GUIrilla-training-qwen
收藏Hugging Face2025-05-11 更新2025-05-12 收录
下载链接:
https://huggingface.co/datasets/macpaw-research/GUIrilla-training-qwen
下载链接
链接失效反馈官方服务:
资源简介:
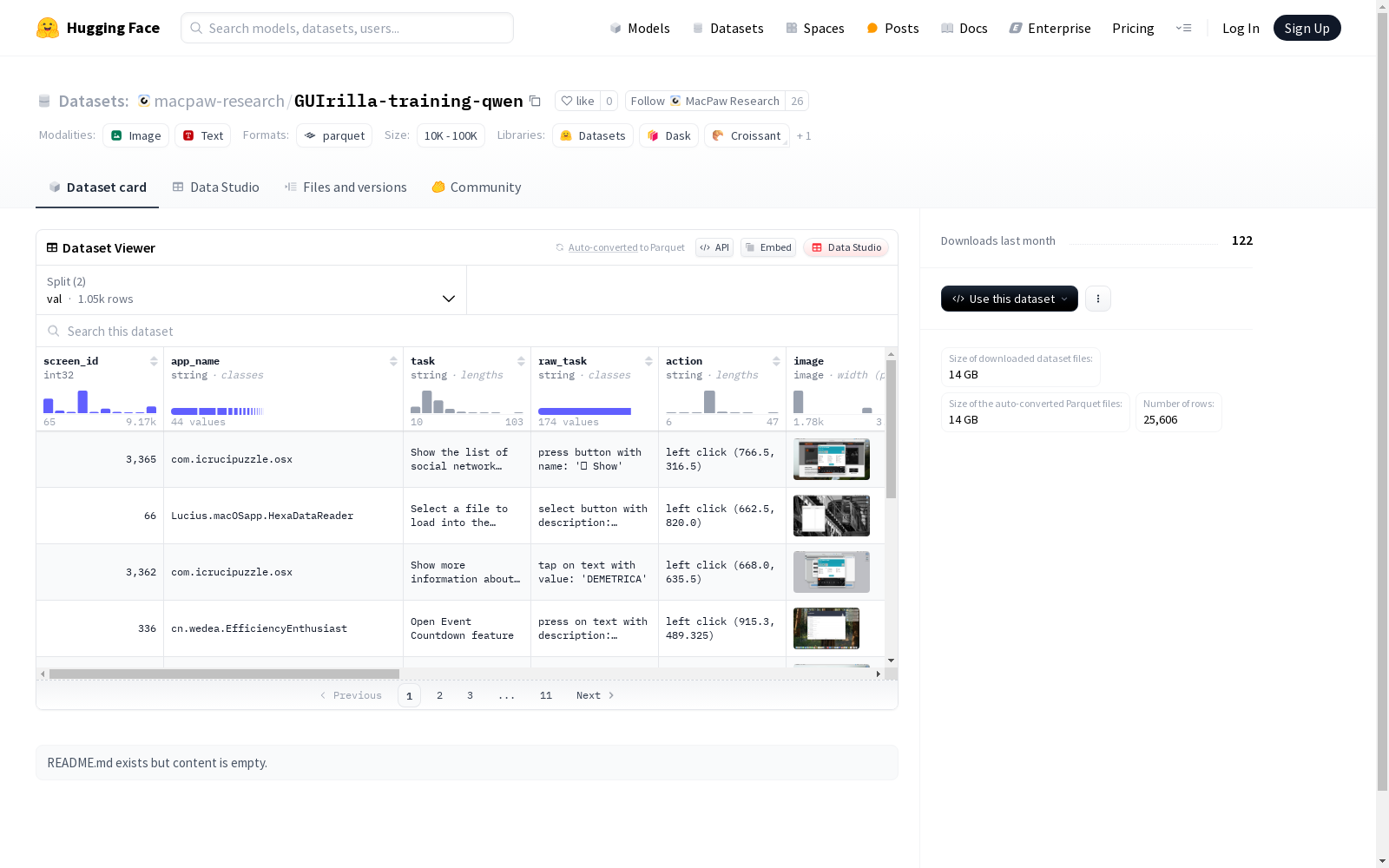
该数据集包含了屏幕ID、应用名称、任务、原始任务、任务类别、元素类别等字段,以及与图像相关的字段。数据集分为训练集和验证集,适用于机器学习模型的训练和验证。
创建时间:
2025-05-11
原始信息汇总
数据集概述
基本信息
- 数据集名称: GUIrilla-training-qwen
- 存储位置: https://huggingface.co/datasets/macpaw-research/GUIrilla-training-qwen
- 下载大小: 13,992,163,359 字节
- 数据集大小: 47,790,660,353 字节
数据集特征
- screen_id: int32类型,屏幕标识符
- app_name: string类型,应用程序名称
- task: string类型,任务描述
- raw_task: string类型,原始任务描述
- action: string类型,执行的操作
- image: image类型,屏幕图像
- image_cropped: image类型,裁剪后的屏幕图像
- accessibility: string类型,辅助功能信息
- scaling_factor: float32类型,缩放因子
- element_data: string类型,元素数据
- original_task: bool类型,是否为原始任务
- task_category: string类型,任务类别
- element_category: string类型,元素类别
数据划分
- 训练集 (train):
- 样本数量: 24,558
- 数据大小: 45,834,688,625.67265 字节
- 验证集 (val):
- 样本数量: 1,048
- 数据大小: 1,955,971,727.3273451 字节
配置文件
- 默认配置 (default):
- 训练集路径:
data/train-* - 验证集路径:
data/val-*
- 训练集路径:
搜集汇总
数据集介绍
构建方式
GUIrilla-training-qwen数据集通过系统化采集图形用户界面(GUI)交互数据构建而成,涵盖24,558组训练样本和1,048组验证样本。数据采集过程整合了屏幕标识符、应用名称、原始任务描述等元数据,并创新性地采用双图像存储模式,既保留完整界面截图又包含裁剪后的元素特写。每个交互动作均标注了可访问性参数、缩放比例及元素层级数据,辅以任务分类和元素分类的双重标注体系,形成多维度的GUI操作特征矩阵。
特点
