odyssey-v0.5.1-16h-eval-preview-public
收藏Hugging Face2026-04-19 更新2026-04-20 收录
下载链接:
https://huggingface.co/datasets/ODYSSEYAILABS/odyssey-v0.5.1-16h-eval-preview-public
下载链接
链接失效反馈官方服务:
资源简介:
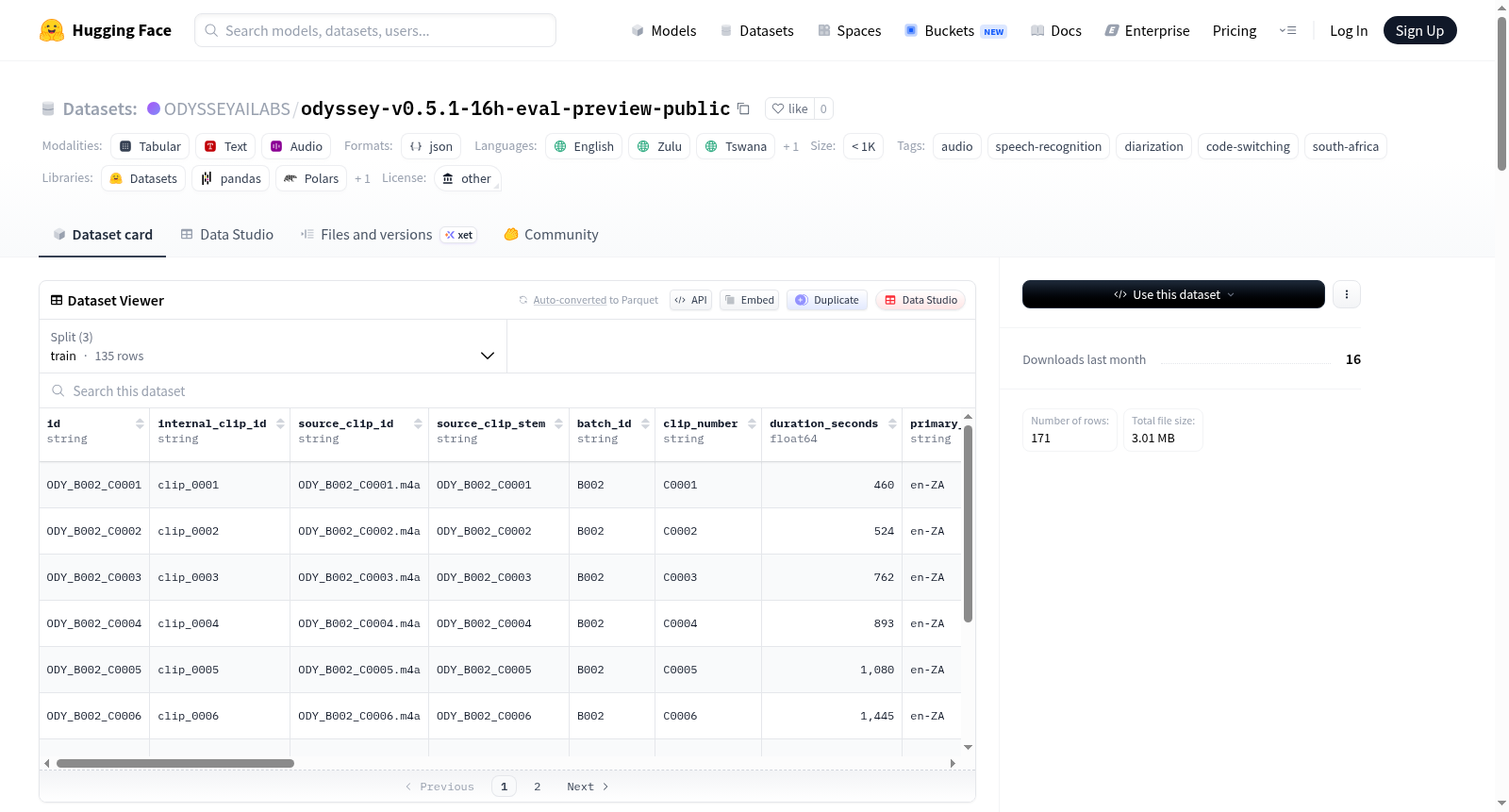
Odyssey V0.5.1 数据集是一个16小时的南非自动语音识别(ASR)评估预览版,专注于展示南非ASR的实际挑战,包括本地城市中的代码切换、多说话人轮流对话和重叠的会话语音。数据集包含171个连续对话片段,总计16.153小时的音频转录和元数据,其中94.7%的片段涉及代码切换,97.1%的片段包含3至5个说话人,94.7%的片段有明确的重叠语音部分。数据采用轻量级的Array-Tuple JSON格式存储,结构为[start, end, speaker, text],并分为训练、验证和测试三个JSONL文件。数据集主要语言为南非英语(en-ZA),同时包含其他南非语言如祖鲁语(zu-ZA)和茨瓦纳语(tn-ZA)等。该数据集旨在用于买家审查、模式验证和转录检查,不包含音频文件,音频需通过单独的受控仓库获取。
创建时间:
2026-04-14
原始信息汇总
🇿🇦 Odyssey V0.5.1 — 16H 评估预览数据集概述
数据集基本信息
- 数据集名称: Odyssey V0.5.1 — 16H Evaluation Preview (Code-Switched ASR)
- 发布机构: Odyssey AI Labs
- 许可证: other
- 语言: 英语 (en)、祖鲁语 (zu)、茨瓦纳语 (tn)、塞索托语 (st)
- 标签: audio、speech-recognition、diarization、code-switching、south-africa
数据集内容与结构
- 数据量: 16.153 小时(包含 171 个连续对话片段)。
- 核心特征:
- 语码转换: 94.7% 的片段(162/171)包含语码转换。
- 说话人复杂性: 97.1% 的片段(166/171)包含 3 至 5 名说话人。
- 显式重叠语音段: 94.7% 的片段(162/171)包含明确标注的重叠语音段。
- 数据来源: 涵盖批次 B002 至 B011(批次 B001 被有意排除在此公共预览范围之外)。
- 架构版本: V0.5.1,采用轻量级 Array-Tuple JSON 载荷 进行分段级结构化,格式为
[start, end, speaker, text]。 - 数据文件: 包含
train.jsonl、validation.jsonl和test.jsonl三个拆分文件,位于data/目录下。 - 辅助文件: 包含
