RefOI Dataset
收藏arXiv2025-04-23 更新2025-04-24 收录
下载链接:
https://vlm-reg.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
RefOI数据集是由美国密歇根大学等机构创建,包含约1487张图片,每张图片都标注有3个书面和2个口头指代表达式。该数据集的创建旨在解决现有数据集存在的数据泄露问题以及包含过多由大型语言模型生成的描述,缺乏真实人类对话中使用的口头语言的问题。
The RefOI dataset was developed by institutions including the University of Michigan in the United States and other relevant organizations. It comprises approximately 1,487 images, where each image is annotated with 3 written referring expressions and 2 oral referring expressions. The primary purpose of constructing this dataset is to address the shortcomings of existing datasets, which include data leakage, an overabundance of descriptions generated by large language models, and the absence of naturally occurring oral language in real human conversations.
提供机构:
美国密歇根大学计算机科学与工程分院
创建时间:
2025-04-23
搜集汇总
数据集介绍
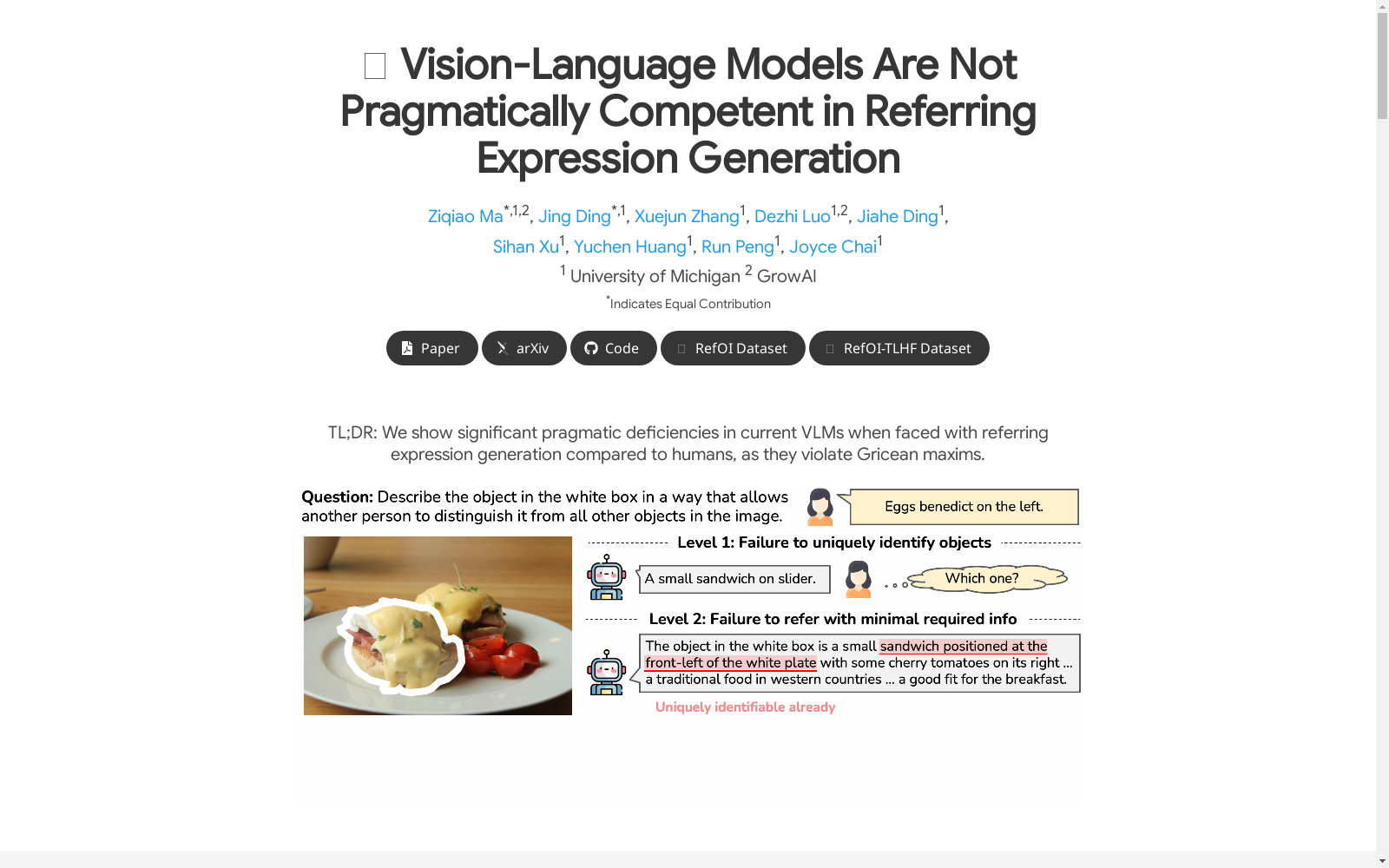
构建方式
RefOI数据集通过精心设计的标注流程构建而成,旨在解决现有指代表达数据集的局限性。研究团队从Open Images数据集中筛选了1,485张图像,涵盖25个MSCOCO类别和25个非MSCOCO类别,确保语义多样性和类别平衡。每个目标物体通过交互式标注界面收集了3条书面和2条口语指代表达,标注者被要求生成能够唯一识别物体的描述。为避免数据泄露问题,研究团队特意避开了MSCOCO训练集,并采用SentenceBERT嵌入进行语义聚类,确保所选类别与MSCOCO类别具有足够的语义距离。
特点
RefOI数据集的核心特点体现在其多模态标注和语用学考量上。该数据集不仅包含书面表达,还创新性地采集了真实口语指代数据,更贴近人类自然交流场景。通过系统设计,数据集覆盖了单实例和多实例场景,能够有效评估模型在复杂环境下的指代能力。特别值得注意的是,数据集标注严格遵循Grice会话准则,强调指代表达的独特性识别和最小信息量原则。与现有数据集相比,RefOI在类别平衡性(COCO与非COCO类别比例接近1:1)和标注质量(人类评估准确率达92.2%)方面具有显著优势。
使用方法