该数据集最显著的特征在于其多模态数据结构,同步包含视觉信息(原始图像与裁剪图像)和结构化操作日志。任务描述字段采用原始文本和标准化文本的双重记录方式,配合元素级可访问性数据,为研究界面自动化提供了细粒度标注。数据规模达到47.7GB,覆盖多样化的应用场景,其中任务分类和元素分类标签体系为理解GUI操作语义建立了系统化框架,缩放因子等工程技术参数的保留则增强了数据的工程适用性。
使用方法
使用本数据集时,建议通过HuggingFace数据加载器按需读取训练集和验证集的分片文件。研究者可基于屏幕标识符实现跨模态数据关联,利用图像字段进行计算机视觉分析,结合动作序列研究操作模式识别。任务分类标签适用于有监督学习任务,元素数据JSON字符串可解析为结构化操作对象。验证集特别适合用于评估模型在未见应用场景中的泛化能力,而原始任务标记则为数据增强策略提供了筛选依据。
背景与挑战
背景概述
GUIrilla-training-qwen数据集是近年来人机交互与计算机视觉交叉领域的重要研究成果,由专业研究团队构建,旨在解决图形用户界面(GUI)自动化操作中的复杂任务理解与执行问题。该数据集通过整合多模态数据,包括屏幕截图、元素属性及操作指令,为智能代理在真实应用场景中的任务自动化提供了丰富的训练资源。其核心研究问题聚焦于如何使AI系统准确理解用户意图并生成相应的GUI操作序列,对推动人机交互智能化发展具有显著意义。
当前挑战
该数据集面临的挑战主要体现在两方面:领域问题层面,GUI操作的多样性和动态性导致任务理解的复杂性显著增加,要求模型具备跨应用泛化能力和细粒度视觉-语言对齐能力;构建过程层面,大规模高质量GUI数据的采集与标注需克服应用环境异构性、界面元素动态变化以及多任务语义一致性等难题,且需确保数据隐私与安全性。
常用场景
经典使用场景
在图形用户界面(GUI)自动化领域,GUIrilla-training-qwen数据集为研究人员提供了丰富的屏幕截图和交互动作数据,涵盖了多种应用程序和任务场景。该数据集最经典的使用场景是训练和评估基于视觉的GUI自动化模型,特别是那些需要理解屏幕元素和用户操作之间关系的任务。通过结合图像和结构化元数据,研究者能够开发出更精准的界面理解和操作预测算法。
实际应用
在实际应用中,GUIrilla-training-qwen数据集为开发智能助手和自动化测试工具提供了关键训练素材。基于该数据集训练的模型可以应用于软件测试自动化、残障人士辅助技术开发以及企业流程自动化等多个领域。特别是在移动应用和桌面软件的自动化测试场景中,该数据集帮助开发者构建了更鲁棒、更智能的测试解决方案。
衍生相关工作
围绕GUIrilla-training-qwen数据集,学术界已衍生出多项重要研究工作。其中包括基于深度学习的GUI元素检测算法、跨应用任务自动化框架以及结合自然语言处理的界面操作生成系统。这些工作不仅扩展了数据集的应用范围,也为后续的智能界面研究奠定了坚实基础,推动了整个GUI自动化领域的快速发展。
以上内容由遇见数据集搜集并总结生成


