CoderForge-Preview-v3-100000
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/laion/CoderForge-Preview-v3-100000
下载链接
链接失效反馈官方服务:
资源简介:
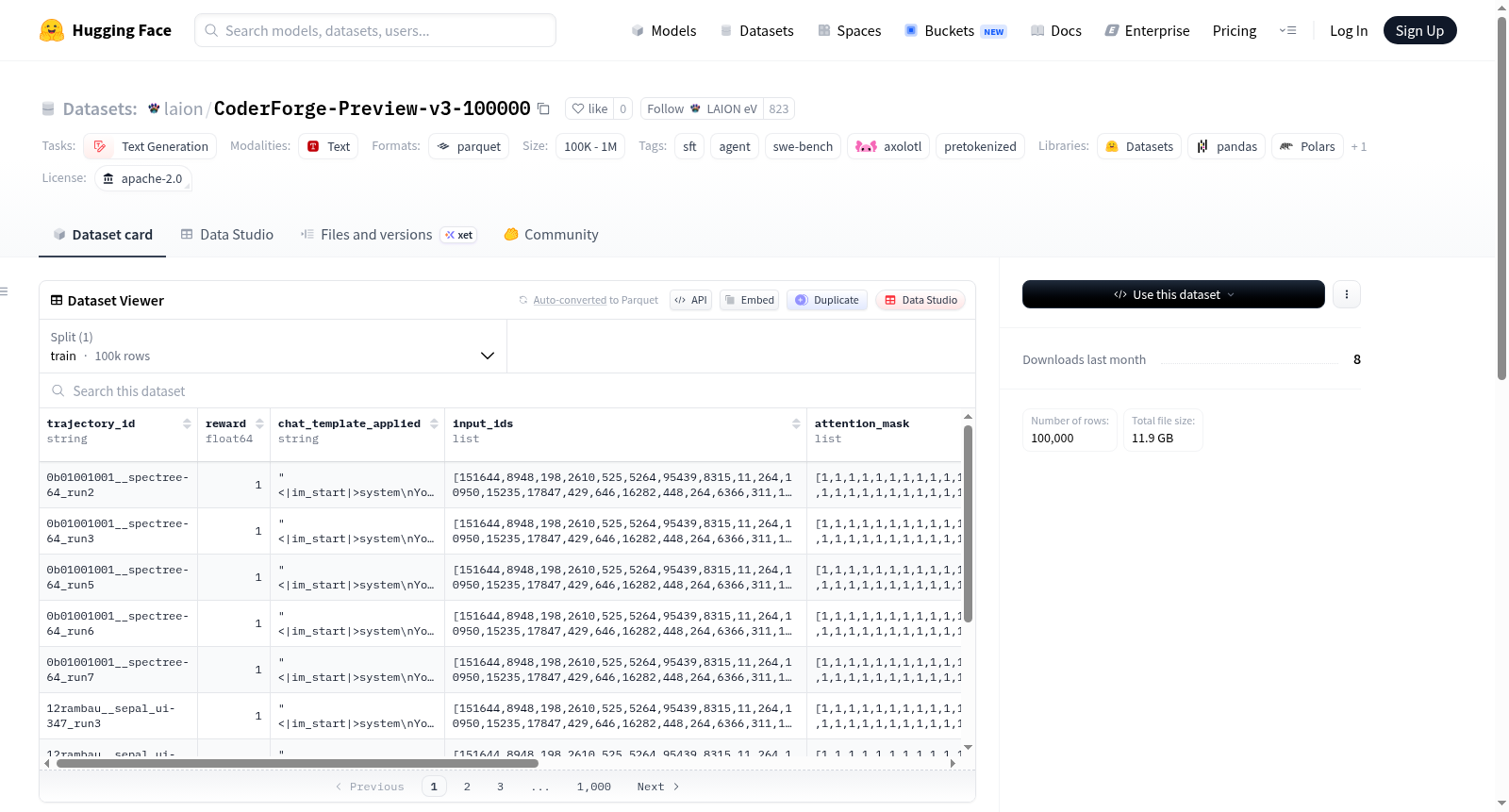
laion/CoderForge-Preview-v3-100000是togethercomputer/CoderForge-Preview数据集的一个子集,包含100,000行预处理的tokenized数据,适用于Qwen3模型。数据格式包括input_ids、attention_mask、labels等字段,其中attention_mask全为1,labels已应用-100掩码。数据集还包含chat_template_applied、trajectory_id、reward和source字段。数据来源于四个不同的源(R2E_Gym, SWE_Rebench, SWE_Smith, filtered_reward1),并通过确定性采样(seed=42)生成。适用于文本生成任务,特别是与Qwen3模型相关的应用。
laion/CoderForge-Preview-v3-100000 is a subset of the togethercomputer/CoderForge-Preview dataset, containing 100,000 rows of preprocessed tokenized data suitable for the Qwen3 model. The data format includes fields such as input_ids, attention_mask, labels, etc., where attention_mask is all 1s and labels have been masked with -100. The dataset also includes fields like chat_template_applied, trajectory_id, reward, and source. The data comes from four different sources (R2E_Gym, SWE_Rebench, SWE_Smith, filtered_reward1) and is generated through deterministic sampling (seed=42). It is suitable for text generation tasks, especially those related to the Qwen3 model.
