japanese-anime-speech-v2
收藏Hugging Face2024-06-30 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/joujiboi/japanese-anime-speech-v2
下载链接
链接失效反馈官方服务:
资源简介:
japanese-anime-speech-v2是一个音频-文本数据集,旨在训练自动语音识别模型。该数据集包含300,506个音频片段及其对应的转录文本,来源于视觉小说。数据集的目标是提高自动语音识别模型(如OpenAI的Whisper)对动漫和其他类似日本媒体对话的转录准确性。音频格式为mp3,采样率为16000Hz,平均音频长度为5.5秒。这是japanese-anime-speech-v2系列的第一版,与前一版本相比,音频质量有所调整,未过滤NSFW内容。数据集主要由女性声音组成,词汇围绕爱情、关系和幻想等主题,可能不完全反映现实世界的说话模式。未来计划包括创建安全工作和NSFW内容的分离,改进文本格式,以及扩展数据集来源。
japanese-anime-speech-v2 is an audio-text dataset intended for training automatic speech recognition (ASR) models. It contains 300,506 audio clips and their corresponding transcriptions, sourced from visual novels. The dataset aims to enhance the transcription accuracy of automatic speech recognition models such as OpenAI's Whisper for dialogues in anime and other similar Japanese media. The audio is in MP3 format with a sampling rate of 16000 Hz, and the average length of each audio clip is 5.5 seconds. This is the first iteration of the japanese-anime-speech-v2 series; compared to the prior version, the audio quality has been adjusted, and no NSFW content has been filtered. The dataset predominantly features female voices, with its vocabulary centered on themes including love, relationships, and fantasy, and may not fully reflect real-world speech patterns. Future plans for the dataset include creating a separation between safe-for-work and NSFW content, improving text formatting, and expanding the dataset's source materials.
