oliverkinch/dynaword-bt
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/oliverkinch/dynaword-bt
下载链接
链接失效反馈官方服务:
资源简介:
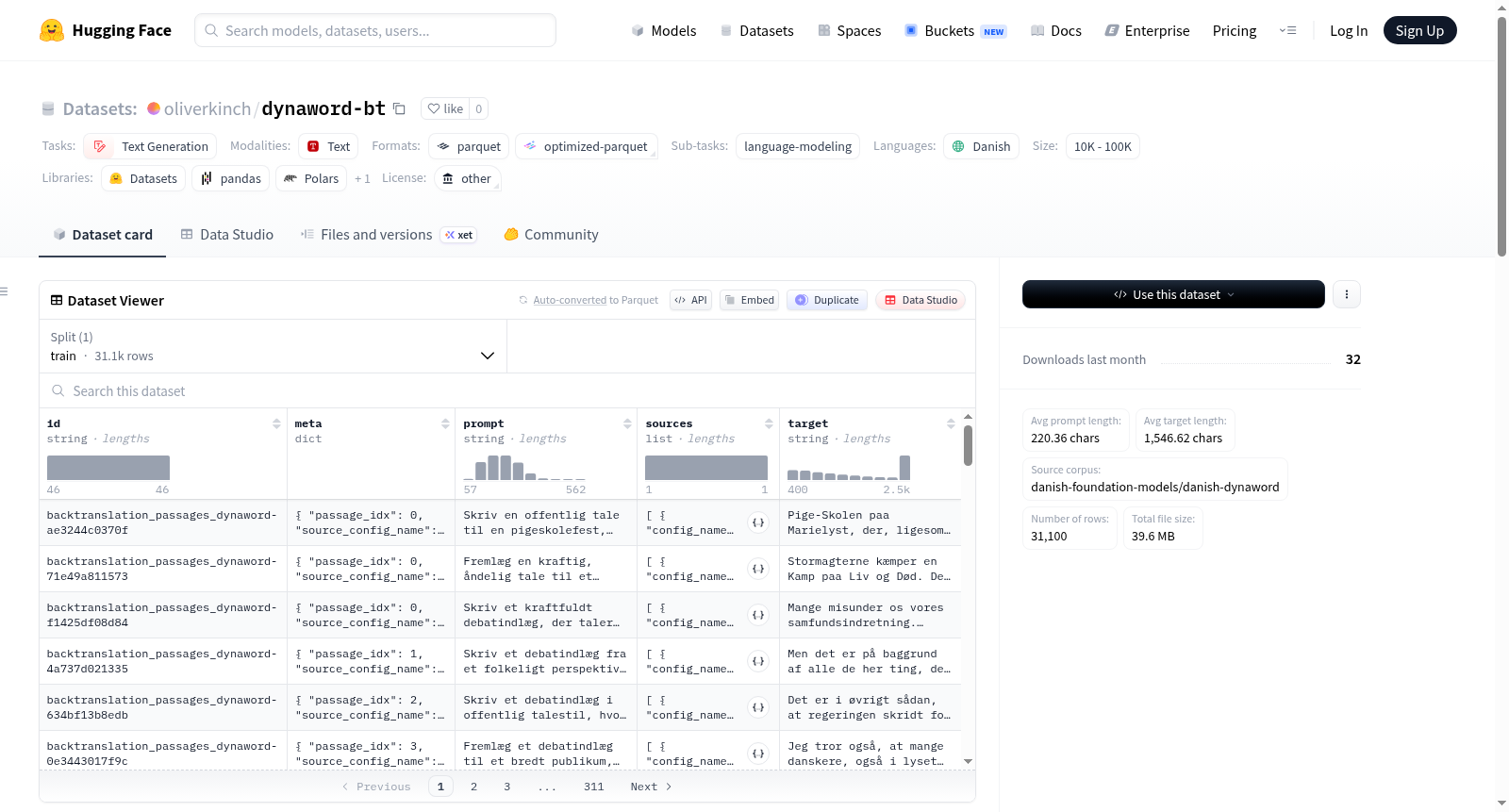
`dynaword-bt`是一个丹麦语指令调优数据集,通过从`danish-foundation-models/danish-dynaword`中选择的子集进行回译生成。每一行包含:`prompt`(合成的丹麦用户请求,适合指令微调)、`target`(源文本段落,提示旨在引出)以及`meta`和`sources`(来源元数据,包括源子集、源行ID、分割和源类型)。数据集使用`dfm-sdg`中的`backtranslation_passages_dynaword`管道构建,包括源感知提示和段落级过滤。数据集包含31,100行(`train`),平均提示长度为220.36字符,平均目标长度为1,546.62字符。来源分布包括`danske-taler`、`ft`、`nordjyllandnews`、`tv2r`、`skat`、`miljoeportalen`和`ai-aktindsigt`。数据字段包括`id`、`prompt`、`target`、`meta`和`sources`。创建过程涉及源特定提示样式、混合/完整/段落分块、OCR噪声和重复段落的过滤、敏感或不合适段落的过滤以及提示后处理和验证。
`dynaword-bt` is a Danish instruction-tuning dataset generated with backtranslation from selected subsets of `danish-foundation-models/danish-dynaword`. Each row contains: `prompt` (a synthetic Danish user request suitable for instruction fine-tuning), `target` (the source text passage that the prompt is intended to elicit), and `meta` and `sources` (provenance metadata including source subset, source row id, split, and source type). The dataset was built with the `backtranslation_passages_dynaword` pipeline in `dfm-sdg` and includes source-aware prompting plus passage-level filtering. The dataset contains 31,100 rows (`train`), with an average prompt length of 220.36 chars and an average target length of 1,546.62 chars. The source distribution includes `danske-taler`, `ft`, `nordjyllandnews`, `tv2r`, `skat`, `miljoeportalen`, and `ai-aktindsigt`. Data fields include `id`, `prompt`, `target`, `meta`, and `sources`. The creation process involves source-specific prompting styles, hybrid/full/passage chunking, filtering for OCR noise and repetitive segments, filtering for sensitive or unsuitable passages, and prompt post-processing and validation.
