Science-T2I-Trainset
收藏Hugging Face2025-03-18 更新2025-03-19 收录
下载链接:
https://huggingface.co/datasets/Jialuo21/Science-T2I-Trainset
下载链接
链接失效反馈官方服务:
资源简介:
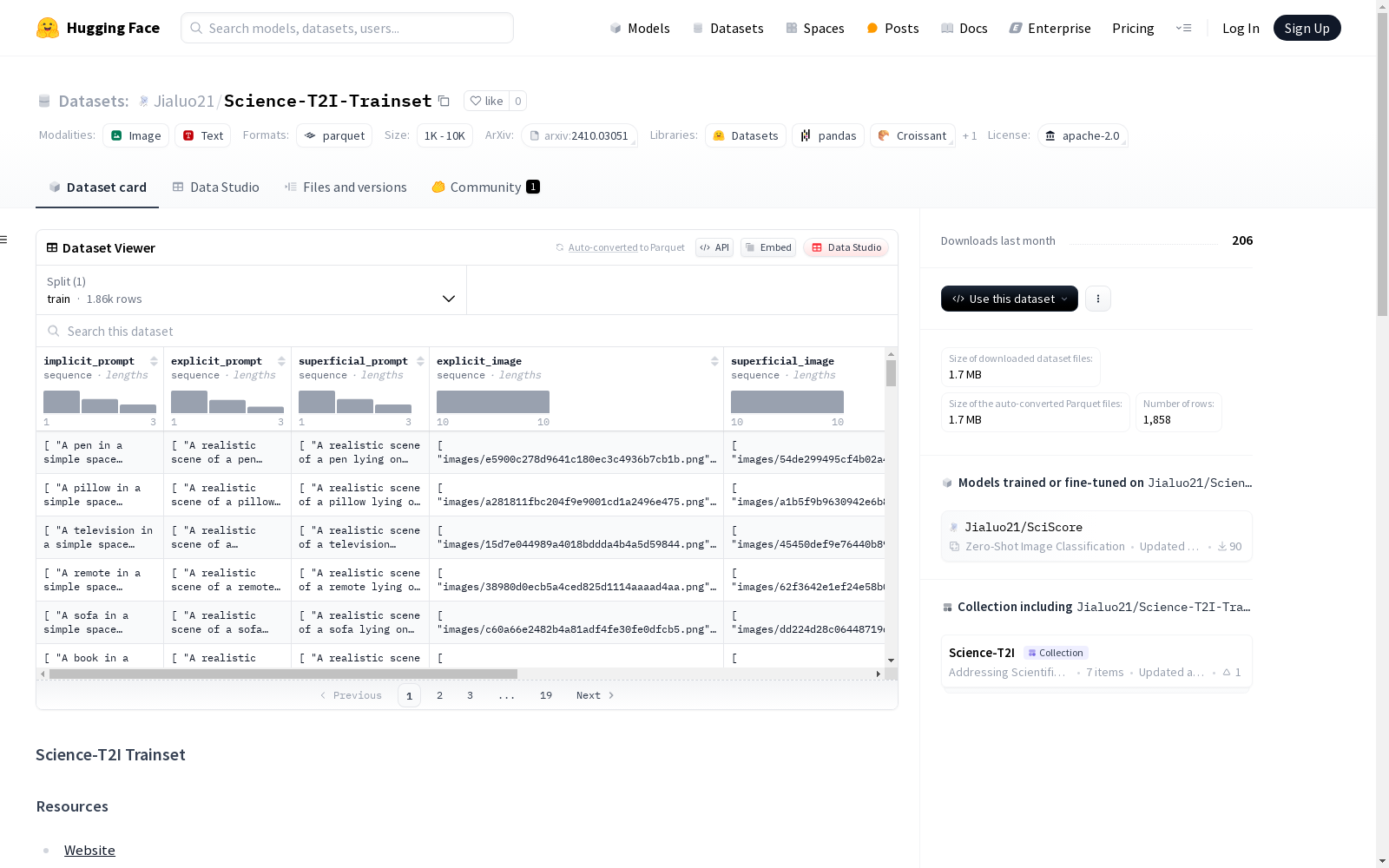
Science-T2I Trainset数据集是一个科学任务与图像生成的数据集,包含40,000张分辨率为1024x1024的图像。数据集的构建经历了任务定义、模板设计、主题生成、图像合成和人工验证等多个阶段。每个图像都配有一个隐式提示、一个显式提示和一个表面提示,以及对应的评分和类别信息。
The Science-T2I Trainset is a dataset for scientific task-oriented image generation, which contains 40,000 images with a resolution of 1024x1024. The construction of this dataset comprises multiple stages including task definition, template design, topic generation, image synthesis and manual verification. Each image is paired with an implicit prompt, an explicit prompt, a surface prompt, as well as corresponding scoring and category information.
