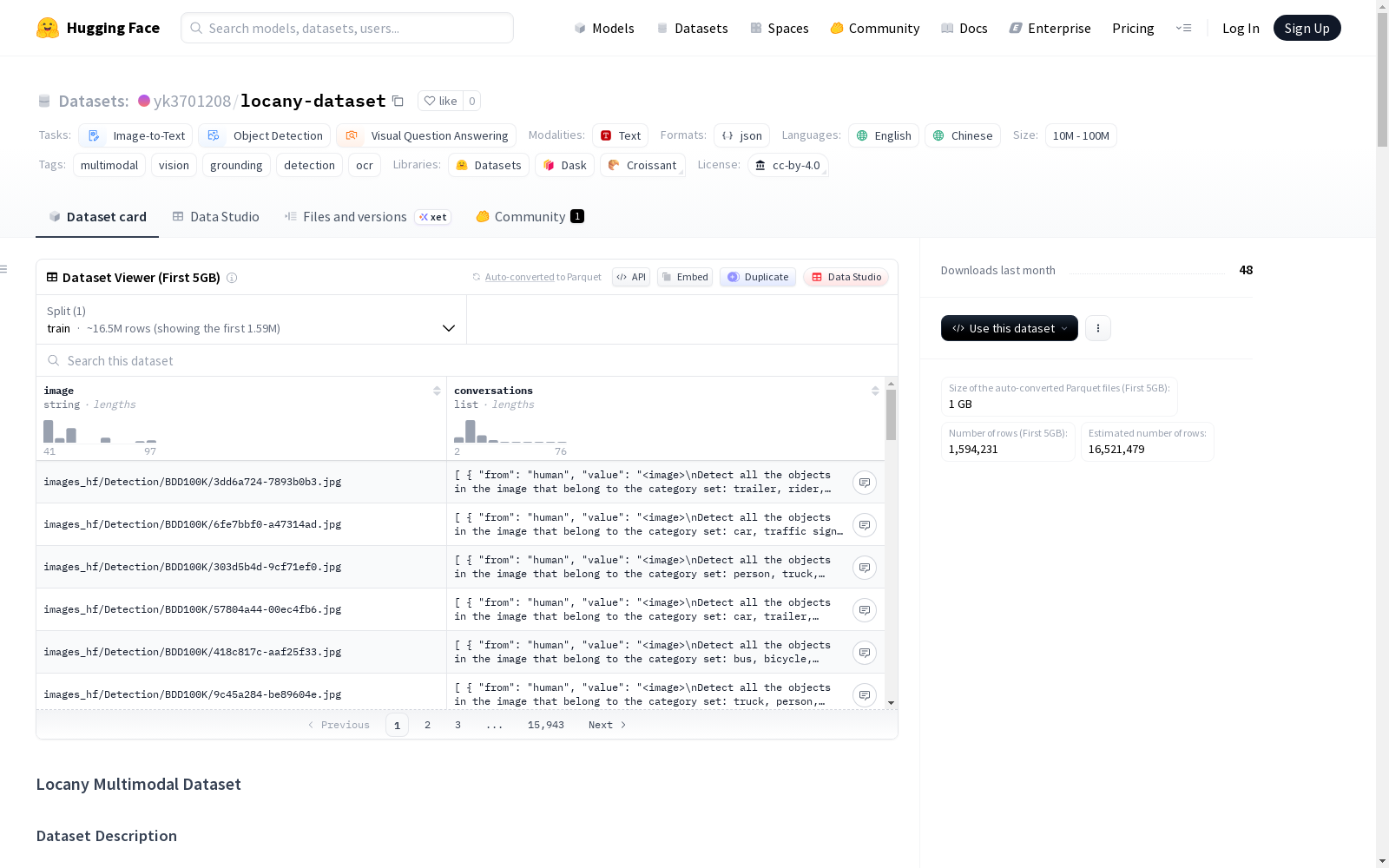
locany-dataset
收藏Locany Multimodal Dataset 概述
数据集基本信息
- 数据集名称:Locany Multimodal Dataset
- 发布者:Your Name
- 发布年份:2026
- 发布平台:Hugging Face
- 数据集地址:https://huggingface.co/datasets/yk3701208/locany-dataset
- 许可协议:CC-BY-4.0
- 任务类别:图像到文本、目标检测、视觉问答
- 规模类别:1M<n<10M
- 支持语言:英语、中文
- 标签:多模态、视觉、定位、检测、OCR
数据集描述
这是一个用于视觉语言任务的大规模多模态数据集,涵盖目标检测、定位、OCR和用户界面理解。
数据集统计
- 唯一图像总数:9,860,204
- 标注总数:28,768,853
- 总大小:2867.81 GB
- 类别数量:6
按类别细分
| 类别 | 数据集数量 | 标注数量 |
|---|---|---|
| 检测 | 32 | 16,334,270 |
| 定位 | 8 | 2,110,597 |
| 布局 | 15 | 1,141,706 |
| OCR | 13 | 2,060,741 |
| 指向 | 3 | 876,872 |
| UI | 16 | 6,244,667 |
数据集结构
locany-dataset/ ├── images_hf/ # 按类别/子文件夹组织的Parquet文件 │ ├── Detection/ │ │ ├── COCO/ │ │ ├── Object365/ │ │ └── ... │ ├── Grounding/ │ ├── OCR/ │ ├── UI/ │ └── ... └── annotations_hf/ # 按类别划分的JSONL标注文件 ├── Detection/ ├── Grounding/ ├── OCR/ └── ...
Parquet文件(图像)
图像以Parquet格式存储,包含两列:
image:原始图像字节(PNG格式)image_path:路径字符串(例如:images_hf/Detection/COCO/000000178538.jpg) 每个Parquet文件大小约为5GB。
标注文件(JSONL)
JSONL文件中的每一行包含: json { "image": "images_hf/Detection/COCO/000000178538.jpg", "conversations": [ {"from": "human", "value": "<image> Detect all objects..."}, {"from": "gpt", "value": "<ref>person</ref><box>x1 y1 x2 y2</box>..."} ] }
坐标格式
边界框使用归一化坐标,范围在[0, 1000]:
- 矩形:
<box>x1 y1 x2 y2</box> - 点:
<box>x y</box>转换为绝对坐标的公式:
absolute_x = normalized_x * image_width / 1000 absolute_y = normalized_y * image_height / 1000
类别说明
- 检测:带有识别物体类别边界框的目标检测数据集。
- 定位:将自然语言描述连接到图像区域的短语定位数据集。
- OCR:图像中的文本检测和识别。
- UI:用户界面理解,包括桌面、移动设备和网页截图。
- 布局:用于表单、表格和结构化文档的文档布局分析。
- 指向:基于点的定位任务。
去重处理
该数据集在所有类别中使用基于哈希的去重。每个唯一的图像(按内容)仅存储一次,即使在多个数据集或类别中使用也是如此。与简单的重复存储相比,这减少了大约30-50%的存储空间。
数据来源致谢
该数据集汇总并处理了来自多个公共来源的数据,包括COCO、Object365、OpenImages等。请参阅各个数据集的许可协议以了解具体限制。