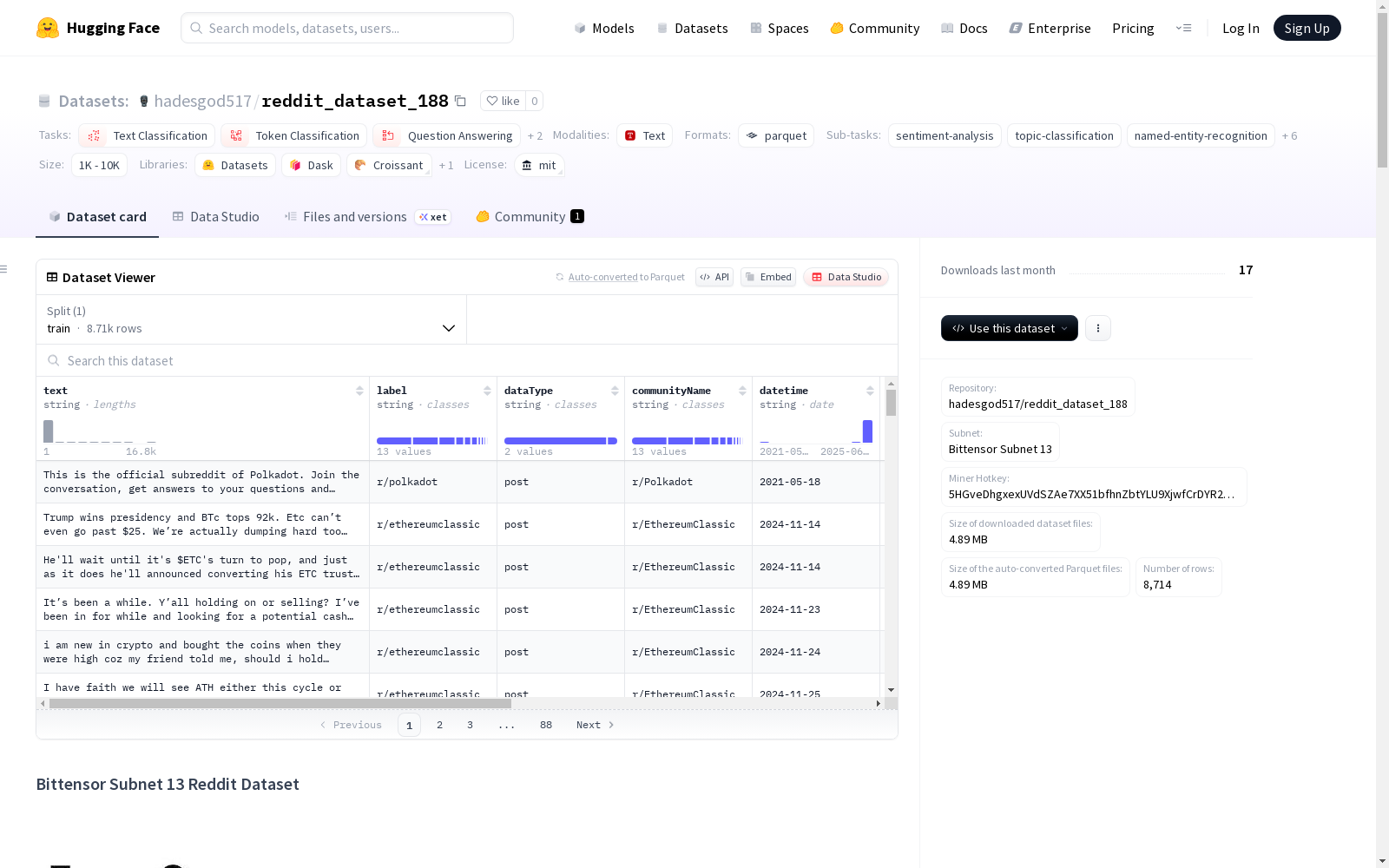
reddit_dataset_188
收藏Hugging Face2025-06-21 更新2025-06-22 收录
下载链接:
https://huggingface.co/datasets/hadesgod517/reddit_dataset_188
下载链接
链接失效反馈官方服务:
资源简介:
Bittensor Subnet 13 Reddit数据集是一个包含预处理后的Reddit帖子和评论的数据集,是Bittensor Subnet 13去中心化网络的一部分。数据集持续更新,提供实时流式的Reddit内容,适用于各种分析和机器学习任务。数据集主要是英文,但也可能是多语言的。每个数据实例包含帖子或评论的主要内容、标签、数据类型、社区名称、日期时间、编码后的用户名和URL。数据集没有固定的分割,用户应根据数据的时间戳创建自己的分割。数据来源于Reddit的公共帖子和评论,遵循平台的服务条款和API使用指南。所有用户名和URL都经过编码以保护用户隐私。数据集在MIT许可下发布,使用时需遵守Reddit的使用条款。
创建时间:
2025-06-21
原始信息汇总
数据集概述:Bittensor Subnet 13 Reddit Dataset
基本信息
- 仓库名称: hadesgod517/reddit_dataset_188
- 子网: Bittensor Subnet 13
- 矿工热键: 5HGveDhgxexUVdSZAe7XX51bfhnZbtYLU9XjwfCrDYR2dxzt
- 许可证: MIT
- 多语言支持: 多语言(主要为英语)
数据集描述
- 来源: 原始数据,采集自Reddit的公开帖子和评论
- 更新频率: 持续更新,实时流式数据
- 数据量: 20,828条实例
- 时间范围: 2021-05-18至2025-06-22
- 最后更新时间: 2025-06-22
数据结构
数据字段
text: 帖子或评论的主要内容label: 内容的情感或主题分类dataType: 条目类型(帖子或评论)communityName: 发布内容的子版块名称datetime: 发布时间username_encoded: 编码后的用户名(保护隐私)url_encoded: 编码后的URL(保护隐私)
数据分布
- 帖子: 4.53%
- 评论: 95.47%
支持的任务
- 文本分类
- 标记分类
- 问答系统
- 文本摘要
- 文本生成
- 情感分析
- 主题分类
- 命名实体识别
- 语言建模
- 文本评分
- 多类分类
- 多标签分类
- 抽取式问答
- 新闻文章摘要
数据集统计
实例总数
- 20,828条
热门子版块
| 排名 | 子版块 | 数量 | 占比 |
|---|---|---|---|