提供机构:
oliverkinch
搜集汇总
数据集介绍
构建方式
该数据集基于丹麦语基础模型精选子集,采用回译技术构建而成。具体而言,研究者利用`danish-foundation-models/danish-dynaword`语料中的文本段,通过`dfm-sdg`项目中的`backtranslation_passages_dynaword`流水线,生成了适配指令微调的高质量丹麦语用户请求。在构建过程中,根据不同的源文本类型(如演讲、新闻、税务指南、政府文件)设计了对应的提示风格,并实施了混合/全文/段落分块策略。同时,对生成结果进行了严格的OCR噪声过滤、重复片段剔除、敏感内容审查以及丹麦语语言质量校验,以确保数据的可靠性和有效性。
使用方法
该数据集可直接用于丹麦语大语言模型的指令微调与文本生成任务。使用时,用户可通过HuggingFace数据集加载接口读取Parquet格式的训练数据,每个样本由`prompt`字段提供用户指令,`target`字段提供期望回复。研究者在微调过程中可借助`meta`和`sources`字段追踪每一条数据的来源子集、原始标识符及分块信息,便于进行可控的数据筛选或领域分析。鉴于数据集中提示均基于丹麦语生成,建议用于提升模型在丹麦语语境下的指令遵循能力与对话生成质量。
背景与挑战
背景概述
Dynaword-bt数据集由丹麦基础模型团队于近期构建,旨在提升丹麦语指令微调数据的质量与规模。该研究聚焦于低资源语言中合成数据生成的核心问题,即如何通过回译策略从非对话语料中创建高质量的指令-响应对。数据集选取了丹麦语Dynaword语料库中的精选子集,涵盖议会演讲、新闻、税务指南和政府文件等多领域内容,通过源感知提示设计和段落级过滤流水线,生成了包含3.1万个训练样本的合成指令数据集。该工作为丹麦语自然语言处理提供了重要的基准资源,推动了低资源语言中监督式微调方法的进展,尤其对北欧语言模型的发展具有示范意义。
当前挑战
所解决的领域问题在于丹麦语等低资源语言的指令微调数据极度匮乏,而传统的人工标注成本高昂且难以规模化。Dynaword-bt通过回译技术将普通文本转化为指令形式,克服了多领域语义一致性保持的难题,例如在税务指导、政府文件和新闻等不同文体中设计差异化的提示风格。构建过程中的核心挑战包括:处理源自OCR的噪声文本和重复段落,实施敏感内容过滤以避免有害输出,以及通过丹麦语验证和泄漏控制确保生成指令的语言合规性与数据纯净。这些过滤与验证机制有效提升了数据集的可用性与安全性,为后续模型微调奠定了坚实基础。
常用场景
经典使用场景
Dynaword-BT数据集专为丹麦语指令微调而设计,其核心应用场景在于构建能够理解并生成丹麦语自然语言指令的对话系统。通过反向翻译技术,该数据集将来自多个领域(如新闻、演讲、税务指南和政府文件)的原始文本转化为用户请求形式的指令对,从而为大语言模型提供丰富的丹麦语监督信号。研究者常利用此数据集对预训练模型进行指令微调,使其掌握丹麦语语境下的任务理解与生成能力,尤其适用于资源匮乏的低资源语言场景。
解决学术问题
该数据集有效缓解了丹麦语在指令微调领域数据稀缺的困境。传统上,丹麦语等低资源语言缺乏高质量、大规模的指令标注数据,导致模型在这些语言上的表现远逊于英语。Dynaword-BT通过反向翻译技术,从现有语料库中自动生成指令对,解决了从零构建人工标注数据的成本与时间问题。其意义在于为低资源语言的自然语言处理提供可复现的通用方法论,推动了多语言大模型在非英语地区的公平性与可用性研究。
实际应用
在实际应用中,Dynaword-BT可用于开发丹麦语的智能助手、客服系统和内容生成工具。例如,政府机构可借助基于此数据集微调的模型,自动解答公民关于税务或环境法条的咨询;新闻媒体能利用模型生成符合丹麦语表达规范的摘要或问答系统。此外,该数据集支持对模型进行领域适配,使其在演讲、新闻报道等特定场景下输出更贴切、流畅的回应,从而提升丹麦语用户的人机交互体验。
数据集最近研究
最新研究方向
在低资源语言与指令微调的交汇处,Dynaword-BT数据集通过回译技术从丹麦语多元语料库中合成高质量指令-响应对,为丹麦语大语言模型的监督微调提供了关键数据支撑。其创新性地融合议会演讲、新闻、税务指南等多样来源,并执行针对OCR噪声、重复片段及敏感内容的精细过滤,显著提升了合成数据的真实性与安全性。该数据集不仅缓解了丹麦语等小语种在指令跟随任务中的数据匮乏困境,更推动了多语言NLP中数据增强策略的前沿探索,为构建更包容的语言技术生态树立了典范。
以上内容由遇见数据集搜集并总结生成