创建时间:
2024-06-26
原始信息汇总
Japanese Anime Speech Dataset V2
概述
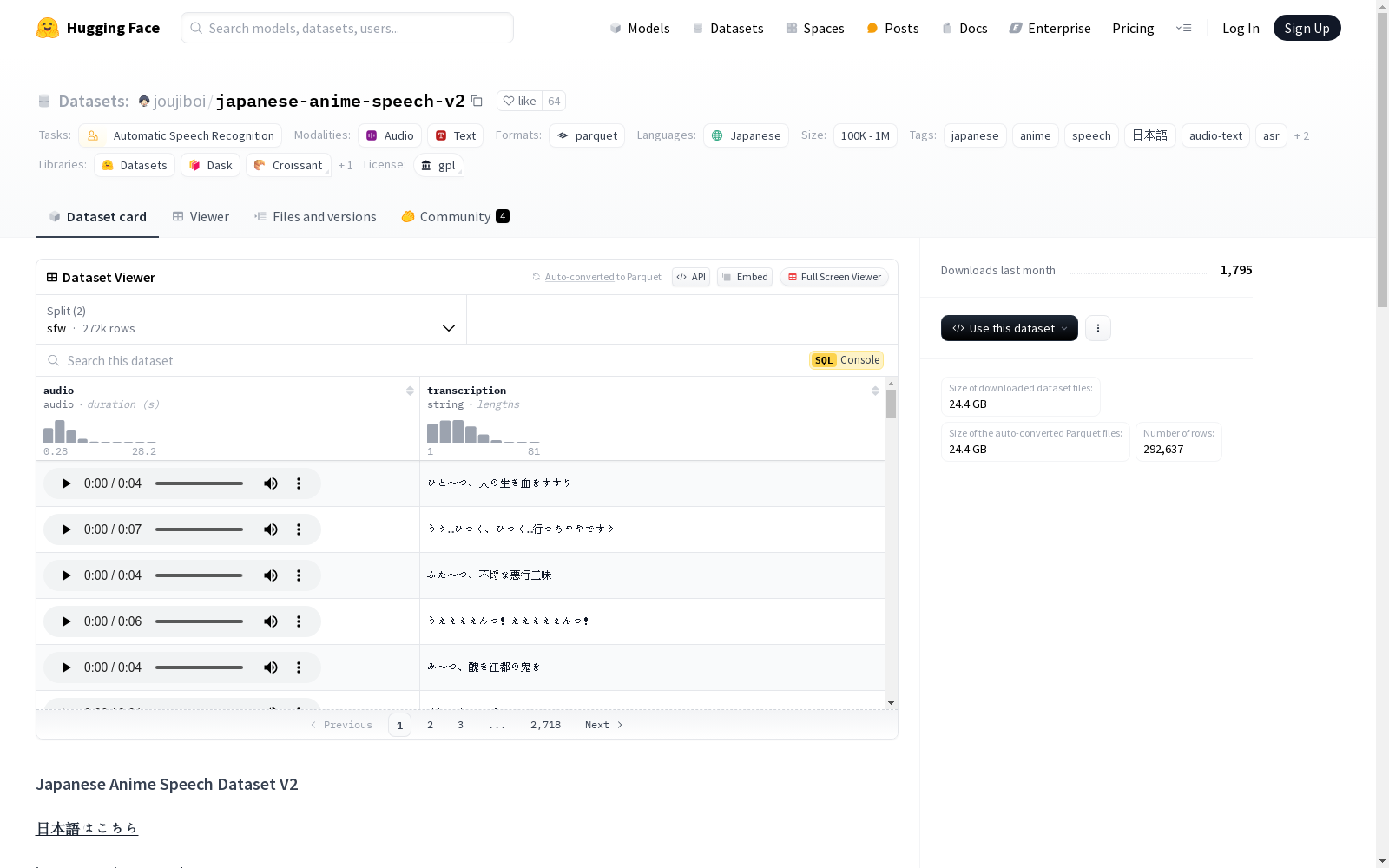
japanese-anime-speech-v2 是一个用于训练自动语音识别模型的音频-文本数据集。该数据集包含 292,637 个音频片段 及其对应的转录文本,来源于各种视觉小说。
数据集信息
- 音频-文本对数目: 292,637
- 安全内容音频时长: 397.54小时 (86.8%)
- 非安全内容音频时长: 52.36小时 (13.2%)
- 平均安全内容音频长度: 5.3秒
- 数据来源: 视觉小说
- 音频格式: mp3 (128kbps)
- 最新版本: V2 - 2024年6月29日
数据集特点
- 音频特征:
- 采样率: 16000 Hz
- 文本特征:
- 数据类型: 字符串
数据集分割
- 安全内容 (sfw):
- 字节数: 19174765803.112
- 样本数: 271788
- 非安全内容 (nsfw):
- 字节数: 2864808426.209
- 样本数: 20849
数据集大小
- 下载大小: 24379492733 字节
- 数据集大小: 22039574229.321 字节
配置
- 默认配置:
- 安全内容文件路径: data/sfw-*
- 非安全内容文件路径: data/nsfw-*
版本变更
- 从 V1 到 V2 的变化:
- 数据集大小显著增加,从 73,004 增加到 292,637 个音频-文本对
- 音频格式从 mp3 (192kbps) 改为 mp3 (128kbps),以提高存储效率
- 安全内容和非安全内容分为不同的分割
- 重复字符已规范化
- 删除了不含对话的音频行
- 删除了低质量的音频行
偏差与限制
- 数据集主要来源于视觉小说,导致性别偏向女性声音,且词汇围绕爱情、关系和幻想等主题
- 音频质量较高,可能导致与现实世界说话模式不完全一致
- 包含非安全内容,不适用于所有应用场景
- 转录文本未进行格式化或清理,可能影响部分文本样本的质量
未来计划
- 继续扩展数据集,包括更多来源
使用与引用
- 数据集对商业和非商业用途开放
- 使用时无需强制引用,但建议在衍生作品中提供超链接
搜集汇总
数据集介绍
构建方式
Japanese Anime Speech V2数据集是一个专门为训练自动语音识别模型设计的音频-文本数据集,主要来源于各类视觉小说。该数据集包含292,637个音频片段及其对应的转录文本,音频格式为128kbps的mp3文件。数据集通过从视觉小说中提取对话音频,并对其进行转录和分类,构建了包含安全内容(sfw)和不适合所有观众的内容(nsfw)两个独立的分割集。为确保数据质量,重复字符、无对话的音频行以及低质量音频行均被移除。
使用方法
该数据集可用于训练和评估自动语音识别模型,特别是针对日本动漫和视觉小说领域的语音识别任务。用户可以通过Hugging Face平台下载数据集,并根据需要选择安全内容或不适合所有观众的内容进行训练。由于数据集包含未经处理的转录文本,建议在使用前对文本进行必要的清理和格式化。数据集开放供商业和非商业用途使用,使用时建议注明数据来源以支持开源社区的发展。
