligning language models with human intent. |
覆盖范围
- 涵盖17个领先的计算机科学会议,包括:
- 人工智能:AAAI, IJCAI
- 计算机视觉:CVPR, ECCV, ICCV
- 机器学习:ICLR, ICML, NeurIPS, KDD
- 自然语言处理:ACL, EMNLP, NAACL
- 网络与信息检索:SIGIR, WWW
- 数据库:SIGMOD, VLDB
- 跨学科领域:CHI
引用
bibtex @article{zhang2024massw, title={MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Scientific Workflows}, author={Zhang, Xingjian and Xie, Yutong and Huang, Jin and Ma, Jinge and Pan, Zhaoying and Liu, Qijia and Xiong, Ziyang and Ergen, Tolga and Shim, Dongsub and Lee, Honglak and others}, journal={arXiv preprint arXiv:2406.06357}, year={2024} }
搜集汇总
数据集介绍
构建方式
MASSW数据集的构建基于对超过152,000篇同行评审的计算机科学领域文献的系统性分析,涵盖了17个顶级会议过去50年的研究成果。通过利用大语言模型(LLMs),研究团队从每篇文献中提取并结构化五个核心科学工作流要素:背景、关键思想、方法、结果和预期影响。这一过程不仅确保了数据的全面性,还通过人工标注和对比验证了数据的准确性。
使用方法
MASSW数据集支持多种机器学习和自然语言处理任务,如关键思想生成和结果预测。研究人员可以利用该数据集进行科学工作流的核心要素预测、推荐和扩展等任务,从而评估大语言模型在科学研究中的表现。数据集的结构化设计使其能够灵活应用于不同任务,为科学工作流的自动化处理提供了丰富的实验平台。
背景与挑战
背景概述
MASSW数据集由Xingjian Zhang等研究人员于2024年提出,旨在为人工智能辅助的科学工作流提供多方面的总结与基准任务。该数据集涵盖了超过15万篇来自17个顶级计算机科学会议的同行评审论文,时间跨度长达50年。MASSW的核心研究问题在于如何从科学文献中系统提取并结构化科学工作流的五个关键方面:背景、关键思想、方法、结果和预期影响。这一数据集不仅为科学工作流的自动化分析提供了丰富的资源,还为机器学习任务如思想生成和结果预测提供了新的基准。MASSW的发布对计算机科学领域的研究方法和技术发展产生了深远影响,特别是在自然语言处理和人工智能辅助研究工具的开发方面。
当前挑战
MASSW数据集在构建过程中面临多重挑战。首先,科学文献的多样性和复杂性使得从大量文本中准确提取结构化信息变得极为困难,尤其是在确保提取的五个关键方面(背景、关键思想、方法、结果和预期影响)的准确性和一致性方面。其次,数据集的规模庞大,涵盖了50年的文献,如何高效处理和管理这些数据也是一个技术难题。此外,尽管MASSW通过大规模语言模型(LLMs)进行信息提取,但其结果的准确性仍需通过人工注释和对比验证来确保,这一过程耗时且资源密集。最后,MASSW的应用场景广泛,如何设计有效的基准任务以评估模型在科学工作流中的表现,也是一个需要深入研究的挑战。
常用场景
经典使用场景
MASSW数据集在科学工作流的多方面摘要任务中展现了其经典应用场景。通过提取和结构化科学文献中的上下文、关键思想、方法、结果和预期影响,该数据集为研究人员提供了一个全面的框架,用于理解和分析科学研究的各个阶段。这种结构化的数据不仅有助于深入挖掘科学文献的内在逻辑,还为自动化摘要生成和科学工作流分析提供了坚实的基础。
解决学术问题
MASSW数据集解决了科学文献分析中的多个学术研究问题。首先,它通过系统化地提取科学工作流的五个核心方面,帮助研究人员更清晰地理解科学研究的全貌。其次,该数据集为机器学习任务提供了丰富的基准,如思想生成和结果预测,推动了自然语言处理领域的发展。此外,MASSW的高准确性和大规模覆盖范围,使其成为评估大语言模型在科学研究中应用能力的重要工具。
实际应用
在实际应用中,MASSW数据集被广泛用于自动化科学文献摘要生成、科研工作流优化和学术研究推荐系统。通过利用该数据集的结构化信息,研究人员可以快速获取科学文献的核心内容,提高文献阅读和理解的效率。此外,MASSW还为科研机构和企业提供了科学工作流分析和预测的工具,帮助其更好地规划和管理科研项目。
数据集最近研究
最新研究方向
在人工智能辅助科学工作流程领域,MASSW数据集为多维度科学工作流摘要提供了新的研究视角。该数据集通过结构化科学工作流程的五个核心方面——背景、关键思想、方法、结果和预期影响,为研究者提供了丰富的文本资源。近年来,随着大语言模型(LLMs)的快速发展,MASSW数据集在科学工作流程的自动摘要、关键思想生成和结果预测等任务中展现出巨大潜力。特别是在跨学科研究中,MASSW数据集的应用不仅推动了科学工作流程的自动化处理,还为科学研究的创新和效率提升提供了新的方法论支持。此外,该数据集覆盖了计算机科学领域的多个顶级会议,为跨领域研究提供了广泛的数据基础,进一步促进了人工智能在科学研究中的应用与拓展。
以上内容由遇见数据集搜集并总结生成


