zenml/llmops-database
收藏Hugging Face2026-05-01 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/zenml/llmops-database
下载链接
链接失效反馈官方服务:
资源简介:
LLMOps数据库是一个包含325个真实世界生成式AI实现的全面集合,展示了组织如何成功地将大型语言模型(LLMs)部署到生产环境中。这些案例研究经过精心策划,侧重于技术深度和实际问题的解决,强调实现细节而非营销内容。数据库旨在弥合理论讨论与实际部署之间的差距,为技术团队提供有价值的见解,帮助他们在生产环境中实施LLMs。LLMOps数据库由ZenML团队维护,并在Hugging Face上提供离线访问和程序化浏览。
The LLMOps Database is a comprehensive collection of over 325 real-world generative AI implementations that showcases how organizations are successfully deploying Large Language Models (LLMs) in production. The case studies have been carefully curated to focus on technical depth and practical problem-solving, with an emphasis on implementation details rather than marketing content. The database aims to bridge the gap between theoretical discussions and practical deployments, providing valuable insights for technical teams looking to implement LLMs in production.
提供机构:
zenml
搜集汇总
数据集介绍
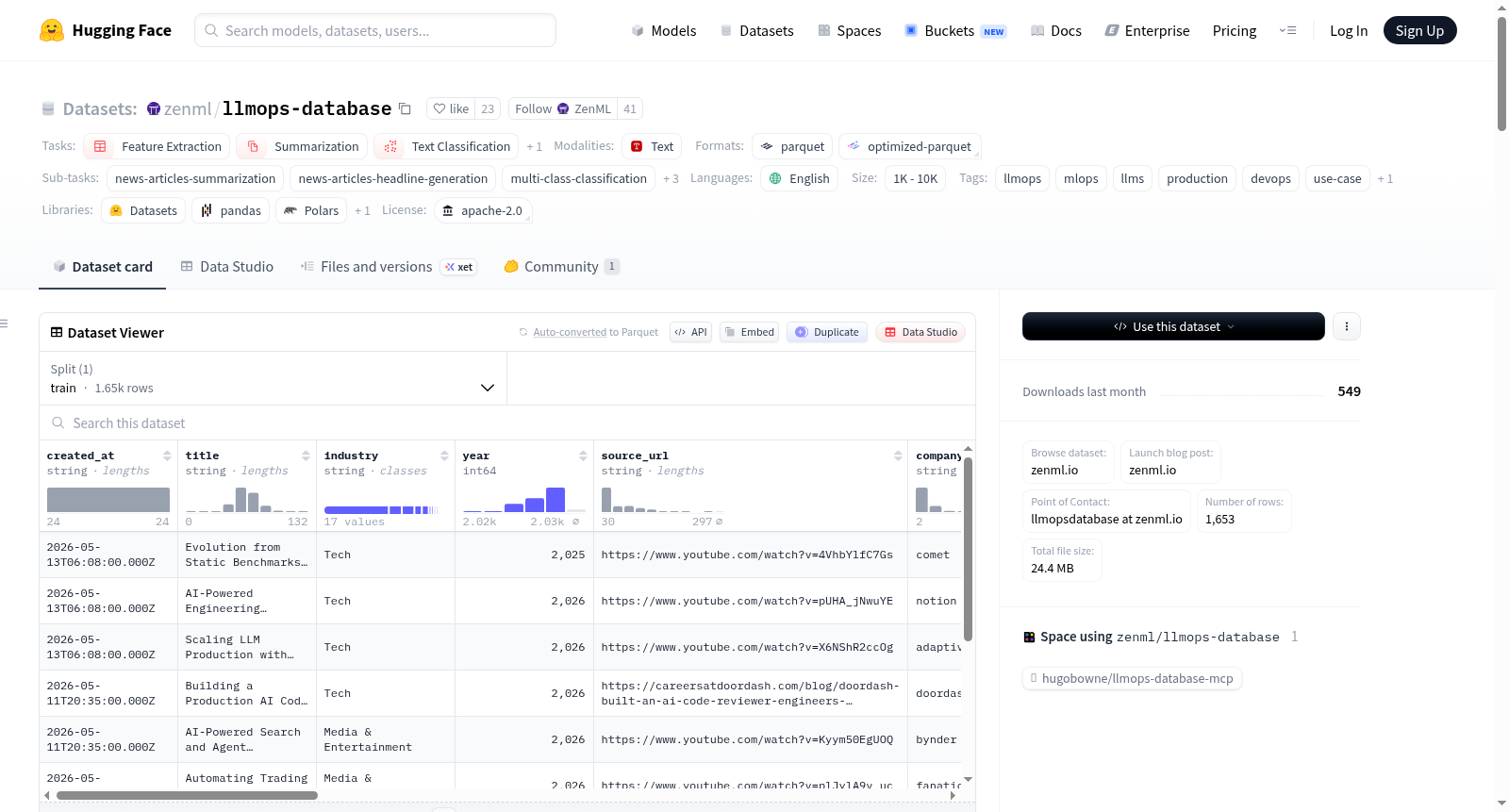
构建方式
LLMOps Database数据集由ZenML团队精心构建,旨在汇聚真实世界中大语言模型(LLM)在生产环境中的部署案例。数据来源涵盖Twitter与Discord上的技术讨论,并借助Exa.ai进行基于嵌入的相似性搜索以扩充相关资源。案例选取聚焦于技术深度与实用性,强调实现细节与架构决策。原始内容为完整博客文章或YouTube视频文字稿,随后采用Anthropic的Claude Sonnet 3.5模型进行摘要提炼,并通过instructor库提取结构化元数据。最终形成包含超过500个条目的单一分片数据集。
特点
该数据集以其实践导向与结构化元数据而独具特色。每条记录包含标题、行业、公司、来源链接、应用标签、工具标签、技术标签及长短摘要等丰富字段,既提供精炼概述,也保留详尽的技术剖析。案例覆盖科技、金融、医疗等多行业,标签体系完整,便于按应用场景、技术栈或部署策略进行精细化筛选。数据集无预定义训练/验证/测试划分,适用于探索性分析与知识检索,是连接LLM理论探讨与生产实践的重要桥梁。
使用方法
