Rekipjan/uyghurtext
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Rekipjan/uyghurtext
下载链接
链接失效反馈官方服务:
资源简介:
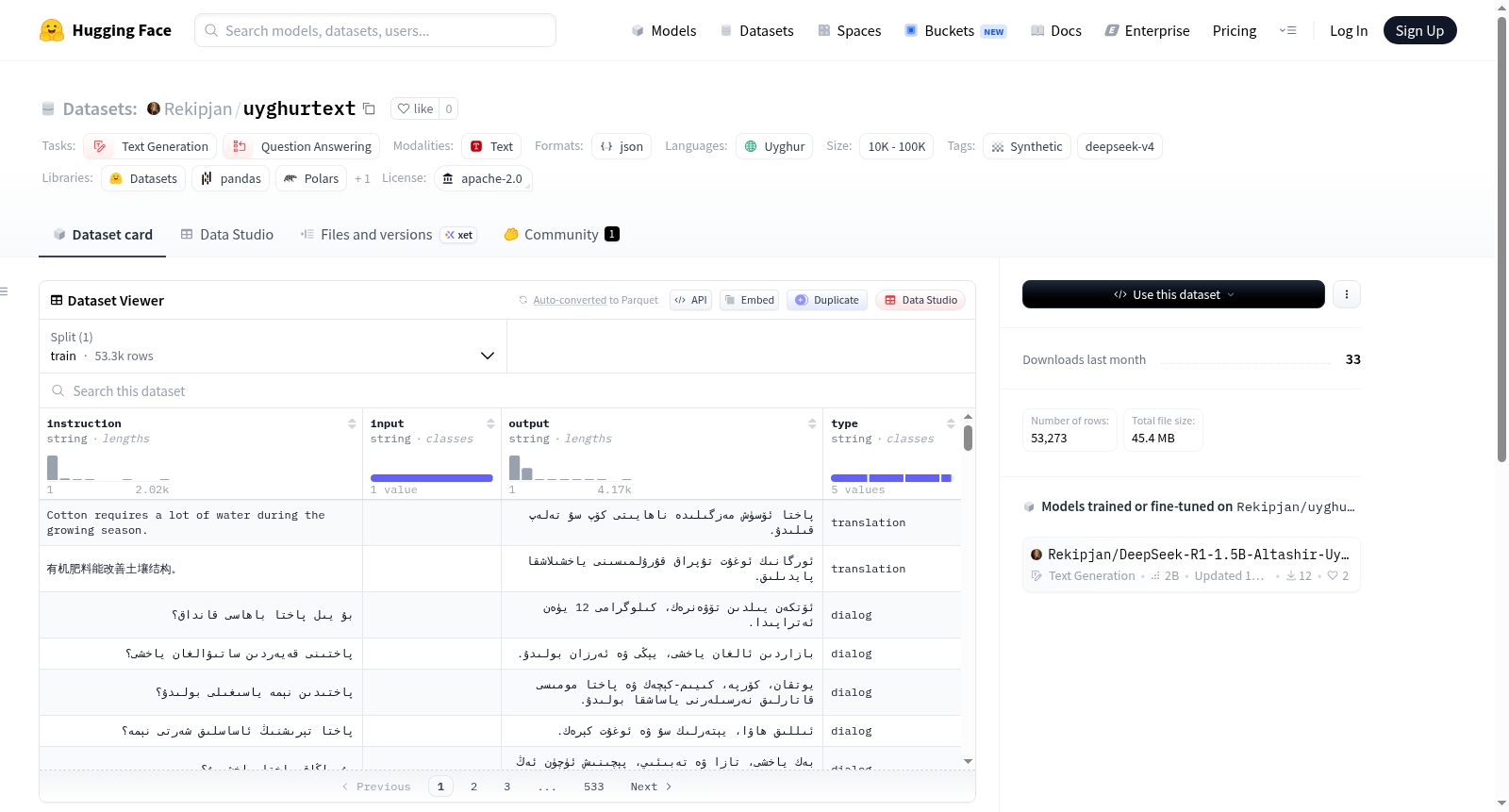
这是一个合成的维吾尔语文本数据集,名为维吾尔语文本数据集(合成)。数据集通过DeepSeek-V4-Flash作为教师模型生成,包含53,273个样本,分为五个类别:对话(30.76%)、推理(29.07%)、问答(28.92%)、创意(9.53%)和翻译(1.73%)。该数据集主要用于文本生成和问答任务,语言为维吾尔语,规模在1万到10万之间。
This is a synthetic Uyghur text dataset named Uyghur Text Dataset (Synthetic). The dataset is generated via DeepSeek-V4-Flash acting as the teacher model, containing 53,273 samples categorized into five types: Dialog (30.76%), Reasoning (29.07%), QA (28.92%), Creative (9.53%), and Translation (1.73%). The dataset is primarily used for text-generation and question-answering tasks, in the Uyghur language (ug), with a size between 10K and 100K.