| 1 | r/news | 5,304 | 25.47% |
| 2 | r/wallstreetbets | 4,716 | 22.64% |
| 3 | r/Bitcoin | 3,242 | 15.57% |
| 4 | r/CryptoCurrency | 2,402 | 11.53% |
| 5 | r/investing | 1,419 | 6.81% |
| 6 | r/solana | 1,012 | 4.86% |
| 7 | r/CryptoMarkets | 838 | 4.02% |
| 8 | r/ethtrader | 808 | 3.88% |
| 9 | r/btc | 330 | 1.58% |
| 10 | r/Monero | 242 | 1.16% |
使用注意事项
- 隐私保护: 用户名和URL已编码处理
- 社会影响: 可能存在Reddit数据固有的偏见
- 局限性: 数据质量可能参差不齐,可能存在噪声和垃圾内容
- 时间偏差: 实时收集方法可能导致时间偏差
引用信息
bibtex @misc{hadesgod5172025datauniversereddit_dataset_188, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={hadesgod517}, year={2025}, url={https://huggingface.co/datasets/hadesgod517/reddit_dataset_188}, }
更新历史
| 日期 | 新增实例 | 总实例数 |
|---|---|---|
| 2025-06-20 | 2,333 | 2,333 |
| 2025-06-21 | 6,381 | 8,714 |
| 2025-06-22 | 12,114 | 20,828 |
搜集汇总
数据集介绍
构建方式
该数据集依托Bittensor Subnet 13去中心化网络构建,通过分布式矿工实时采集Reddit公开帖文与评论数据,严格遵循平台服务条款及API使用规范。数据采集过程中采用用户名与URL编码技术处理隐私信息,确保符合《Macrocosmos矿工数据合规政策》要求。动态更新机制使数据集保持时效性,最新统计显示已涵盖2021至2025年间8714条数据实例,其中评论占比达90.37%。
使用方法
研究者可通过HuggingFace平台直接加载数据集,建议按时间戳自定义数据划分以适应不同任务需求。该数据集支持情感分析、主题建模等典型NLP任务,尤其适合加密货币社区行为研究。使用时应结合stats.json文件分析数据分布特征,注意遵循MIT许可及Reddit使用条款。对于时序分析任务,可利用datetime字段构建纵向研究框架,而username_encoded字段则为用户行为追踪提供了去标识化解决方案。
背景与挑战
背景概述