sidecars/目录,用于保存片段级的质量检查(QA)标志和元数据。
语言分布快照
- 主要语言:
en-ZA(171个片段)。 - 次要语言: 包括
af-ZA、afr、nso、null、st-ZA、tn-ZA、ts-ZA、unknown、xho、zho、zu-ZA、zul。
使用说明与限制
- 性质: 此版本为 公开的转录文本与元数据预览,不包含音频访问权限。音频位于一个配套的门控仓库中。
- 预期用途: 仅用于买方审查、架构验证、转录文本检查以及数据摄取规划。
- 限制: 并非生产许可证授权。任何用于训练、微调、重新分发、发布衍生数据集或商业部署的行为,都需要与 Odyssey AI Labs 另行签订书面协议。
- 配套音频仓库建议名称:
odyssey-v0.5.1-16h-eval-audio-gated。
搜集汇总
数据集介绍
构建方式
在语音识别技术日益关注多语言混合与真实对话场景的背景下,Odyssey V0.5.1 数据集通过精心设计的采集流程构建而成。该数据集源自南非城市环境中的连续对话录音,涵盖了171段自然发生的会话片段,总时长约16小时。其构建核心采用了轻量级的Array-Tuple JSON负载结构,以[start, end, speaker, text]的元组形式精确标注每个语音片段的起止时间、说话人身份及对应文本,确保了细粒度的时序与说话人信息对齐。同时,数据集通过独立的sidecar文件保存了片段级别的质量评估标志与元数据,而分割为训练、验证与测试集的JSONL文件则提供了便于机器学习框架直接读取的表格化视图,整个架构兼顾了数据结构的清晰性与工程实用性。
特点
该数据集显著体现了南非多语言社会背景下语音数据的复杂特性。其中高达94.7%的片段包含语码转换现象,即说话者在英语与祖鲁语、茨瓦纳语、塞索托语等本地语言间频繁切换,真实反映了城市日常交流的混合语言模式。此外,97.1%的片段涉及3至5名说话人之间的轮流对话,且94.7%的片段明确标注了语音重叠区间,这为研究多说话人场景下的语音分离与角色识别提供了极具挑战性的真实语料。数据集语言构成以南非英语为主,同时广泛覆盖了多种南非本土语言变体,其高比例的复杂对话结构与重叠语音标注,使其成为评估自动语音识别与说话人日志系统在真实、嘈杂、多语言环境中性能的宝贵资源。
使用方法
本数据集主要面向学术研究与工业评估场景,旨在支持语音处理模型的验证与比较研究。使用者可通过提供的JSONL文件直接加载文本转录、说话人日志及时间戳信息,用于训练或测试自动语音识别、说话人分离或语码转换检测模型。需要注意的是,当前公开版本仅包含元数据与文本转录,音频文件需通过独立的受控仓库申请获取。在实际使用中,建议首先利用sidecar中的质量评估标志进行数据筛选,并依据Array-Tuple结构解析分段标注,以构建适用于特定任务的输入格式。该数据集明确限定了非商业用途,任何涉及模型训练、微调或商业部署的行为均需与数据提供方另行达成书面协议。
