ccnews2024plus
收藏Hugging Face2025-08-01 更新2025-08-02 收录
下载链接:
https://huggingface.co/datasets/AbedGarra/ccnews2024plus
下载链接
链接失效反馈官方服务:
资源简介:
CCNews-Plus是一个基于斯坦福CCNews数据集的扩展数据集,它将Common Crawl News语料库的时间范围扩展到了2024年6月之后。数据集通过应用受到datatrove启发的优质过滤和去重方法,保证了新闻文章的质量。数据集按月进行分割存储,每个分割包含一个.jsonl.gz文件,每个文件中包含了去重和过滤后的新闻文章。
创建时间:
2025-07-29
原始信息汇总
📰 CCNews-Plus 数据集概述
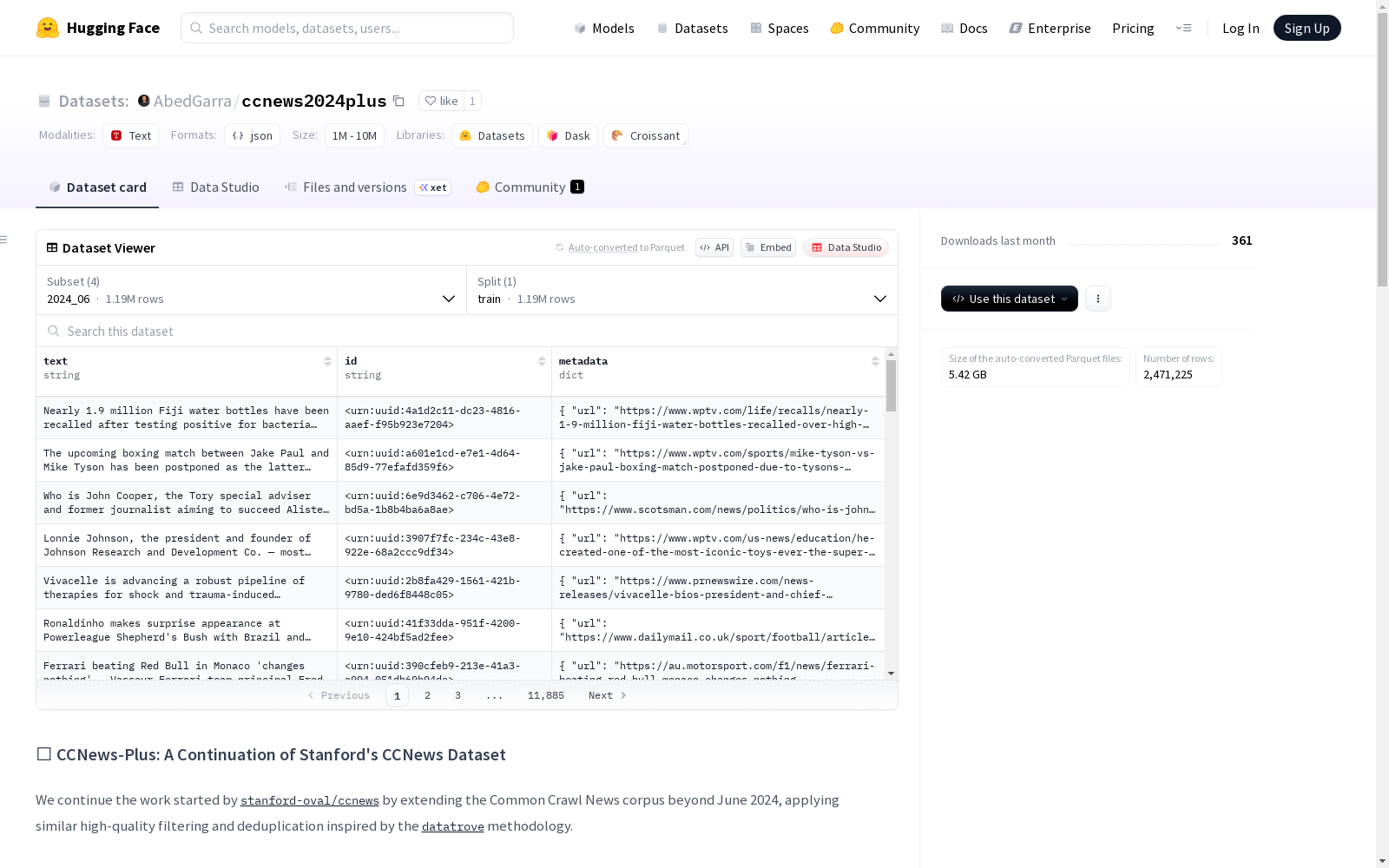
📦 数据集结构
- 语言: 仅英语 (
language: "en") - 月度划分: 每个月份数据存储在独立子目录中 (
2024_06/,2024_07/,2024_08/) - 文件格式:
.jsonl.gz文件,每行代表一个经过去重和过滤的新闻文章 - 2024年6月数据: 包含与Stanford原始数据集的对比数据
📊 数据模式
每篇文章包含3个主要字段:
text: 完整文章内容(通过trafilatura提取)_id: 文章唯一标识符metadata: 包含丰富元数据的对象,包括:url: 文章URLdate: 文章发布日期warc_date: Common Crawl爬取日期publisher: 发布者域名title: 文章标题author: 文章作者tags: 文章标签categories: 文章分类sitename: 网站名称file_path: Common Crawl文件路径language: 语言language_score: 语言置信度分数token_count: 文章token数量
📥 加载示例
python from datasets import load_dataset
加载特定月份
dataset_june = load_dataset("AbedGarra/ccnews2024plus", "2024_06") dataset_july = load_dataset("AbedGarra/ccnews2024plus", "2024_07") dataset_august = load_dataset("AbedGarra/ccnews2024plus", "2024_08")
流式加载并预览前10篇文章
dataset = load_dataset("AbedGarra/ccnews2024plus", "2024_07", streaming=True) for i, article in enumerate(dataset[train]): if i >= 10: break print(f"Article {i+1}:") print(f"Title: {article[metadata][title]}") print(f"Publisher: {article[metadata][publisher]}") print(f"Date: {article[metadata][date]}") print(f"Text preview: {article[text][:200]}...") print("-" * 50)
📌 可用子集
