avs-spot
收藏AVS-Spot 数据集概述
基本信息
- 任务类别: 特征提取、文本到视频
- 标注创建者: 专家生成
- 语言: 英语
- 标签: 伴随语音的手势、手势定位、视频理解、多模态学习
- 数据集名称: AVS-Spot
- 规模: 小于1K
- 源数据集: 扩展数据集
数据集简介
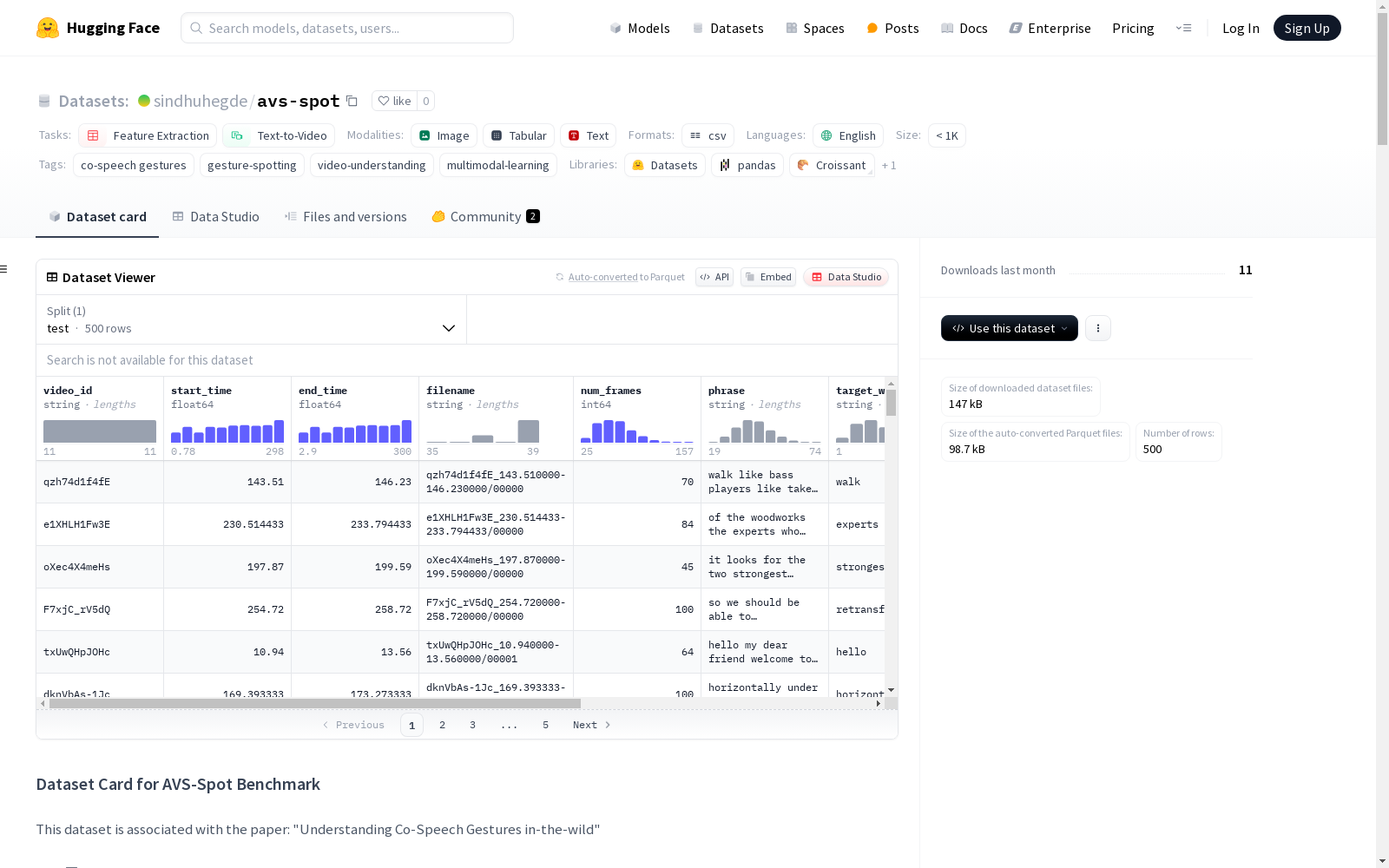
AVS-Spot 是一个用于评估手势单词定位任务的基准数据集。包含500个视频,采样自 AVSpeech 官方测试数据集。每个视频至少包含一个清晰的手势单词,标注为“目标单词”。此外,还提供其他标注,包括文本短语、单词边界和语音重音标签。
数据集结构
数据字段
video_id: YouTube 视频 IDstart_time: 开始时间(秒)end_time: 结束时间(秒)filename: 文件名及目标说话者裁剪编号num_frames: 预处理后的视频帧数phrase: 视频文本转录target_word: 目标单词(需定位的单词)target_word_boundary: 目标单词边界word_boundaries: 所有单词的边界stress_label: 目标单词是否被重读的二进制标签
数据实例
json { "video_id": "jnsuH9_qYyA", "start_time": 26.562700, "end_time": 29.802700, "filename": "jnsuH9_qYyA_26.562700-29.802700/00000", "num_frames": 83, "phrase": "app is beautiful it just is streamlined it", "target_word": "beautiful", "target_word_boundary": "[beautiful, 21, 37]", "word_boundaries": "[[app, 0, 11], [is, 12, 13], [beautiful, 21, 37], [it, 45, 47], [just, 48, 53], [is, 60, 63], [streamlined, 65, 81], [it, 82, 83]]", "stress_label": 1 }
数据集统计
| 数据集 | 分割 | 时长(小时) | 说话者数量 | 平均剪辑时长 | 视频数量 |
|---|---|---|---|---|---|
| AVS-Spot | test | 0.38 | 391 | 2.73 | 500 |
引用
bibtex @article{Hegde_ArXiv_2025, title={Understanding Co-speech Gestures in-the-wild}, author={Hegde, Sindhu and Prajwal, K R, Kwon, Taein and Zisserman, Andrew}, booktitle={arXiv}, year={2025} }
致谢
感谢 Piyush Bagad、Ragav Sachdeva 和 Jaesung Hugh 的宝贵讨论,以及 David Pinto 和 Ashish Thandavan 的支持。本研究由 EPSRC Programme Grant VisualAI EP/T028572/1 和 Royal Society Research Professorship RP extbackslash R1 extbackslash 191132 资助。