setswana-sentiment
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/dsfsi/setswana-sentiment
下载链接
链接失效反馈官方服务:
资源简介:
DSFSI Setswana Sentiment是一个用于情感分析的数据集,包含3,555条Setswana语(ISO 639-3: `tsn`)的Twitter推文,由三位母语为Setswana的标注者进行标注。数据集提供了完整的标注时间戳、语言识别元数据以及每位标注者的标签,支持下游建模和标注质量研究。数据集分为训练集(2,762条)、验证集(346条)、测试集(346条)和一个完整配置(3,555条),其中训练/验证/测试集仅包含三种核心情感类别(积极、消极、中性),并按共识标签以80/10/10的比例分层分配。数据集还包含标注者标签、时间戳、共识类型等元数据,适用于情感分类器的训练与评估,以及标注质量研究。数据预处理包括用户名、提及、URL等敏感信息的替换,以及大小写归一化。数据集的主要局限性包括Twitter数据的特定性、标签分布不均衡(消极和中性标签占主导),以及标注时间跨度对一致性的影响。数据集采用Creative Commons Attribution 4.0 International (CC BY 4.0)许可发布。
DSFSI Setswana Sentiment is a dataset for sentiment analysis, containing 3,555 Setswana language (ISO 639-3: `tsn`) Twitter tweets annotated by three native Setswana speakers. The dataset provides complete annotation timestamps, language identification metadata, and labels from each annotator, supporting downstream modeling and annotation quality research. The dataset is divided into a training set (2,762 tweets), a validation set (346 tweets), a test set (346 tweets), and a full configuration (3,555 tweets). The training/validation/test sets only include three core sentiment categories (positive, negative, neutral) and are stratified by consensus labels in an 80/10/10 ratio. The dataset also includes metadata such as annotator labels, timestamps, and consensus types, making it suitable for training and evaluating sentiment classifiers, as well as for annotation quality research. Data preprocessing includes the replacement of sensitive information such as usernames, mentions, and URLs, as well as case normalization. The main limitations of the dataset include the specificity of Twitter data, imbalanced label distribution (dominated by negative and neutral labels), and the impact of annotation time span on consistency. The dataset is released under the Creative Commons Attribution 4.0 International (CC BY 4.0) license.