创建时间:
2025-03-16
搜集汇总
数据集介绍
构建方式
Science-T2I-Trainset的构建过程采用了多阶段的策略,旨在生成高质量的科学图像数据集。首先,研究团队定义了具体的科学任务,并设计了三种不同类型的提示模板:隐式、显式和表面。随后,利用GPT-4o生成多样化的主题,并将其插入预定义的提示模板中。最后,通过Flux模型生成图像,并经过严格的人工筛选,确保数据集的高质量和相关性。
特点
Science-T2I-Trainset包含了40,000张分辨率为1024x1024的图像,每张图像均配有隐式、显式和表面三种提示类型。数据集还包含了场景评分、真实评分、类别和法律信息等丰富的元数据,为科学图像生成任务提供了全面的支持。其多样化的主题和高质量的图像使其成为科学图像生成领域的宝贵资源。
使用方法
用户可以通过Hugging Face平台下载Science-T2I-Trainset,并使用提供的Python代码进行数据加载和处理。数据集支持直接从Hugging Face Hub下载,并通过`load_dataset`函数加载。用户可以根据需要提取显式和表面图像,并进行进一步的分析或模型训练。该数据集的使用方法简单直观,适合各类科学图像生成任务的研究和开发。
背景与挑战
背景概述
Science-T2I-Trainset数据集由Jialuo Li及其团队于2023年创建,旨在推动科学图像生成领域的研究。该数据集通过结合自然语言处理与计算机视觉技术,生成了40,000张分辨率为1024x1024的科学相关图像。其核心研究问题在于如何通过多模态提示(如隐式、显式和表面提示)生成高质量的科学图像,并评估这些图像在科学场景中的适用性。该数据集的研究成果已在arXiv上发布,并提供了相关的代码和基准测试工具,为科学图像生成领域提供了重要的数据支持和技术参考。
当前挑战
Science-T2I-Trainset数据集在构建过程中面临多重挑战。首先,科学图像的生成需要高度精确的提示设计,以确保生成的图像符合科学场景的复杂性和多样性。其次,尽管使用了GPT-4o和Flux等先进技术进行自动化生成,但图像的质量和相关性仍需通过人工筛选来保证,这一过程耗时且资源密集。此外,数据集的评估标准(如场景评分和真实评分)需要兼顾科学准确性和视觉表现力,这对评估模型的开发提出了更高的要求。这些挑战不仅反映了科学图像生成领域的复杂性,也为未来的研究提供了重要的改进方向。
常用场景
经典使用场景
Science-T2I-Trainset数据集在科学图像生成领域具有重要应用,特别是在生成与科学任务相关的图像时,该数据集通过提供隐式、显式和表面三种不同类型的提示,帮助研究人员探索不同提示类型对生成图像质量的影响。经典使用场景包括科学教育材料的自动生成、科学可视化工具的开发以及科学传播中的图像生成任务。
实际应用
在实际应用中,Science-T2I-Trainset数据集被广泛用于科学教育、科研可视化以及科学传播等领域。例如,教育机构可以利用该数据集生成与教学内容相关的图像,增强学生的学习体验;科研人员则可以通过该数据集生成复杂的科学可视化图像,辅助数据分析和成果展示;科学传播者则可以利用该数据集生成吸引公众注意力的图像,提升科学传播的效果。
衍生相关工作
基于Science-T2I-Trainset数据集,研究人员开发了多项经典工作。例如,利用该数据集训练的生成模型在科学图像生成任务中表现出色,相关研究成果发表在顶级学术会议上。此外,该数据集还催生了多个科学图像生成工具和平台,如SciScore和Science-T2I-S&C Benchmark,这些工具为科学图像生成领域的研究和应用提供了重要支持。
以上内容由遇见数据集搜集并总结生成