2024_06: 2024年6月文章2024_07: 2024年7月文章2024_08: 2024年8月文章
搜集汇总
数据集介绍
构建方式
在新闻文本挖掘领域,CCNews2024plus数据集延续了斯坦福大学CCNews项目的工作范式,采用Common Crawl新闻语料库作为数据源,通过严格的过滤和去重流程构建而成。该数据集基于datatrove方法论的启发,运用trafilatura工具从原始网页中提取结构化内容,确保文本质量和元数据完整性。数据按月划分存储,每个月份独立配置,采用jsonl.gz压缩格式保存,既保证了数据存取效率,又便于分布式处理。
特点
作为新闻文本分析的重要资源,CCNews2024plus的显著特征体现在其丰富的元数据标注体系。每条记录不仅包含原始文本内容,还附有详尽的出版信息、作者信息、分类标签等结构化字段。特别值得注意的是,数据集采用双重时间标记策略,既记录文章原始发布时间,也保留爬虫抓取时间,为时序分析提供多维视角。语言识别置信度和词符计数等量化指标,则为文本质量评估提供了客观依据。
使用方法
针对不同研究需求,该数据集提供灵活的加载方式。用户可通过Hugging Face数据集库直接调用特定月份子集,或采用流式处理模式逐条预览数据。典型应用场景包括:加载完整月份数据进行批量分析,或通过迭代器逐条检查样本属性。示例代码清晰展示了如何访问标题、出版商、日期等关键字段,以及如何截取文本片段进行快速质量检查,为研究者提供了即用的入门范例。
背景与挑战
背景概述
CCNews2024Plus数据集是斯坦福大学CCNews数据集的延续性工作,由研究团队基于Common Crawl新闻语料库构建而成,旨在提供2024年6月之后的英文新闻数据。该数据集继承了原始数据集的高质量标准,采用先进的去重和过滤技术,确保数据的纯净性和可用性。通过集成trafilatura工具提取丰富的元数据,包括文章发布日期、作者、出版商等关键信息,为自然语言处理研究提供了多维度的分析基础。该数据集的发布填补了时序新闻数据的空白,对文本挖掘、舆情分析和语言模型训练等领域具有重要价值。
当前挑战
CCNews2024Plus数据集面临的挑战主要体现在两个方面:在领域问题层面,新闻文本的时效性和多样性要求模型具备动态适应能力,而数据中的噪声和偏见可能影响下游任务的性能;在构建过程层面,海量原始数据的去重和过滤消耗大量计算资源,精确的元数据提取依赖复杂的自然语言处理技术,跨月数据的时序一致性维护也增加了数据集的构建难度。这些挑战需要通过持续的算法优化和严格的质量控制来解决。
常用场景
经典使用场景
在自然语言处理领域,CCNews2024Plus数据集作为斯坦福CCNews数据集的延续,为研究者提供了2024年6月至8月的高质量英文新闻文本。该数据集经过严格的去重和过滤处理,特别适用于大规模语言模型的预训练任务。其按月划分的结构设计,使得研究者能够针对特定时间段的语言现象开展纵向研究,例如分析新闻语言随时间的演变规律。
数据集最近研究
最新研究方向
在自然语言处理领域,ccnews2024plus数据集作为斯坦福CCNews语料的延续,为研究者提供了2024年6月至8月的高质量英文新闻数据。该数据集凭借其精细的去重过滤机制和丰富的元数据结构,正被广泛应用于大语言模型预训练、新闻事件时序分析以及多模态学习等前沿方向。特别是在生成式AI快速发展的背景下,该数据集的时间连续性和内容多样性为研究新闻事件的演变规律、检测虚假信息以及探索跨领域知识迁移提供了重要支撑。
以上内容由遇见数据集搜集并总结生成


