有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
MLDR(Multilingual Long-Document Retrieval)
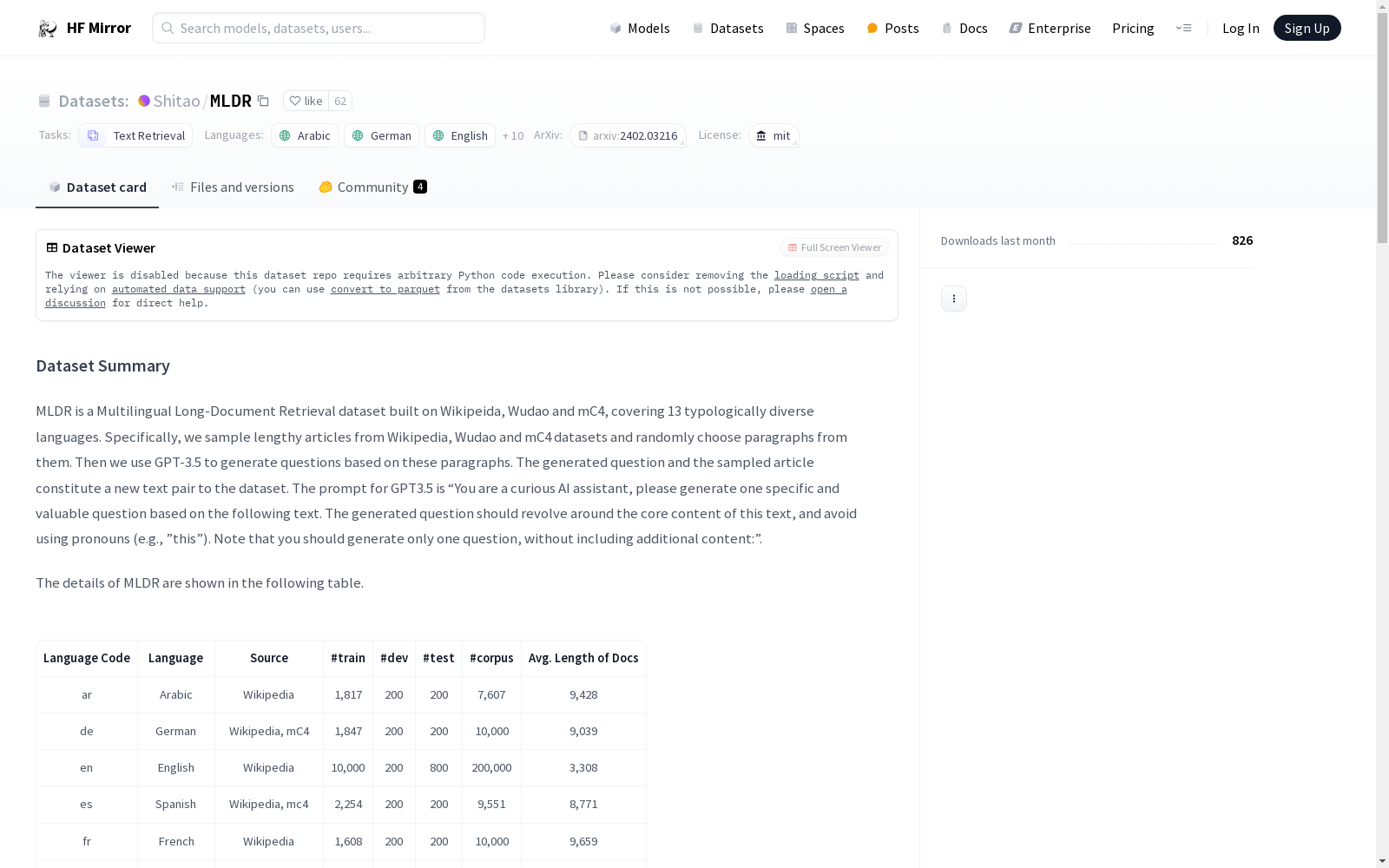
MLDR是一个多语言长文档检索数据集,基于Wikipedia、Wudao和mC4构建,涵盖13种语言。数据集通过从这些源数据集中随机抽取长篇文章的段落,并使用GPT-3.5生成基于这些段落的具体问题。生成的每个问题与其对应的段落文章构成数据集中的一个文本对。
数据集支持以下13种语言:
数据集分为train, dev, 和 test三个部分,每个部分包含以下字段:
query_id: 查询IDquery: 生成的查询问题positive_passages: 包含正确答案的段落negative_passages: 不包含正确答案的段落(仅在训练集中有)| Language Code | Language | Source | #train | #dev | #test | #corpus | Avg. Length of Docs |
|---|---|---|---|---|---|---|---|
| ar | Arabic | Wikipedia | 1,817 | 200 | 200 | 7,607 | 9,428 |
| de | German | Wikipedia, mC4 | 1,847 | 200 | 200 | 10,000 | 9,039 |
| en | English | Wikipedia | 10,000 | 200 | 800 | 200,000 | 3,308 |
| es | Spanish | Wikipedia, mC4 | 2,254 | 200 | 200 | 9,551 | 8,771 |
| fr | French | Wikipedia | 1,608 | 200 | 200 | 10,000 | 9,659 |
| hi | Hindi | Wikipedia | 1,618 | 200 | 200 | 3,806 | 5,555 |
| it | Italian | Wikipedia | 2,151 | 200 | 200 | 10,000 | 9,195 |
| ja | Japanese | Wikipedia | 2,262 | 200 | 200 | 10,000 | 9,297 |
| ko | Korean | Wikipedia | 2,198 | 200 | 200 | 6,176 | 7,832 |
| pt | Portuguese | Wikipedia | 1,845 | 200 | 200 | 6,569 | 7,922 |
| ru | Russian | Wikipedia | 1,864 | 200 | 200 | 10,000 | 9,723 |
| th | Thai | mC4 | 1,970 | 200 | 200 | 10,000 | 8,089 |
| zh | Chinese | Wikipedia, Wudao | 10,000 | 200 | 800 | 200,000 | 4,249 |
| Total | - | - | 41,434 | 2,600 | 3,800 | 493,709 | 4,737 |
MIT License
CatMeows
该数据集包含440个声音样本,由21只属于两个品种(缅因州库恩猫和欧洲短毛猫)的猫在三种不同情境下发出的喵声组成。这些情境包括刷毛、在陌生环境中隔离和等待食物。每个声音文件都遵循特定的命名约定,包含猫的唯一ID、品种、性别、猫主人的唯一ID、录音场次和发声计数。此外,还有一个额外的zip文件,包含被排除的录音(非喵声)和未剪辑的连续发声序列。
huggingface 收录
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
MECCANO
MECCANO数据集是首个专注于工业类似环境中第一人称视角下人类-物体交互的研究数据集。该数据集由20名参与者在模拟工业场景中构建摩托车玩具模型的视频组成,包含299,376帧视频数据。数据集不仅标注了时间上的动作片段,还标注了空间上的活跃物体边界框,涵盖了12种动词、20种名词和61种独特动作的分类。MECCANO数据集旨在推动工业环境中第一人称视角下人类动作识别、活跃物体检测、活跃物体识别及第一人称视角下人类-物体交互检测等任务的研究。
arXiv 收录
UCI Wine
UCI Wine数据集包含了178个样本,每个样本有13个特征,用于分类任务。这些特征包括葡萄酒的化学成分,如酒精含量、苹果酸、灰分等。数据集的目标是将葡萄酒分类为三个不同的品种。
archive.ics.uci.edu 收录