surrogate-1-training-pairs
收藏Hugging Face2026-04-28 更新2026-04-29 收录
下载链接:
https://huggingface.co/datasets/axentx/surrogate-1-training-pairs
下载链接
链接失效反馈官方服务:
资源简介:
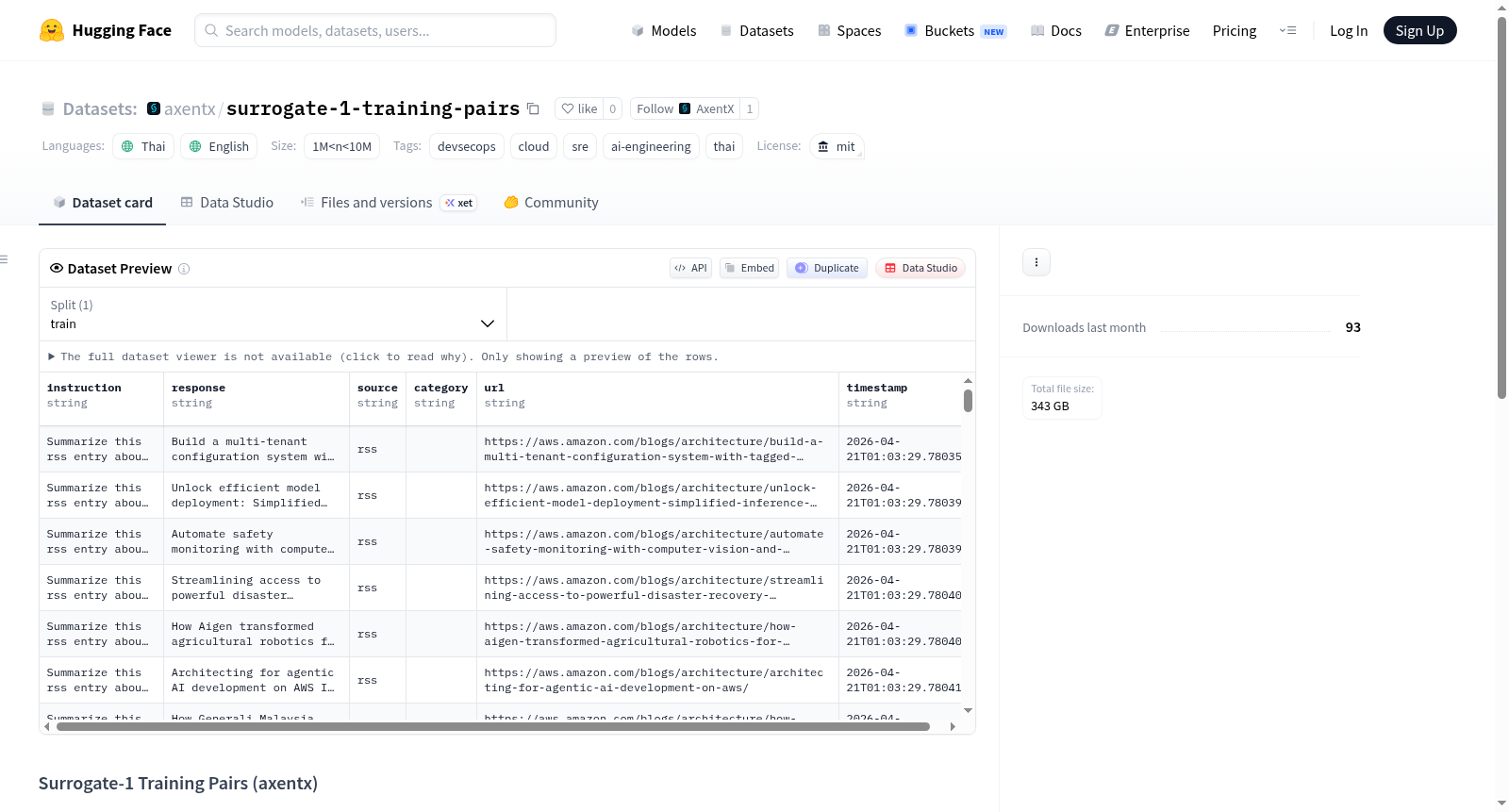
Surrogate-1训练对数据集(axentx)是一个专门针对DevSecOps、云计算和泰国市场的指令对数据集,用于微调Surrogate-1模型。数据集包含泰语和英语内容,采用MIT许可协议。数据规模在100万到1000万样本之间,以JSONL格式存储。数据来源多样,包括Claude代码转录(匿名化处理)、DevSecOps定时任务输出、经过筛选和清洗的公开GitHub代码模式、特定领域抓取的仓库README文件、网络爬取内容(RSS、博客、CVE)、代码检索对以及用于DPO的偏好对。所有数据均经过隐私处理,移除了真实姓名、雇主名称、公司关联信息、API密钥、令牌、机密以及内部Hermes追踪信息。该数据集适用于DevSecOps、云计算、站点可靠性工程(SRE)和AI工程等领域的研究和应用开发。
创建时间:
2026-04-28
原始信息汇总
数据集概述:Surrogate-1 Training Pairs (axentx)
基本信息
- 数据集名称:Surrogate-1 Training Pairs (axentx)
- 访问地址:https://huggingface.co/datasets/axentx/surrogate-1-training-pairs
- 语言:泰语(th)、英语(en)
- 许可证:MIT
- 数据集规模:1,000,000 ~ 10,000,000 条样本
标签与用途
- 标签:devsecops、cloud、sre、ai-engineering、thai
- 用途:用于微调 Surrogate-1 模型,涵盖 DevSecOps、云服务及泰国市场相关的指令对
数据集配置
- 默认配置:
default - 数据文件格式:JSONL(所有
*.jsonl文件) - 数据分割:训练集(train)
数据来源
数据集由以下多种来源的指令对构成:
- claude-*:来自 Claude Code 的匿名化对话记录
- ops-*:DevSecOps 定期任务输出的结果
- code-*:来自公开 GitHub 代码模式(已过滤和清洗)
- github-domain-*:从特定领域抓取的仓库 README 文件
- scraped-*:网络爬虫数据(包括 RSS、博客、CVE 信息)
- chroma-code-pairs-*:代码检索对
- dpo-pairs:用于 DPO(直接偏好优化)的偏好对
隐私保护
所有数据对已清除以下敏感信息:
- 真实姓名、雇主名称、公司关联信息
- API 密钥、令牌、机密信息
- 内部 Hermes 追踪信息
授权信息
- 许可证:MIT
- 发布方:Ashira / axentx
搜集汇总
数据集介绍
构建方式
该数据集名为Surrogate-1 Training Pairs,专为微调Surrogate-1模型而构建,聚焦于DevSecOps、云计算及泰国市场领域。数据来源多元且经过精心筛选,涵盖Claude Code匿名化脚本、DevSecOps定时任务输出、公开GitHub代码模式(经过滤与脱敏处理)、领域爬取的仓库README文件、网页爬虫收集的RSS、博客及CVE信息、代码检索对,以及用于DPO训练的首选项对。构建过程中严格剔除真实姓名、雇主信息、API密钥、令牌及内部追踪数据,确保隐私合规。
特点