reddit_dataset_188数据集作为Bittensor Subnet 13去中心化网络的重要组成部分,由hadesgod517等研究人员于2025年构建并持续更新。该数据集专注于收集和预处理Reddit平台的公开帖文与评论,旨在为社交媒体的多维度分析提供实时数据支持。其核心研究问题聚焦于社交媒体动态的量化表征,涵盖情感分析、主题建模、社区分析等多元任务,为自然语言处理领域提供了丰富的非结构化文本资源。数据集采用去中心化方式维护,通过分布式矿工节点实现数据的动态更新,体现了Web3.0时代数据治理的创新范式。
当前挑战
该数据集面临的主要挑战体现在两个维度:在领域问题层面,社交媒体文本固有的噪声、语义模糊性及话题漂移现象,对情感分类和主题建模的准确性构成显著挑战;用户生成内容中潜藏的认知偏差和群体极化倾向,可能影响下游任务的泛化能力。在构建技术层面,去中心化采集机制导致数据质量存在异质性,需设计鲁棒的清洗流程;实时更新特性引入时序分布偏移问题,要求动态建模方法;隐私保护需求与数据实用性的平衡,以及多语言混排现象的处理,均为数据集构建的关键技术难点。
常用场景
经典使用场景
在社交媒体的文本挖掘领域,reddit_dataset_188数据集凭借其丰富的Reddit平台内容,成为研究社区动态和用户行为的理想选择。该数据集广泛应用于情感分析任务,通过分析用户评论和帖子的情感倾向,揭示特定话题下的公众情绪波动。同时,其多标签分类功能支持对复杂主题的细粒度划分,为理解网络社区的知识结构提供了数据基础。
解决学术问题
该数据集有效解决了社交媒体分析中的关键学术挑战。通过提供带有时间戳的完整交互记录,研究人员能够追踪舆论演变的时序特征,弥补了传统横截面数据的局限性。在自然语言处理领域,其标注的文本数据缓解了小样本场景下的模型训练难题,特别是为低资源语言任务提供了宝贵的迁移学习素材。
实际应用
实际应用中,该数据集支撑了金融科技领域的前沿探索。华尔街赌局等投资社区的数据,使算法能够捕捉散户投资者的情绪指标,为量化交易策略提供另类数据参考。在加密货币市场监测方面,通过实时分析相关讨论热度,建立了市场波动与社区活跃度的关联模型。
数据集最近研究
最新研究方向
在社交媒体的快速发展背景下,reddit_dataset_188数据集因其去中心化采集和实时更新的特性,成为研究社交网络动态的重要资源。该数据集在情感分析和话题建模方面展现出显著潜力,尤其在加密货币和金融社区(如r/wallstreetbets和r/Bitcoin)的内容分析中,为市场情绪预测和社区行为研究提供了丰富素材。此外,数据集的多语言支持拓展了跨文化社交行为研究的可能性,而用户隐私保护机制则确保了研究的合规性。随着大语言模型在文本生成和摘要任务中的广泛应用,该数据集的高质量标注和多样化任务支持,使其成为训练和评估模型性能的理想选择。
以上内容由遇见数据集搜集并总结生成