创建时间:
2026-04-23
原始信息汇总
数据集概述
- 数据集名称:DSFSI Setswana Sentiment
- 许可证:Creative Commons Attribution 4.0 International (CC BY 4.0)
- 语言:茨瓦纳语(Setswana,ISO 639-3:
tsn) - 任务类别:文本分类
- 标签:情感分析、茨瓦纳语、非洲语言、低资源语言、Twitter
- 数据集大小:约 3,555 条推文(1K < n < 10K)
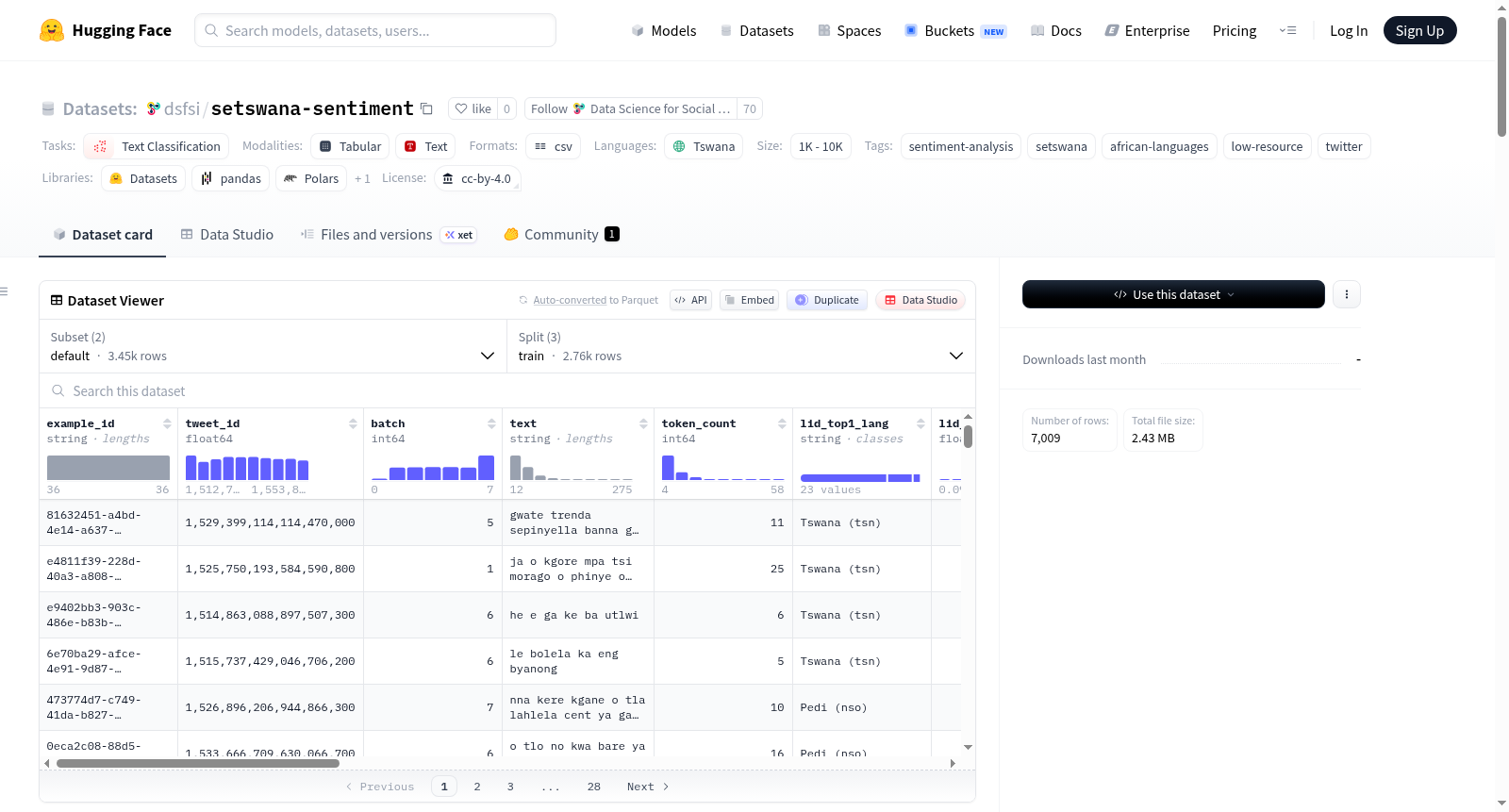
数据集结构
数据集包含三个分类划分和一个完整配置:
| 划分 | 样本数 | 用途 |
|---|---|---|
train |
2,762 | 微调/训练 |
validation |
346 | 模型选择和超参数调优 |
test |
346 | 最终评估 |
full |
3,555 | 包含全部推文及逐标注者标签、元数据和时间戳 |
train/validation/test划分仅包含 积极、消极、中立 三个核心情感类别,按共识标签以 80/10/10 比例分层抽样(随机种子 42)。共识标签为Mixed、Indeterminate或Disagreement的样本不包含在这些划分中,但保留在full配置中。
建议使用的列
-
训练/评估情感分类器:
- 输入:
text(已预处理的推文文本) - 目标:
consensus_label(值:Positive、Negative、Neutral)
- 输入:
-
标注质量/分歧研究:
ann1_label、ann2_label、ann3_label(逐标注者标签)ann1_timestamp、ann2_timestamp、ann3_timestamp(UTC 提交时间)consensus_type(共识类型:unanimous、majority、disagreement)
-
语言相关过滤:
lid_top1_lang、lid_top1_score、lid_top2_lang、lid_top2_score、lid_top3_lang、lid_top3_score
列说明
| 列名 | 类型 | 描述 |
|---|---|---|
example_id |
string | 标注样本的唯一标识符 |
tweet_id |
string | 原始 Twitter 状态 ID |
batch |
int | 0 表示训练/校准批次,1–7 表示生产批次 |
text |
string | 预处理后的推文文本(作为模型输入) |
token_count |
int | 推文中的 Token 数量 |
lid_top1_lang |
string | AfroLID 最佳语言预测 |
lid_top1_score |
float | lid_top1_lang 的置信度分数 |
lid_top2_lang |
string | 次佳语言预测 |
lid_top2_score |
float | lid_top2_lang 的置信度分数 |
lid_top3_lang |
string | 第三佳语言预测 |
lid_top3_score |
float | lid_top3_lang 的置信度分数 |
ann1_label |
string | 标注者 1 的标签(积极、消极、中立、混合、不确定) |
ann1_timestamp |
string | 标注者 1 提交标签的 UTC ISO-8601 时间戳 |
ann2_label |
string | 标注者 2 的标签 |
ann2_timestamp |