该数据集具有规模宏大与隐私安全的双重特点,其样本量介于100万至1000万之间,属于大型指令对集合。所有数据均经过脱敏处理,去除个人身份信息与敏感凭证,同时保留技术领域的专业性。数据来源涵盖自动化运维日志、开源代码模式与安全情报,呈现跨领域的多样性。特别针对泰国市场与DevSecOps场景进行优化,使得模型在东南亚语言环境与云安全任务上具备更强的适配能力。
使用方法
数据集以default配置存储,训练数据以JSONL格式存放于单个文件,便于加载与处理。用户可通过Hugging Face Datasets库直接读取,如使用load_dataset函数指定路径,并选择train分片进行加载。适用于Supervised Fine-Tuning与DPO训练范式,开发者可结合Transformers或TRL库,将指令对用于模型微调,提升LLM在安全运维与泰语交互场景下的表现。
背景与挑战
背景概述
Surrogate-1 Training Pairs数据集由Ashira/axentx团队于近期创建,聚焦于DevSecOps、云原生及泰语市场下的AI工程领域。该数据集旨在为Surrogate-1模型的微调提供高质量的指令对,核心研究问题涉及如何通过精心筛选和匿名的技术对话、代码模式及安全运维日志,构建一个能够理解并执行开发安全运维一体化任务的领域专用语言模型。其影响力在于填补了面向泰语环境与云安全场景的指令微调数据空白,为东南亚地区AI工程化实践提供了重要的数据基础。数据集包含超过百万条涵盖DevSecOps流水线、云基础设施及代码安全审查的指令对,有望推动该领域模型在工业界及学术界的应用与评估。
当前挑战
该数据集面临的首要挑战是解决DevSecOps领域中的专业性与泛化性平衡问题:传统通用指令数据集难以覆盖云安全策略、CVE漏洞分析及运维自动化等深度垂直场景,而Surrogate-1需从海量技术对话与代码片段中提取高保真、低噪声的指令对,确保模型既能应对复杂的安全审计任务,又不丢失对通用代码模式的适应能力。构建过程中,团队遭遇了隐私清洗的严峻挑战——需从Claude Code转录、GitHub代码模式及网络爬虫数据中彻底剥离真实姓名、API密钥及内部追踪信息,同时保留语义完整性,这一脱敏流程在百万级数据规模下极易引入上下文断裂或意图丢失。此外,来源于多异构渠道(如cron输出、RSS博客、DPO偏好对)的数据格式统一性与质量控制亦构成显著技术障碍。
常用场景
经典使用场景
在DevSecOps与云原生技术深度融合的背景下,该数据集被广泛用于对大型语言模型进行指令微调,以提升模型在安全运维、云基础设施管理和持续集成/持续部署流程中的任务理解与执行能力。通过结合泰国市场的本地化需求,它特别适用于训练能够处理泰语与英语混合指令的智能运维助手,从而在跨国云服务环境中实现高效的多语言交互与自动化响应。
实际应用
在实际应用中,该数据集助力构建面向企业级云平台的智能排障与安全合规系统。例如,它可被用于训练自动化SECOP助手,实时分析CVE漏洞报告、监控RSS博客中的新兴威胁,并依据清理后的GitHub READMEs生成可部署的安全策略。在泰国市场的DevSecOps实践中,数据集驱动的模型能解析双语工单,自动执行Kubernetes集群巡检与密钥泄露检测,显著缩短了事件响应周期。
衍生相关工作
基于该数据集,衍生了多项标志性研究工作,包括利用DPO偏好对优化运维决策偏好的Surrogate-1系列模型,以及结合chroma-code-pairs实现跨仓库代码检索的智能代码审查系统。此外,研究者通过复用其隐私净化流程,提出了针对云日志脱敏的通用框架,并衍生出面向IT运维的指令数据集构建方法论,这些工作共同奠定了可复现、安全合规的DevSecOps模型训练范式。
以上内容由遇见数据集搜集并总结生成