用户可通过Hugging Face Datasets库直接加载数据,利用其标准API进行程序化访问与交互式探索。数据集仅包含训练分片,内嵌的`short_summary`与`full_summary`字段为摘要生成、分类或信息检索等任务提供天然素材。此外,仓库内另附独立的Markdown文件与拼接后的单一文本文件(`all_data_single_file.txt`),后者可便捷上传至NotebookLM或支持超长上下文的模型(如Gemini Pro)进行对话式分析。多种访问形式兼顾了离线浏览与编程处理的灵活性。
背景与挑战
背景概述
在大规模语言模型(LLM)蓬勃发展的时代,尽管学术界与工业界涌现出大量理论性探讨,但关于如何将LLM高效、可靠地部署至生产环境的实践案例却相对匮乏。ZenML团队于2024年创建了LLMOps数据库,旨在填补这一理论与实践之间的鸿沟。该数据库由ZenML团队精心策划,收录了超过500个来自Meta等全球领先企业的真实生成式AI实现案例,聚焦于技术实施细节与架构决策,而非营销内容。作为首个系统化整合LLMOps部署经验的开源资源,该数据库为技术团队提供了弥足珍贵的参考,推动了生产级LLM解决方案的标准化与共享理解。
当前挑战
LLMOps数据库主要服务于两个层面的挑战。领域层面,它直面LLM在生产部署中面临的通用难题,包括延迟优化、成本控制、模型蒸馏、流量管理与错误处理等,为工程团队提供可复用的解决方案。构建层面,其创建过程面临双重挑战:一是信息源的多样性与深度,团队需从Twitter、Discord及Exa.ai等渠道手工筛选技术细节丰富的原始内容,确保案例的实践相关性;二是元数据的规范提取,借助Claude Sonnet 3.5模型与instructor库对博客全文或视频转录进行总结与结构化标注,在避免版权问题的前提下,平衡了信息完整性与可用性。
常用场景
经典使用场景
LLMOps Database作为一座连接理论与实践的桥梁,为大语言模型在生产环境中的部署提供了宝贵的实证资源。其最经典的使用场景在于,研究者和工程师可以通过该数据集系统性地探索不同行业、不同规模的组织如何将LLM从原型阶段推向生产级应用。数据集收录了超过500个经过精心筛选的真实案例,每个案例都包含了详细的实现细节、技术选型、架构决策以及所面临的挑战与解决方案。这种结构化的知识库使得用户能够进行横向比较分析,例如对比金融、医疗、科技等不同领域中LLM落地策略的异同,或是探究模型优化、延迟控制、成本管理等关键技术维度的最佳实践。
实际应用
在实际应用中,LLMOps Database为技术团队在规划与实施LLM部署时提供了关键的决策支持。当团队面临技术选型困境时,例如在评估不同推理框架、监控工具或负载均衡策略时,可以通过检索数据库中相似场景的案例来获得参考。数据集特别标注了案例所用的工具栈、技术标签和行业归属,这使工程师能够快速定位到与自身业务场景高度匹配的实施方案。此外,该数据集还广泛应用于内部培训和技术分享,作为学习型组织的知识沉淀,帮助团队快速建立起对LLM生产级运维的整体认知,从而降低试错成本,加速产品迭代周期。
衍生相关工作
基于LLMOps Database这一宝贵资源,学术界和工业界衍生出了一系列富有洞见的后续工作。研究人员利用数据集中的元数据,如技术标签和行业分类,开展了LLM部署模式的聚类分析与趋势预测,揭示了不同技术范式的演进路径。更具体地,有工作聚焦于从案例中提取通用性设计模式,构建了LLM运维的参考架构模板。此外,该数据库也催生了基于检索增强生成(RAG)的智能问答系统的开发,这些系统能够根据用户提出的具体部署问题,从数据库中检索最相关的案例并生成定制化的建议,从而将静态的数据资源转化为动态的知识服务系统,进一步拓展了其应用边界。
以上内容由遇见数据集搜集并总结生成