RefOI数据集支持指代表达生成(REG)和理解(REC)双任务评估。使用时建议采用分层评估策略:首先通过标准自动指标(如BLEU、ROUGE)进行初步筛选,再结合人类评估验证指代准确性。针对模型输出,应特别关注三类语用失误:未能唯一识别目标、包含冗余信息以及与人类语用偏好偏离。数据集提供的多实例场景特别适合评估模型在复杂环境下的指代能力。研究者还可利用口语与书面表达的对比,分析不同模态对指代策略的影响。为获得可靠结果,建议配合CogVLM-Grounding等先进REC模型进行交叉验证。
背景与挑战
背景概述
RefOI数据集由密歇根大学计算机科学与工程系的Ziqiao Ma等研究人员于2025年提出,旨在解决视觉语言模型(VLMs)在指代表达生成(REG)任务中语用能力不足的问题。该数据集包含1.5k张图像,每张图像标注了书面和口语形式的指代表达,重点关注Gricean语用原则在视觉语言交互中的应用。作为对传统RefCOCO系列数据集的补充,RefOI特别强调了指代唯一性和语用简洁性这两个核心维度,为评估模型的真实语用能力提供了新的基准。
当前挑战
RefOI数据集面临的主要挑战体现在两个方面:在领域问题层面,当前视觉语言模型难以生成符合人类语用习惯的指代表达,具体表现为无法保证指代唯一性、包含冗余信息以及与人类语用偏好不一致;在构建过程层面,数据集需要平衡COCO与非COCO类别对象,避免数据泄露问题,同时采集真实口语表达以更准确反映人类自然交流模式。此外,现有自动评估指标如BLEU、ROUGE等难以有效捕捉语用层面的表现差异,亟需开发新的评估框架。
常用场景
经典使用场景
在视觉语言模型(VLMs)的评估与优化研究中,RefOI数据集被广泛应用于指代表达生成(REG)任务的基准测试。该数据集通过包含1.5k张带有书面和口语指代表达标注的图像,为研究者提供了一个系统评估模型语用能力的平台。其典型使用场景包括分析模型在生成唯一标识性表达时的表现,以及检验模型是否遵循Gricean合作原则(如信息适量性、相关性和清晰性)。数据集特别适用于对比人类与模型生成的指代表达差异,例如通过空间线索与视觉特征的偏好分布揭示模型与人类语用策略的偏离。
衍生相关工作
RefOI数据集已衍生出多项重要研究工作:在模型架构方面,催生了如CogVLM-Grounding等融合显式视觉指针机制的模型;在评估方法上,推动了基于语用准则的REG新指标设计(如最小必要信息率)。相关研究还拓展至跨模态指代理解(REC)任务,例如利用该数据集验证视觉提示对降低指代歧义的作用。数据集构建方法亦被借鉴至3D场景指代数据集(如Referit3D)的开发中,促进了语用评估标准在更复杂环境的应用。
数据集最近研究
最新研究方向
近年来,RefOI数据集在视觉语言模型(VLMs)的语用能力评估领域引起了广泛关注。该数据集通过引入1.5k张图像及其标注的书面和口语指代表达式,为研究VLMs在指代表达生成(REG)任务中的语用缺陷提供了重要资源。前沿研究聚焦于三个关键方向:一是模型在唯一指代对象时的失败案例,揭示了其在Gricean质量准则上的不足;二是模型生成冗余或无关信息的倾向,违反了数量和相关准则;三是模型与人类语用偏好的偏差,尤其在空间线索利用上的显著差异。这些发现挑战了传统基于区域的标题生成评估方法,推动了语用感知模型和评估框架的发展,对实现更自然的人机交互具有重要意义。
相关研究论文
- 1Vision-Language Models Are Not Pragmatically Competent in Referring Expression Generation美国密歇根大学计算机科学与工程分院 · 2025年
以上内容由遇见数据集搜集并总结生成


