azerbaijani-tts-dataset-audio
收藏Hugging Face2026-02-05 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/ugu99/azerbaijani-tts-dataset-audio
下载链接
链接失效反馈官方服务:
资源简介:
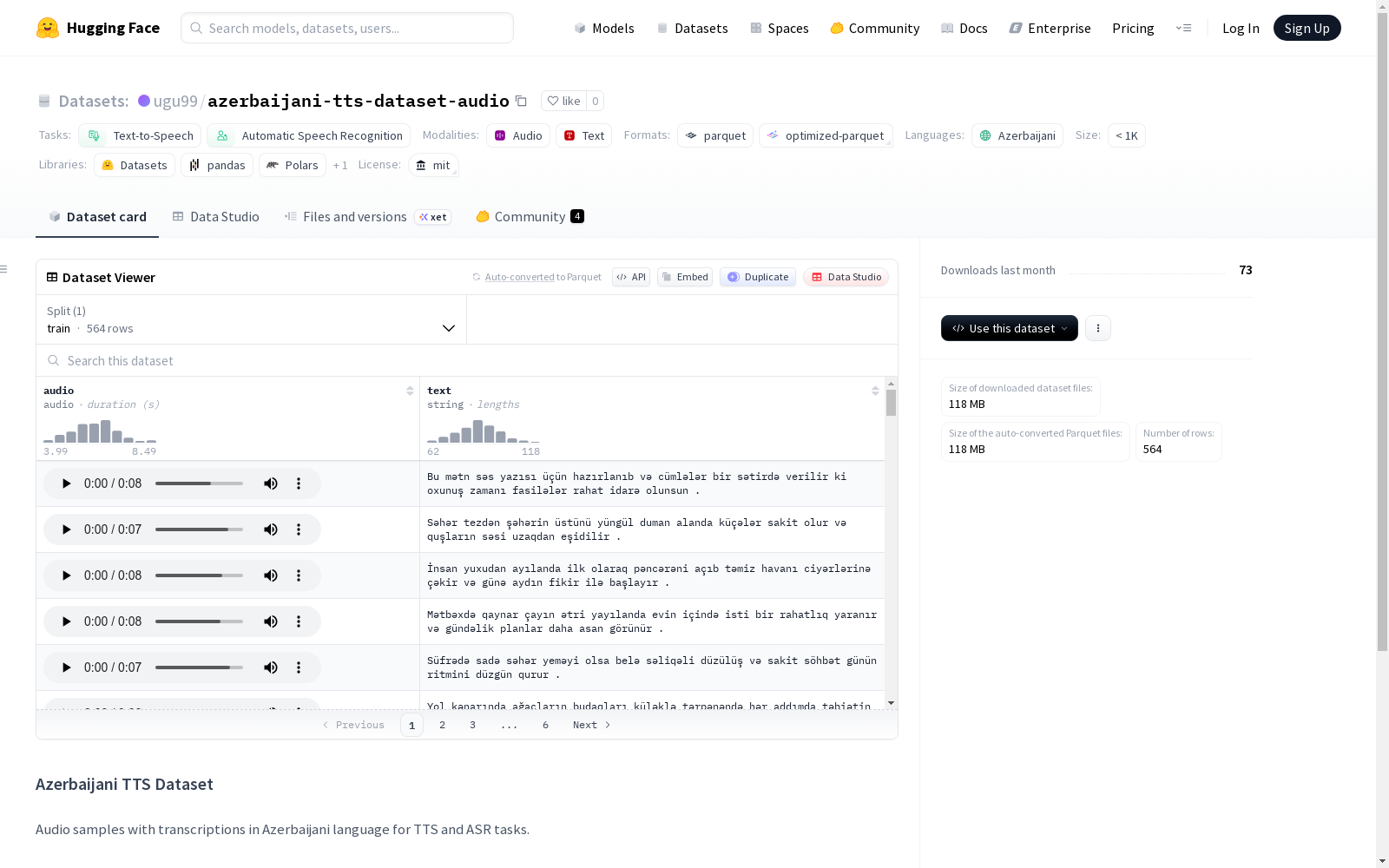
该数据集包含音频-文本配对数据,由564个训练样本组成,总大小约163.76MB。每个样本包含两个字段:'audio'(音频格式)和'text'(字符串格式)。数据集采用单一训练集划分,未提供验证或测试集。数据文件存储路径遵循'train-*'的命名模式。未提供关于数据来源、采集方式或具体应用场景的说明。
This dataset contains audio-text paired samples, totaling 564 training instances with an overall size of approximately 163.76 MB. Each sample includes two fields: 'audio' (stored in audio format) and 'text' (stored as a string). The dataset employs a single training set partition, with no separate validation or test subsets provided. The data files adhere to the naming convention 'train-*' for their storage paths. No descriptions related to data sources, collection procedures, or specific application scenarios are included in the dataset.
