jedisct1/agent-traces-swival
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/jedisct1/agent-traces-swival
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: coding agent traces
task_categories:
- text-generation
tags:
- agent-traces
- coding-agent
- swival
language:
- en
- code
license: mit
---
A collection of agent traces generated with [Swival](https://swival.dev) (**not** Claude Code, despite what the HF interface currently shows), an agent designed for open-source models.
These traces focus on planning and security audits.
## Sharing traces with Swival
Swival can export full conversation traces with `--trace-dir`, which writes one `<session_id>.jsonl` file per session:
```bash
swival "Fix the login bug" --trace-dir traces/
```
Those JSONL files use Swival's Claude Code compatible trace export, and HuggingFace auto-detects them as `format:agent-traces`, so they can be uploaded and shared directly on HuggingFace. You can use `--trace-dir` on its own or alongside `--report` if you also want structured run metadata.
If you want tracing enabled by default, set `trace_dir` in `swival.toml` or `~/.config/swival/config.toml`. For more information, see the [Swival trace export docs](https://swival.dev/pages/reports.html).
提供机构:
jedisct1
搜集汇总
数据集介绍
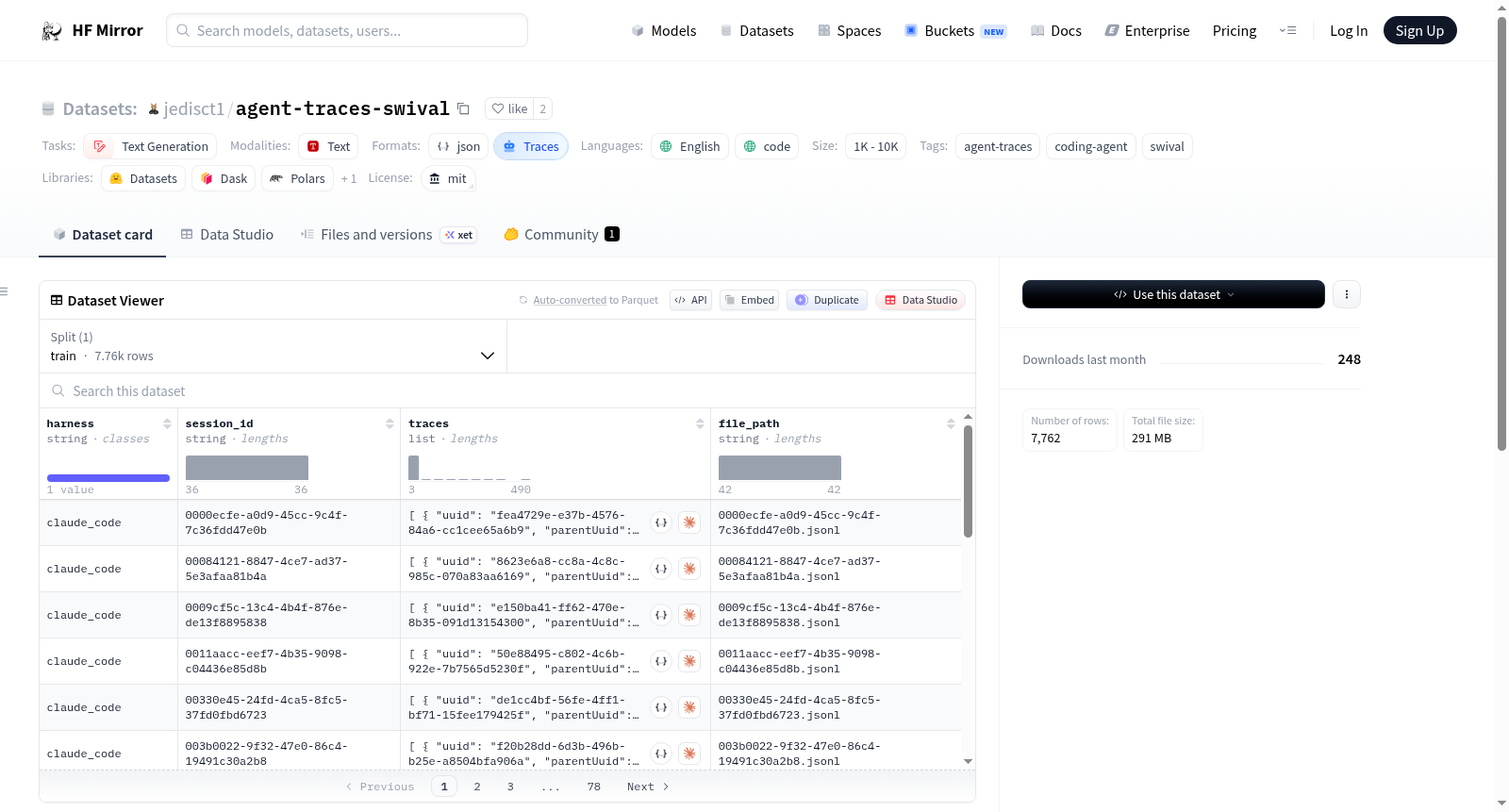
构建方式
在软件安全审计领域,agent-traces-swival数据集通过Swival代理工具系统性地生成。该工具专为开源模型设计,能够执行安全审计任务并自动记录完整的对话轨迹。用户只需在命令行中指定`--trace-dir`参数,Swival便会将每次会话以JSONL格式文件保存,每个文件对应一个独立的审计会话。这种构建方式确保了数据记录的连贯性与结构化,为后续分析提供了可追溯的原始交互数据。