提供机构:
LAION eV
创建时间:
2026-04-23
原始信息汇总
根据您提供的信息,以下是数据集详情页面的总结:
laion/CoderForge-Preview-v3-100000 数据集概述
数据集来源与大小
- 来源:该数据集是 togethercomputer/CoderForge-Preview 数据集中
trajectories-tokenized_qwencoder子集的行子集。 - 原始规模:来源数据集包含 155,144 行,分布在 4 个数据块(slugs)中。
- 当前规模:本数据集包含 100,000 行。
数据格式
- 预分词格式:数据已原生预分词,专为 Qwen3 模型设计(分词器与 Qwen2.5-Coder、Qwen3-Coder、Qwen3-8B 兼容)。
- 每行列字段:
input_ids: list[int32]:输入 token ID。attention_mask: list[int8]:注意力掩码(全部为 1,由本子集添加以触发 axolotl 对预分词数据集的自动检测)。labels: list[int64]:标签(已应用-100掩码)。chat_template_applied: str:用于调试的解码渲染文本。trajectory_id: str:轨迹 ID。reward: float64:奖励值。source: str:始终为"togethercomputer/CoderForge-Preview/trajectories-tokenized_qwencoder"。
数据采样方法
- 从所有 4 个原始数据块(R2E_Gym、SWE_Rebench、SWE_Smith、filtered_reward1)的串联结果中,使用确定性采样(种子 seed=42)抽取。
- 行子集是嵌套的。
主要标签
- 任务类型:文本生成(text-generation)
- 相关标签:sft、agent、swe-bench、axolotl、pre-tokenized
使用方式(Axolotl)
- 配置文件示例:
yaml
datasets:
-
path: laion/CoderForge-Preview-v3-100000 chat_template: chatml sequence_len: 32768
-
注意:上游数据中的序列长度可能超过 80,000 token,axolotl 会自动截断。
-
- Axolotl 会检测预分词列并跳过聊天模板渲染器。
许可证
- 数据集采用 Apache-2.0 许可证。
搜集汇总
数据集介绍
构建方式
在代码生成与智能体任务日益复杂的背景下,CoderForge-Preview-v3-100000数据集应运而生。该数据集是基于togethercomputer/CoderForge-Preview中已预分词轨迹数据的行子集,具体取自其中的trajectories-tokenized_qwencoder子集。构建时从全部四个源数据块(即R2E_Gym、SWE_Rebench、SWE_Smith和filtered_reward1)中采用确定性抽样策略(种子固定为42),最终拼接形成了包含10万条记录的数据集。每条记录保留了原生预分词格式,并额外补充了全为1的attention_mask列,以触发Axolotl对预分词数据集的自动识别。
特点
该数据集最显著的特点在于其高度适配Qwen3系列模型,采用与其共享的Qwen2.5-Coder/Qwen3-Coder分词器进行预处理,确保了完全兼容的token化格式。每条样本不仅包含input_ids与labels字段,其中labels已应用了-100掩码,还引入了reward分数与trajectory_id标识,便于进行强化学习或基于轨迹的偏好训练。此外,数据集中解码后的chat_template_applied字段可供调试,而行子集的嵌套结构则允许用户灵活选择不同规模的子样本。
使用方法