创建时间:
2026-02-04
搜集汇总
数据集介绍
构建方式
在语音合成与识别研究领域,高质量语音数据的获取是技术发展的基石。该数据集通过系统采集阿塞拜疆语母语者的语音样本,并辅以精准的文本转录构建而成。其构建过程注重语音的清晰度与文本的准确性,确保了数据在声学特征与语言内容上的一致性,为相关模型训练提供了可靠的基础资源。
特点
本数据集的核心特点在于其专注于阿塞拜疆语这一特定语言,填补了该语种公开语音数据的空白。数据集包含了经过严格对齐的音频文件与对应文本转录,格式规范,便于直接用于模型训练与评估。其内容设计兼顾了语音合成与自动语音识别双重任务的需求,具有明确的应用指向性。
使用方法
研究人员可通过Hugging Face的`datasets`库便捷地加载此数据集。使用指定代码即可获取训练集分割,从而直接将其整合到模型训练流程中。该数据集适用于构建或微调阿塞拜疆语的文本转语音模型或语音识别模型,为相关算法的开发与性能验证提供了即用的数据支持。
背景与挑战
背景概述
在语音技术领域,低资源语言的数据稀缺问题长期制约着相关模型的开发与应用。Azerbaijani TTS Dataset由研究人员或机构创建,旨在为阿塞拜疆语这一资源相对匮乏的语言提供高质量的文本到语音合成与自动语音识别数据。该数据集聚焦于解决阿塞拜疆语语音处理中的核心研究问题,通过收集带有转录的音频样本,为构建鲁棒的语音模型奠定基础,对推动多语言语音技术发展具有积极影响力。
当前挑战
该数据集致力于应对阿塞拜疆语文本到语音合成与自动语音识别任务中的挑战,包括处理语言的音韵复杂性、口音多样性以及数据标注的一致性。在构建过程中,挑战主要源于高质量音频采集的难度、转录文本的准确性验证,以及确保数据规模与代表性之间的平衡,这些因素共同影响了数据集的实用性与泛化能力。
常用场景
经典使用场景
在语音技术领域,阿塞拜疆语作为突厥语系的重要分支,其语音资源相对稀缺。该数据集专为文本到语音合成任务设计,提供了高质量的音频样本与对应转录文本,为研究人员构建和优化阿塞拜疆语TTS模型奠定了数据基础。通过利用这些对齐的语音-文本对,可以训练端到端的神经语音合成系统,生成自然流畅的阿塞拜疆语语音,有效填补了该语言在语音合成研究中的空白。
实际应用
在实际应用层面,基于该数据集开发的语音合成技术能够集成到多种产品与服务中。例如,它可以赋能智能助手、有声读物、导航系统以及教育软件,为阿塞拜疆语使用者提供更便捷的信息获取与交互体验。在媒体广播、公共信息播报等领域,自动化语音生成也能提升内容生产效率。这些应用不仅服务于日常生活,也对保护和推广阿塞拜疆语数字文化具有积极意义。
衍生相关工作
围绕该数据集,研究社区已经催生了一系列经典工作。早期研究侧重于利用其构建基础的拼接式或统计参数式TTS系统。随着深度学习兴起,后续工作广泛采用如Tacotron、FastSpeech等先进架构,在该数据上训练并评估性能。同时,它也常被用作基准,用于比较不同语音合成模型在低资源场景下的效果,相关成果已发表在语音技术顶级会议中,持续推动着该领域的方法创新。
以上内容由遇见数据集搜集并总结生成


