news_articles_2025_elections_germany
收藏Hugging Face2025-09-15 更新2025-09-16 收录
下载链接:
https://huggingface.co/datasets/Zorryy/news_articles_2025_elections_germany
下载链接
链接失效反馈官方服务:
资源简介:
德国新闻文章数据集 - 2025年联邦选举,包含294,154篇德语新闻文章,涵盖了2025年1月1日至2月23日这一关键的前八周时期,文章来自44个不同的德国新闻领域。数据集未经过话题或格式筛选,旨在准确反映指定时间段内这些领域的新闻输出。数据集未标注,但包含了文章的完整文本。
创建时间:
2025-09-07
原始信息汇总
German News Articles: Federal Elections 2025 数据集概述
数据集基本信息
- 数据集名称:German News Articles: Federal Elections 2025
- 许可证:Creative Commons Attribution-NonCommercial 2.0 Generic License (CC BY-NC 2.0)
- 语言:德语(monolingual)
- 数据规模:100K<n<1M(共294,154篇文章)
- 发布时间范围:2025年1月1日至2025年2月23日
- 数据来源:44个德国新闻域名
任务类别
- 文本分类
- 零样本分类
- 填充掩码
- 文本生成
标签
- 新闻
- 政治
- 德国新闻业
- 德国选举
- 2025选举
- 大语言模型
- 表格
- 文本
数据集内容
- 数据内容:包含294,154篇德语新闻全文,覆盖2025年德国联邦选举前关键八周 period
- 数据特征:未经过主题或格式过滤,真实反映指定时间段内新闻域的输出
- 标注情况:无标注数据
数据收集与创建
- 收集方法:通过R语言进行大规模网络爬取,利用目标域名的静态XML网站地图识别和收集文章链接
- 覆盖率:大多数域名覆盖率达到98-100%,部分域名因技术限制覆盖率较低
- HTML解析:基于paperboy R包的解析逻辑
- 链接收集时间:2025年6月1日
- 全文爬取时间:2025年6月29日至2025年8月31日
数据集结构
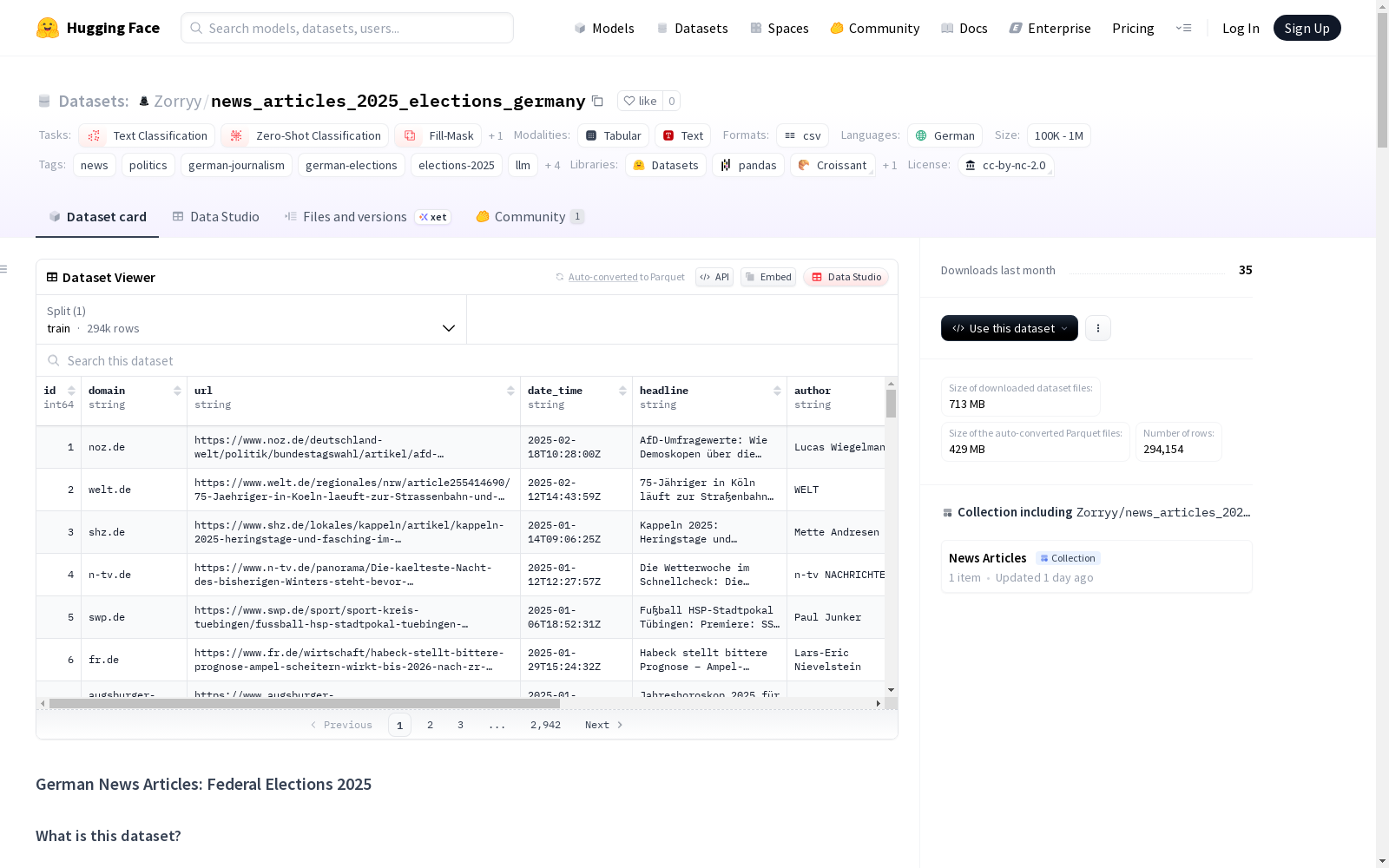
数据列描述
id:连续整数计数器,唯一行标识符domain:文章发布域名url:原始文章直接URLdate_time:发布时间戳(UTC时区,格式:YYYY-MM-DD HH:MM:SS)headline:文章标题(可选,可能为NA)author:文章作者(可选,可能为NA)text:文章全文paywall:付费墙标志(0:无付费墙;1:有付费墙)text_length:文本字数(按空格分隔符计算)
数据分割
- 数据集以单个文件形式提供,无预定义分割
- 建议用户基于domain列进行分层分割
已知限制与偏差
- 付费墙内容:44个域名中有20个存在付费墙内容
- 付费墙比例:约14%的文章存在付费墙限制
- 付费墙内容特征:付费墙文章可能只包含介绍性段落,文本长度因域名而异
创建目的
- 作为学士论文的一部分创建
- 用于分析选举相关主题的公共话语
- 支持分类任务和研究分析
伦理考虑
- 遵循道德爬取指南,未对服务器造成压力
- 未破解或绕过任何付费墙
- 所有数据点均按在线可见形式呈现
引用信息
