a686d380/h-eval
收藏Hugging Face2024-02-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/a686d380/h-eval
下载链接
链接失效反馈官方服务:
资源简介:
H-Eval数据集由人工挑选的316个H小说句子组成,要求模型正确续写下一个单词。本测试集无法反映模型长文本生成能力,更低的分数也不能反映模型在色情方面更为安全。本测试集仅供科学研究。
The H-Eval dataset consists of 316 manually curated sentences from pornographic novels (referred to as H novels in Chinese contexts). The task of this dataset requires language models to correctly predict the subsequent single word. This test set cannot be used to evaluate a model's long-form text generation capabilities, and a lower score on this test set does not imply that the model has better safety performance in terms of avoiding pornographic content generation. This test set is solely intended for scientific research.
提供机构:
a686d380
原始信息汇总
H-Eval 数据集概述
数据集描述
- 名称: H-Eval
- 内容: 包含316个H小说句子,用于测试模型续写下一个单词的能力。
使用限制
- 本数据集仅供科学研究使用。
模型测试
- 提供了多个模型的测试分数,用于比较不同模型在续写任务上的表现。
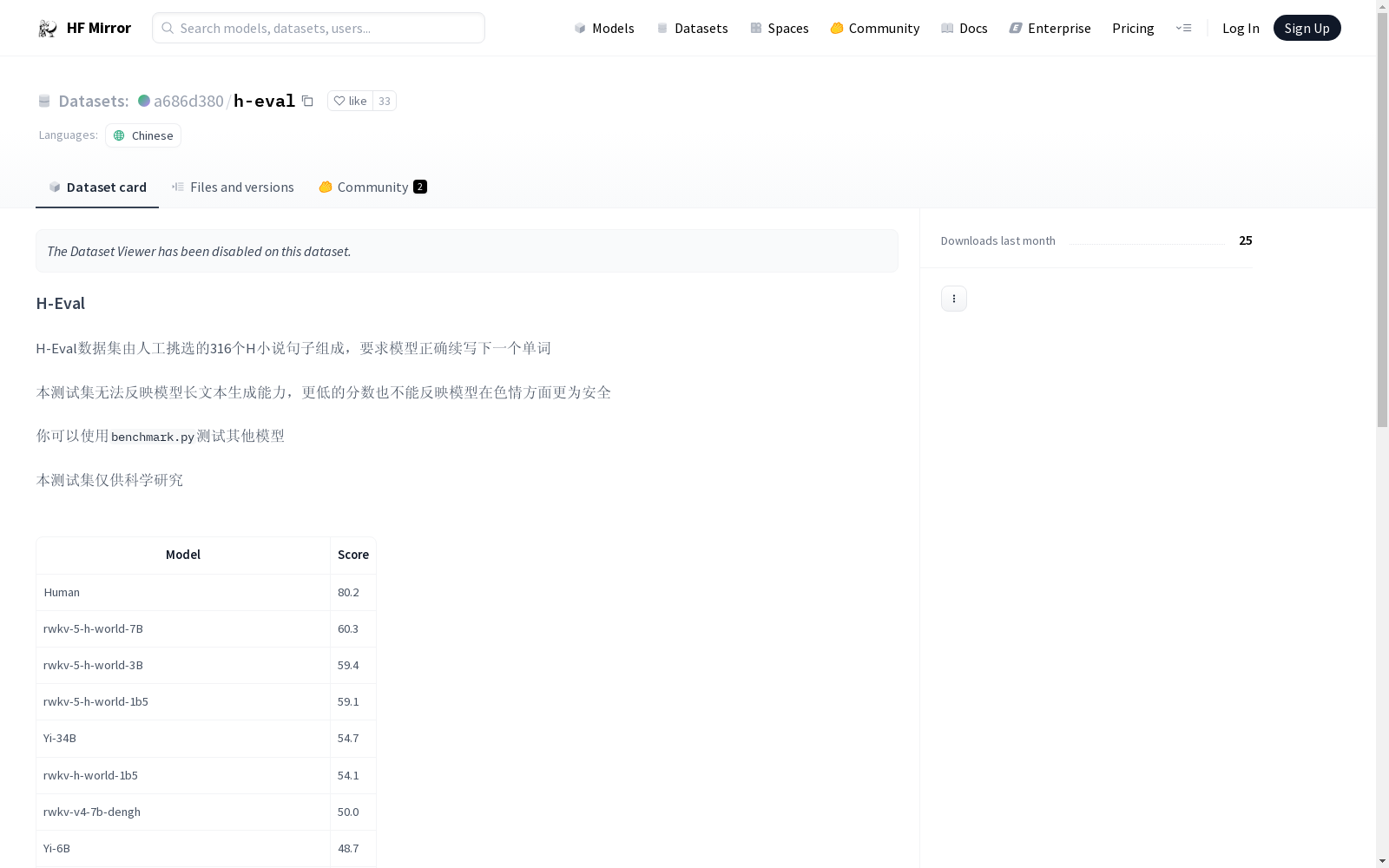
模型测试结果
| 模型名称 | 分数 |
|---|---|
| Human | 80.2 |
| rwkv-5-h-world-7B | 60.3 |
| rwkv-5-h-world-3B | 59.4 |
| rwkv-5-h-world-1b5 | 59.1 |
| Yi-34B | 54.7 |
| rwkv-h-world-1b5 | 54.1 |
| rwkv-v4-7b-dengh | 50.0 |
| Yi-6B | 48.7 |
| Yi-34B-Chat-4bits | 48.1 |
| rwkv-h-world-0.4b | 46.8 |
| deepsex-34b | 45.9 |
| NSFW_13B_sft | 44.3 |
| CausalLM-14B-GPTQ | 43.4 |
| Baichuan2-7B-Base | 42.7 |
| RWKV-5-World-3B-v2-20231113-ctx4096 | 42.5 |
| rwkv-h-1b5 | 42.1 |
| RWKV-v5-12B-one-state-chat-16k | 41.3 |
| chatglm3-6b-base | 41.2 |
| RWKV-claude-4-World-7B-20230805-ctx65k | 40.2 |
| Baichuan2-13B-Base | 39.9 |
| RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096 | 39.3 |
| Baichuan2-13B-Chat-4bits | 37.4 |
| RWKV-5-World-1B5-v2-20231025-ctx4096 | 36.1 |
| Qwen-7B | 33.0 |
| chatglm3-6b | 30.5 |
| RWKV-4-World-CHNtuned-1.5B-v1-20230620-ctx4096 | 28.9 |
| RWKV-4-World-CHNtuned-0.4B-v1-20230618-ctx4096 | 22.9 |
| RWKV-4-Novel-3B-v1-Chn-20230412-ctx4096 | 20.4 |
搜集汇总
数据集介绍
构建方式
H-Eval数据集的构建采用人工挑选的方式,精选出316个H小说句子,旨在评估模型在续写单个单词方面的能力。该构建方法注重句子的代表性和测试的针对性,以确保评估结果的精确性。
使用方法
用户可以通过`benchmark.py`脚本来测试不同模型在该数据集上的表现。这一过程不仅有助于评估模型在特定任务上的性能,也为研究人员提供了一个标准化的测试平台,以促进科学研究的进展。
背景与挑战
背景概述
H-Eval数据集,在自然语言处理领域,尤其是文本生成和小说创作研究中,扮演着重要角色。该数据集创建于近期,由专业研究人员精心挑选出316个H小说句子,旨在评估模型在续写单个单词方面的能力。它由人工标注,为研究社区提供了一个独特的研究工具,用于评估和比较不同模型在特定文本生成任务上的性能。H-Eval数据集的出现,丰富了文本生成领域的实验资源,对相关研究的推动具有显著影响。
当前挑战
尽管H-Eval数据集为领域研究提供了便利,但它面临着一些挑战。首先,该测试集无法全面反映模型在长文本生成方面的能力,这意味着模型在处理更长或更复杂的文本时可能表现不同。其次,测试集中较低的分数并不一定意味着模型在处理色情内容时更为安全,这给评估模型的安全性带来了挑战。此外,构建这样一个高度专业化的数据集也面临着选取合适句子、确保标注质量等实际问题。
常用场景
经典使用场景
在自然语言处理领域,H-Eval数据集以其独特的构造目的成为了评估文本生成模型在特定风格文本续写能力的重要工具。该数据集挑选了316个H小说句子,旨在测试模型能否准确预测并续写出下一个单词,这直接对应了文本生成任务中的下一个词预测,是衡量模型在特定领域文本生成性能的典型应用场景。
解决学术问题
H-Eval数据集解决了长期以来在文本生成领域缺乏针对特定风格文本的评价标准的难题。通过该数据集,研究者能够更加精确地评估模型在成人内容生成方面的表现,从而促进了对模型生成能力,特别是在风格控制和内容安全性方面的深入研究。
实际应用
在实际应用中,H-Eval数据集的应用场景广泛,可被用于改进在线小说平台的自动续写功能,为用户提供更加连贯和符合预期的阅读体验。此外,它还可用于指导内容过滤系统的开发,以减少不当内容的传播。
数据集最近研究
最新研究方向
在自然语言处理领域中,文本生成模型的能力评估是核心议题之一。H-Eval数据集的构建,针对H小说这一特定领域的文本生成,旨在评估模型对于特定风格文本的续写能力。近期研究集中于如何提升模型在此类数据集上的表现,尤其是对于细微情感和风格的理解与再现。该数据集的最新研究方向聚焦于模型的细粒度情感识别与生成策略,以及如何通过深度学习技术,减少模型在生成色情内容时的风险。相关研究不仅推动了文本生成模型在文学创作领域的应用,也为构建更为安全的AI模型提供了重要参考。
以上内容由遇见数据集搜集并总结生成