string | 标注者 2 提交的 UTC 时间戳 |
ann3_label |
string | 标注者 3 的标签 |
ann3_timestamp |
string | 标注者 3 提交的 UTC 时间戳 |
consensus_label |
string | 多数投票标签。若三位标注者全部不一致则为 Disagreement |
consensus_type |
string | 共识类型:unanimous(3/3)、majority(2/3)、disagreement(无多数) |
label_id |
int | (仅划分中)consensus_label 的整数 ID:Positive: 0、Negative: 1、Neutral: 2 |
文本预处理
text 字段已进行预处理:用户名、提及、URL 等潜在识别信息已被替换为占位符 Token,话题标签已规整,文本已转为小写。由于隐私原因,原始推文文本未包含在此数据集中。
标签方案
| 标签 | 描述 |
|---|---|
Positive |
推文表达积极情感 |
Negative |
推文表达消极情感 |
Neutral |
推文表达中立情感 |
Mixed |
推文同时表达积极和消极情感 |
Indeterminate |
推文难以理解、使用其他语言或无法被可靠分类 |
标注者
三位茨瓦纳语母语的本科生对语料进行了标注。身份已匿名化为 Ann.1、Ann.2 和 Ann.3(所有记录中稳定不变)。
完整数据集标签分布
| 标签 | 数量 | 占语料百分比 |
|---|---|---|
| Neutral | 1,489 | 41.9% |
| Negative | 1,445 | 40.6% |
| Positive | 520 | 14.6% |
| Disagreement | 47 | 1.3% |
| Indeterminate | 33 | 0.9% |
| Mixed | 21 | 0.6% |
- 标注者间一致性(Randolphs free-marginal κ):0.76(按惯例为“优秀”水平)。
快速开始
python from datasets import load_dataset
分类划分(仅积极、消极、中立)
ds = load_dataset("dsfsi/setswana-sentiment") print(ds["train"][0]["text"], "→", ds["train"][0]["consensus_label"])
完整数据集(包含所有元数据和逐标注者标签)
full = load_dataset("dsfsi/setswana-sentiment", "full")
预期用途
- 训练和评估茨瓦纳语及相关班图语言的情感分类器。
- 研究标注者分歧、标注质量监控以及多标注者任务中的时间效应。
- 对多语言和非洲语言预训练语言模型进行基准测试。
局限性
- 语料来自 Twitter(2021–2022 年),反映了该平台当时的语境、话题和用户群体。
- 消极和中立标签占主导地位(合计约 82%),积极标签占比不足。
- 主要的成对混淆是消极与中立之间,反映了茨瓦纳语政治和社会评论中常见的间接和讽刺表达——这是数据本身的特性,而非标注者质量问题。
- 标注是异步收集的;每条推文的标注者间时间跨度是一致性的强预测因子,并在每条样本中报告。
搜集汇总
数据集介绍
构建方式
该数据集由三位茨瓦纳语母语标注者协作构建,共采集并标注了3,555条来自Twitter平台的推文。标注过程采用异步方式,每位标注者独立对每条推文赋予情感标签,包括积极、消极、中立、混合及不确定五个类别。数据经过严格的预处理,用户名、提及、链接等潜在可识别信息被替换为占位符,并统一转换为小写字母。最终通过多数投票机制生成共识标签,针对标签一致性进行了分层抽样,按照80/10/10的比例划分为训练集、验证集和测试集,并额外提供一个包含完整元数据的全集配置。
特点