背景与挑战
背景概述
Japanese Anime Speech Dataset V2(japanese-anime-speech-v2)是一个专为训练自动语音识别模型而设计的音频-文本数据集,由292,637个音频片段及其对应的转录文本组成,主要来源于视觉小说。该数据集由joujiboi团队于2024年6月29日发布,旨在提升自动语音识别模型(如OpenAI的Whisper)在转录动漫及其他类似日本媒体对话时的准确性。动漫领域的语音具有独特的声学特征和语言模式,与常规日语口语存在显著差异,因此该数据集的构建填补了这一领域的研究空白。尽管数据集规模较前一版本显著扩大,但其并非V1版本的扩展,而是独立构建的全新数据集。
当前挑战
该数据集在构建和应用过程中面临多重挑战。首先,动漫语音的独特性和多样性对模型的泛化能力提出了较高要求,尤其是语音中的情感表达、语速变化以及特殊词汇的使用,增加了转录的难度。其次,数据集的构建过程中,音频来源局限于视觉小说,导致数据存在性别偏向(以女性声音为主)和领域偏向(集中于爱情、幻想等主题),可能限制了模型在其他场景下的表现。此外,数据集包含NSFW内容,尽管已尝试将其与SFW内容分离,但分类规则并非完全可靠,可能影响模型的应用范围。最后,转录文本未经过格式化和清理处理,重复字符和低质量样本的存在可能进一步影响模型的训练效果。
常用场景
经典使用场景
在自动语音识别(ASR)领域,japanese-anime-speech-v2数据集被广泛用于训练和评估模型,特别是针对动漫和视觉小说中的日语对话。由于动漫语音具有独特的声调和语言特征,传统ASR模型在处理这类语音时往往表现不佳。该数据集通过提供大量来自视觉小说的音频-文本对,帮助研究人员开发出更精准的ASR模型,尤其是针对动漫风格的语音识别。
解决学术问题
该数据集解决了ASR模型在处理动漫语音时的准确性问题。传统ASR模型通常基于标准日语语音进行训练,难以应对动漫中常见的夸张语调、情感表达和特殊词汇。通过引入大量动漫风格的语音数据,japanese-anime-speech-v2显著提升了模型在动漫语音识别任务中的表现,填补了这一领域的研究空白。
实际应用
在实际应用中,japanese-anime-speech-v2数据集为动漫字幕生成、语音助手开发以及动漫内容的多语言翻译提供了重要支持。例如,基于该数据集训练的ASR模型可以自动生成动漫对话的字幕,极大提高了字幕制作的效率。此外,该数据集还可用于开发面向动漫爱好者的语音助手,使其能够更好地理解和响应用户的语音指令。
数据集最近研究
最新研究方向
近年来,随着自动语音识别(ASR)技术的快速发展,针对特定领域语音数据的训练需求日益增长。Japanese Anime Speech V2数据集作为专注于日本动漫语音识别的资源,为研究者提供了大量来自视觉小说的音频-文本对。该数据集不仅涵盖了丰富的动漫语音特征,还特别区分了适合和不适合所有受众的内容,进一步提升了其在ASR模型训练中的实用性。当前研究热点集中于如何利用该数据集优化Whisper等先进模型,以更好地捕捉动漫中独特的语音模式和情感表达。此外,该数据集在性别和领域词汇上的偏差也为研究者提供了探索模型公平性和泛化能力的机会。通过持续扩展数据源和改进数据质量,该数据集有望在动漫语音识别领域发挥更大的影响力。
以上内容由遇见数据集搜集并总结生成