提供机构:
Rekipjan
搜集汇总
数据集介绍
构建方式
uyghurtext数据集是一个专门针对维吾尔语文本生成与问答任务的高质量合成数据集。其构建过程依托DeepSeek-V4-Flash模型作为教师模型,通过知识蒸馏技术自动生成多样化的文本样本。数据涵盖了对话、推理、问答、创意写作及翻译五大类别,总计53,273条样本,其中对话类占比30.76%,推理类占29.07%,问答类占28.92%,创意类占9.53%,翻译类占1.73%。这种基于先进大语言模型的合成方法,确保了数据在内容丰富性和语言准确性上的高标准。
特点
该数据集的核心特点在于其类别分布的均衡性与多样性。对话、推理与问答三大核心类别占比相近,共同构成数据主体,适合训练具有通用对话与逻辑推理能力的模型。创意与翻译类别虽占比略低,但为模型提供了额外的创造性表达与跨语言转换能力。数据全部以维吾尔语呈现,标签清晰,且支持直接用于text-generation和question-answering任务,使得模型能够同时掌握多轮对话、逻辑推理及精准问答等复合能力。
使用方法
使用uyghurtext数据集时,可将其直接加载为监督式微调数据。对于文本生成任务,需基于对话、推理或创意类别进行序列到序列的训练,将用户输入作为指令或上下文,生成对应的维吾尔语答复。对于问答任务,则利用QA类别构建问题-答案对进行模型优化。建议将数据集按8:1:1比例划分为训练、验证与测试集,以兼顾模型泛化能力评估。亦可结合维吾尔语特有的词法特征进行预处理,如添加特殊标记以区分不同任务类型。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的数据稀缺问题长期制约着相关技术的发展。维吾尔语作为中亚地区广泛使用的语言,其数字化语料库建设尤为薄弱。为此,研究人员于近期利用DeepSeek-V4-Flash大语言模型作为教师模型,通过合成技术构建了名为uyghurtext的维吾尔语文本数据集。该数据集由相关机构主导创建,包含53,273个样本,覆盖对话、推理、问答、创意写作和翻译五大类别,旨在为维吾尔语的文本生成与问答任务提供基础训练资源。作为首个大规模合成维吾尔语数据集,它有效弥合了该语言在深度学习研究中数据匮乏的缺口,推动了低资源语言处理技术的进步。
当前挑战
该数据集面临的核心挑战在于合成数据的真实性与领域适应性。首先,数据由大模型自动生成,尽管规模可观,但可能无法完全捕捉维吾尔语的自然表达习惯及文化语境,导致模型在真实场景中泛化能力不足。其次,构建过程中需解决低资源语言的质量控制难题,包括确保语法正确性、术语一致性及避免偏见注入,而当前仅依靠单一教师模型容易引入系统性偏差。此外,数据集类别分布不均,翻译类样本仅占1.73%,可能影响多任务学习效果。这些挑战要求后续研究探索混合人工标注与数据增强策略,以提升数据集的鲁棒性和实用性。
常用场景
经典使用场景
在低资源自然语言处理领域,维吾尔语因其语法复杂性和语料稀缺性而长期面临技术瓶颈。UyghurText数据集作为首个大规模合成维吾尔语文本资源,其经典使用场景集中于多任务监督微调,涵盖对话生成、推理问答、创意写作及机器翻译等核心能力。研究者可基于该数据集的五类标注(对话、推理、问答、创意、翻译),系统性地训练生成式语言模型,使其掌握维吾尔语的句法结构、语义理解及跨语言转换能力,从而弥合该语种在预训练阶段的数据缺失鸿沟。
衍生相关工作
围绕该数据集催生的经典工作主要聚焦于数据合成质量验证与模型适应性改进。研究者开发了基于DeepSeek-V4-Flash的迭代蒸馏框架,证明教师模型的知识可高效迁移至轻量级学生模型,并衍生出针对维吾尔语形态丰富特性的分词对齐算法。同时,有工作利用该数据集对比真实标注与合成数据对生成模型性能的影响,揭示了合成数据在低资源场景下的噪声鲁棒性优势。此外,基于此数据集的多任务联合训练方案已成为后续维吾尔语指令微调基准,启发了一系列针对突厥语族的跨语种合成数据生成策略。
数据集最近研究
最新研究方向
该数据集聚焦于低资源语言(维吾尔语)的自然语言处理前沿,通过DeepSeek-V4-Flash教师模型合成高质量语料,涵盖对话、推理、问答、创意及翻译五大核心任务,弥补了维吾尔语通用文本资源的匮乏。其合成策略代表了当前大模型蒸馏与小样本数据增强的最新趋势,为少数民族语言智能交互、多模态理解及跨语言迁移学习提供了关键基础设施。在民族地区数字化建设与语言保护热点下,该数据集有力推动了维吾尔语生成式AI的实证研究,有望加速智能客服、教育辅助等应用落地,具有显著的学术价值与社会意义。
以上内容由遇见数据集搜集并总结生成