背景与挑战
背景概述
在语音识别技术日益成熟的背景下,处理多语言混杂与复杂对话场景成为研究前沿。Odyssey AI Labs于近期发布了Odyssey-v0.5.1-16h-eval-preview-public数据集,旨在应对南非地区语音识别的独特挑战。该数据集聚焦于城市环境中的自然对话,核心研究问题涉及代码切换、多说话人轮转及语音重叠的精准识别与标注。通过提供16小时的连续对话片段,数据集为语音处理领域引入了更贴近现实的应用场景,推动了多语言混合语音识别技术的发展,并对自动语音识别与说话人日志系统的评估标准产生了重要影响。
当前挑战
该数据集致力于解决南非地区自动语音识别中的代码切换与复杂对话分析问题,其核心挑战在于准确识别并标注多种语言在同一对话中的频繁切换,以及处理多说话人场景下的语音重叠与轮转。在构建过程中,研究人员面临数据采集与标注的复杂性,包括如何在高噪声城市环境中获取高质量音频,并设计轻量级的Array-Tuple JSON结构以实现细粒度的分段标注。此外,确保数据集的代表性与平衡性,涵盖多种南非本土语言变体,同时维护隐私与伦理标准,也是构建过程中的关键难点。
常用场景
经典使用场景
在语音处理领域,特别是针对多语言混杂环境的自动语音识别研究,Odyssey数据集以其独特的南非城市对话场景,为模型评估提供了关键基准。该数据集聚焦于真实的代码转换现象,其中超过94%的音频片段涉及英语与祖鲁语、茨瓦纳语等本土语言的动态切换,同时97%的片段包含3至5名说话者的复杂交互,并明确标注了重叠语音片段。这种设计使得研究者能够系统测试模型在嘈杂、多说话者环境下的识别鲁棒性,尤其适用于评估端到端语音识别系统在现实对话中的性能表现。
实际应用
在实际应用层面,Odyssey数据集所模拟的南非城市对话环境,为开发适用于多语言社会的语音技术提供了关键训练与测试数据。例如,在客户服务热线、远程医疗咨询或会议转录系统中,模型需要准确处理说话者之间的快速切换、语言混合及语音重叠。该数据集能够帮助企业和研究机构评估其语音识别系统在真实世界复杂场景下的可用性,进而优化语音助手、实时字幕生成和内容审核工具的性能,提升技术在多元化社区中的包容性与实用性。
衍生相关工作
围绕Odyssey数据集的结构化标注与复杂场景设计,已衍生出一系列专注于代码转换语音识别、说话人日志和重叠语音检测的研究工作。例如,部分研究利用其数组-元组(Array-Tuple)标注格式,开发了端到端的多任务学习框架,同时处理语音识别与说话人分离。其他工作则基于其多语言特性,探索了跨语言预训练模型在低资源语言混合场景下的迁移能力。这些衍生研究不仅推动了语音处理技术的前沿,也为后续类似数据集的构建提供了重要的方法论参考。
以上内容由遇见数据集搜集并总结生成