other @misc{oezcan2025news, title={German News Articles: Federal Elections 2025}, author={Zorbey Oezcan}, year={2025}, publisher={Hugging Face}, journal={Hugging Face repository}, howpublished={url{https://huggingface.co/datasets/Zorryy/news_articles_2025_elections_germany}} }
搜集汇总
数据集介绍
构建方式
在政治传播学领域,大规模文本语料的构建对研究公共话语具有关键价值。本数据集通过R语言驱动的网络爬虫系统,基于44家德国新闻媒体的XML站点地图进行系统性采集,覆盖2025年1月至2月选举关键期的294,154篇德文新闻。采用paperboy解析框架提取全文内容,通过UTC时间戳标准化和付费墙标记机制,确保数据采集过程兼顾完整性与伦理合规性。
特点
该数据集呈现德国多元媒体生态的横截面,涵盖从全国性媒体到地方报刊的文本光谱。其核心特征体现在未经过滤的原始新闻文本、精确到秒的发布时间元数据,以及14%付费墙内容的透明标注。每个条目均包含域名来源、作者信息及文本长度统计,为比较媒体偏见、话题演化及语言风格研究提供多维分析基础。
使用方法
研究者可借助pandas或datasets库加载该数据集,通过域名分层抽样构建训练验证集以确保媒体代表性。适用于文本分类、零样本学习及生成任务,特别适合选举议题挖掘和媒体偏见分析。使用时应遵循CC-BY-NC 2.0许可协议,注意付费墙内容可能存在的文本完整性限制,建议结合自然语言处理技术进行话题建模和语义分析。
背景与挑战
背景概述
德国2025联邦选举新闻数据集由社会学专业学生Zorbey Oezcan于2025年创建,旨在捕捉选举前关键八周内德语媒体的完整叙事图谱。该数据集涵盖44个新闻平台的29万余篇文章,采用基于XML站点地图的爬取技术实现对98%以上内容的覆盖,为政治传播学与计算社会科学领域提供了前所未有的时序媒体档案。其核心价值在于通过未经过滤的原始文本,支持选举议题分析、媒体偏见研究和多任务NLP模型开发,显著推进了德语政治文本挖掘的研究进程。
当前挑战
本数据集面临双重挑战:在领域问题层面需解决政治文本多维度分类的复杂性,包括选举议题提取、媒体立场检测和叙事框架分析,同时需应对德语复合词处理与政治术语动态演变的语言特性;在构建过程中遭遇技术性障碍,部分新闻站点因非标准化站点地图导致覆盖不全,且约14%的付费墙内容造成文本完整性缺失,需通过元数据标注策略维持语料库的透明度与可用性。
常用场景
经典使用场景
在政治传播学研究中,该数据集为分析德国联邦选举前的媒体议程设置提供了重要素材。研究者通过文本挖掘技术追踪各媒体对移民政策、经济议题和地缘冲突等选举核心话题的报道倾向,揭示媒体如何塑造公众政治认知。大规模德语新闻语料使得跨媒体比较研究成为可能,特别是对44家不同立场媒体的报道框架进行对比分析。
解决学术问题
该数据集有效解决了政治传播领域对实时选举报道缺乏系统化语料库的学术需求。研究者可据此分析媒体偏见形成机制、政党形象构建策略以及公共议题演化轨迹。其时间序列特性支持对选举周期内舆论动态的纵向研究,而无标注特性为无监督学习提供了理想实验环境,推动了选举预测模型和媒体影响力评估方法的发展。
衍生相关工作
基于该数据集衍生的经典工作包括跨媒体偏见检测算法开发,其中结合BERT架构的领域自适应方法显著提升了政治立场分类精度。另有研究利用时序建模追踪议题关注度演变,构建了选举预测指数。部分工作专注于多模态扩展,将文本分析与社交媒体数据进行融合,形成了更全面的德国选举舆论图谱。
以上内容由遇见数据集搜集并总结生成