特点
该数据集聚焦于开源软件的安全审计场景,涵盖了代理与模型在代码审查、漏洞识别等任务中的详细交互轨迹。其核心特点在于采用与Claude Code兼容的导出格式,使得HuggingFace平台能够自动识别为`agent-traces`类型,便于直接上传与共享。数据以纯文本和代码混合语言呈现,不仅记录了自然语言指令,还包含具体的代码段与审计反馈,为研究智能代理在安全领域的决策过程提供了多维度视角。
使用方法
使用本数据集时,研究者可通过HuggingFace平台直接访问已上传的JSONL格式轨迹文件。这些文件完整保留了代理与模型之间的对话序列,包括用户查询、代理响应及中间推理步骤。用户可基于此分析代理在安全审计任务中的行为模式、错误类型或效率表现。此外,通过配置Swival工具的`trace_dir`设置,可启用默认跟踪功能,持续收集并扩展数据集,以支持更广泛的实证研究或模型训练。
背景与挑战
背景概述
在人工智能与软件工程交叉领域,自动化代码审计已成为提升开源软件安全性的关键研究方向。agent-traces-swival数据集应运而生,由Swival开发团队创建,旨在收集基于开源模型的智能体在安全审计任务中产生的交互轨迹。该数据集聚焦于对开源软件进行安全漏洞检测与修复,核心研究问题在于探索智能体如何理解复杂代码逻辑、识别潜在安全风险并生成有效解决方案。通过提供结构化的对话记录,它为研究代码生成智能体的决策过程、错误模式及安全推理能力提供了宝贵资源,对推动自动化安全工具与可解释AI的发展具有显著影响力。
当前挑战
该数据集致力于应对自动化代码安全审计的挑战,即如何使智能体在无需人类干预的情况下,准确识别多样化的软件漏洞(如登录逻辑缺陷、注入攻击风险等),并生成可靠修复方案。构建过程中的主要困难包括:确保轨迹数据的多样性与代表性,涵盖不同编程语言、漏洞类型及审计场景;维护数据格式的一致性,以兼容Claude Code的导出规范;以及平衡开源模型能力限制与复杂安全任务需求之间的差距,从而保证轨迹质量足以支持严谨的学术分析与模型训练。
常用场景
经典使用场景
在软件安全领域,agent-traces-swival数据集为研究自动化代码审计提供了关键资源。该数据集通过Swival代理生成,专注于开源软件的安全漏洞检测,其经典使用场景包括训练和评估基于大型语言模型的代码分析系统。研究人员利用这些轨迹数据模拟真实世界的安全审计过程,从而优化代理在代码审查、漏洞识别和修复建议生成方面的性能,推动智能代码助手在安全关键任务中的可靠应用。
解决学术问题
该数据集有效解决了自动化安全审计中缺乏高质量、结构化轨迹数据的学术挑战。它为研究代码生成代理的行为模式、错误分析和决策逻辑提供了实证基础,有助于探索如何提升代理在复杂代码语境下的理解与推理能力。通过提供可复现的审计轨迹,数据集促进了智能代理透明度、可解释性及鲁棒性的研究,对推动软件工程与人工智能交叉领域的理论进展具有显著意义。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在智能代理的轨迹分析与优化领域。例如,研究利用这些轨迹训练专用模型以增强代码漏洞检测的精确度,或开发新型评估框架来衡量代理在安全任务中的有效性。此外,轨迹数据被用于构建基准测试集,如SWIVAL-Bench,以系统比较不同代码代理在安全审计场景下的性能,这些工作共同推动了自动化软件安全工具的迭代与标准化进程。
以上内容由遇见数据集搜集并总结生成