该数据集的显著特点在于其兼具系统严谨性与深度研究价值。除核心情感标签外,数据集详尽收录了每位标注者的独立标签及提交时间戳,支持标注者间分歧与时序效应的深入分析。同时,集成了AfroLID语言识别元数据,便于进行语言相关过滤。数据分布方面,中立与消极类别占据主导地位,反映了茨瓦纳语社交媒体评论中常见的间接表达与讽刺修辞。标注者间一致性达到自由边界卡帕系数0.76,体现了“极佳”的标注质量。
使用方法
使用该数据集时,可通过HuggingFace Datasets库便捷加载。对于情感分类模型的训练与评估,推荐使用默认配置,以'text'字段作为输入,'consensus_label'作为目标标签,支持对预训练语言模型进行微调。研究人员若聚焦于标注质量或分歧分析,则可加载'full'配置,利用每位标注者的独立标签、时间戳以及共识类型等元数据。数据集提供的Python快速启动代码支持直接调用,用户可根据需要选择包含完整信息或仅含三类共识标签的数据子集。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的语料库建设一直是推动语言技术普惠化的重要瓶颈。茨瓦纳语(Setswana)作为非洲南部广泛使用的班图语系语言,其情感分析研究长期受限于标注数据的匮乏。DSFSI Setswana Sentiment数据集由南非比勒陀利亚大学数据科学促进社会影响小组的研究人员于2026年创建,包括Idris Abdulmumin、Mokgadi Penelope Matloga等学者。该核心研究问题聚焦于为茨瓦纳语提供首个高质量的Twitter情感标注语料,包含3,555条推文并由三位母语者独立标注,旨在支撑情感分类模型训练并推动标注质量研究。该数据集的发布填补了茨瓦纳语情感分析资源的空白,为非洲低资源语言的自然语言处理研究提供了重要基准。
当前挑战
该数据集所面临的挑战首先体现在领域问题的复杂性上:茨瓦纳语作为低资源语言,缺乏大规模预训练语料与成熟的情感分析模型,且Twitter文本中普遍存在的间接表达与反讽使得情感极性判断极为困难,尤其是负面与中性类别的混淆率较高。在构建过程中,研究者需要应对标注者间一致性的控制,尽管总体Kappa系数达0.76,但异步标注导致的时间跨度差异成为预测一致性的重要变量。此外,数据集存在类别不均衡问题,正面情感样本仅占14.6%,而需剔除的混合、不确定与分歧标签也增加了数据筛选的难度。隐私保护要求下无法提供原始推文,进一步限制了文本复原与跨平台迁移的可行性。
常用场景
经典使用场景
在低资源非洲语言的自然语言处理研究中,情感分析是一项极具挑战性的任务,尤其是当语料稀缺且标注资源匮乏时。Setswana-Sentiment数据集专为茨瓦纳语(Setswana)的推文情感分类而设计,包含3,555条经过三位母语者独立标注的推文,并提供了Positive、Negative和Neutral三类共识标签。该数据集的经典使用场景是训练和评估面向茨瓦纳语的情感分类模型,研究者可利用其提供的训练、验证和测试划分,开展监督学习实验。由于数据源自社交媒体平台,其内容真实反映日常表达中的情感倾向,因而成为探索低资源语言情感分析方法的基准资源。
实际应用
在实际应用层面,Setswana-Sentiment数据集为茨瓦纳语社交媒体情感监控提供了关键基础设施。政府机构、舆情分析公司和社会科学研究团队可基于该数据集训练的情感分类器,实时追踪公众对政策、事件或品牌的态度变化。例如,在博茨瓦纳的政治选举期间,该系统能够快速识别支持与批评性言论,辅助舆论分析。此外,该数据集还可用于多语言情感分析系统的扩展,帮助将情感识别能力推广至其他班图语系语言,服务于跨语言的市场调研和客户反馈分析。
衍生相关工作
该数据集衍生了一系列围绕低资源语言情感分析的经典研究工作。一方面,它被用于微调多语言预训练模型(如XLM-R、AfriBERTa),验证其在茨瓦纳语上的情感理解能力,并推动针对非洲语言的特定预训练策略。另一方面,数据集包含的标注者级元数据启发了关于标注分歧建模的研究,部分学者据此开发了基于时间戳和共识类型的分歧预测模型。此外,该数据集还与其他低资源语言情感数据集联合使用,构建了跨语言的迁移学习基准,显著推动了非洲本土语言自然语言处理技术的进步。
以上内容由遇见数据集搜集并总结生成