使用该数据集极为便捷,尤其推荐通过Axolotl框架进行微调。在配置文件中只需指定数据集路径为laion/CoderForge-Preview-v3-100000,并设置聊天模板为chatml,序列最大长度设为32768即可。Axolotl将自动识别预分词列并跳过聊模板渲染步骤,直接加载input_ids等原生字段。需要注意的是,上游单条序列长度可能超过8万token,而Axolotl会自动进行截断处理,因此无需额外预处理即可启动训练。
背景与挑战
背景概述
在大型语言模型(LLM)的研发进程中,代码生成与智能体任务已成为评估模型推理与执行能力的核心场景。CoderForge-Preview-v3-100000数据集由LAION与Together Computer等机构于2024年联合构建,从原始的CoderForge-Preview数据集中精选10万条轨迹,旨在为代码智能体微调提供高质量、预标记化的训练资源。该数据集聚焦于解决软件工程基准(如SWE-bench)中的复杂任务,通过整合R2E_Gym、SWE_Rebench等多元场景,显著提升了模型在真实世界编码挑战中的泛化能力。其发布推动了代码智能体模型从粗粒度生成向细粒度交互决策的演进,成为连接大规模预训练与领域适配的关键桥梁。
当前挑战
CoderForge-Preview-v3-100000所面临的挑战体现于双重维度。从领域问题层面,代码智能体任务要求模型具备长期依赖建模与多步推理能力,如处理超过80K token的序列,这突破了传统文本生成模型的长度限制与注意力机制瓶颈。从构建过程层面,原始数据来自四个来源的轨迹拼接,需解决格式不统一、奖励信号稀疏(如filtered_reward1)及负样本掩码(-100)标记的精确对齐问题;同时,确定性采样(seed=42)虽保证可复现性,但可能引入子集偏差,影响下游微调的分布鲁棒性。此外,预标记化数据对tokenizer兼容性(Qwen2.5/Qwen3系列)的严格依赖,进一步增加了跨框架(如Axolotl)部署的适配难度。
常用场景
经典使用场景
CoderForge-Preview-v3-100000数据集的核心用途在于对代码智能领域的语言模型进行监督式微调(SFT),特别是针对代码生成、软件工程任务中的智能体(Agent)行为进行训练。该数据集包含了来自多个软件工程基准的预分词轨迹数据,如R2E_Gym、SWE_Rebench和SWE_Smith,这些轨迹记录了模型在解决真实世界软件工程问题时的完整推理与操作序列。研究者可以利用这些高质且经过掩码处理的轨迹数据,引导模型学习如何理解复杂代码库、自主规划修复步骤并执行精确的代码修改,从而提升模型在自动化程序修复和代码理解方面的能力。
实际应用
在实际产业应用中,该数据集可直接用于训练能够辅助开发者进行日常软件维护的人工智能编码助手。基于此数据微调后的模型,能够自动分析GitHub Issue中的问题描述,在大型代码仓库中定位缺陷,生成并应用补丁,甚至执行回归测试,显著提升软件开发效率。此外,它还能赋能持续集成中的自动调试管道,在不依赖人工介入的情况下处理常见代码缺陷,缩短软件发布周期。对于企业级大型代码库的智能运维和DevOps自动化而言,CoderForge-Preview-v3-100000所培养的模型能力具有不可忽视的工程价值。
衍生相关工作
该数据集衍生自togethercomputer/CoderForge-Preview这一大规模轨迹集合,并经过精心筛选和多源拼接,衍生出了多个具有影响力的相关工作。基于此数据格式,研究者得以复现并改进SWE-agent和Devin等前沿工作,推动了从模型参数微调到轨迹数据挖掘的一系列探索,同时启发了针对长序列预分词数据的高效训练框架(如Axolotl中对该数据集的特殊支持)。此外,该数据集的预处理方式为后续构建更大规模、更高质量的软件工程轨迹数据集奠定了方法论基础,也成为衡量代码智能体学习效果的标准数据来源之一。
以上内容由遇见数据集搜集并总结生成


