chinese-cosmopedia
收藏Hugging Face2024-09-18 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/opencsg/chinese-cosmopedia
下载链接
链接失效反馈官方服务:
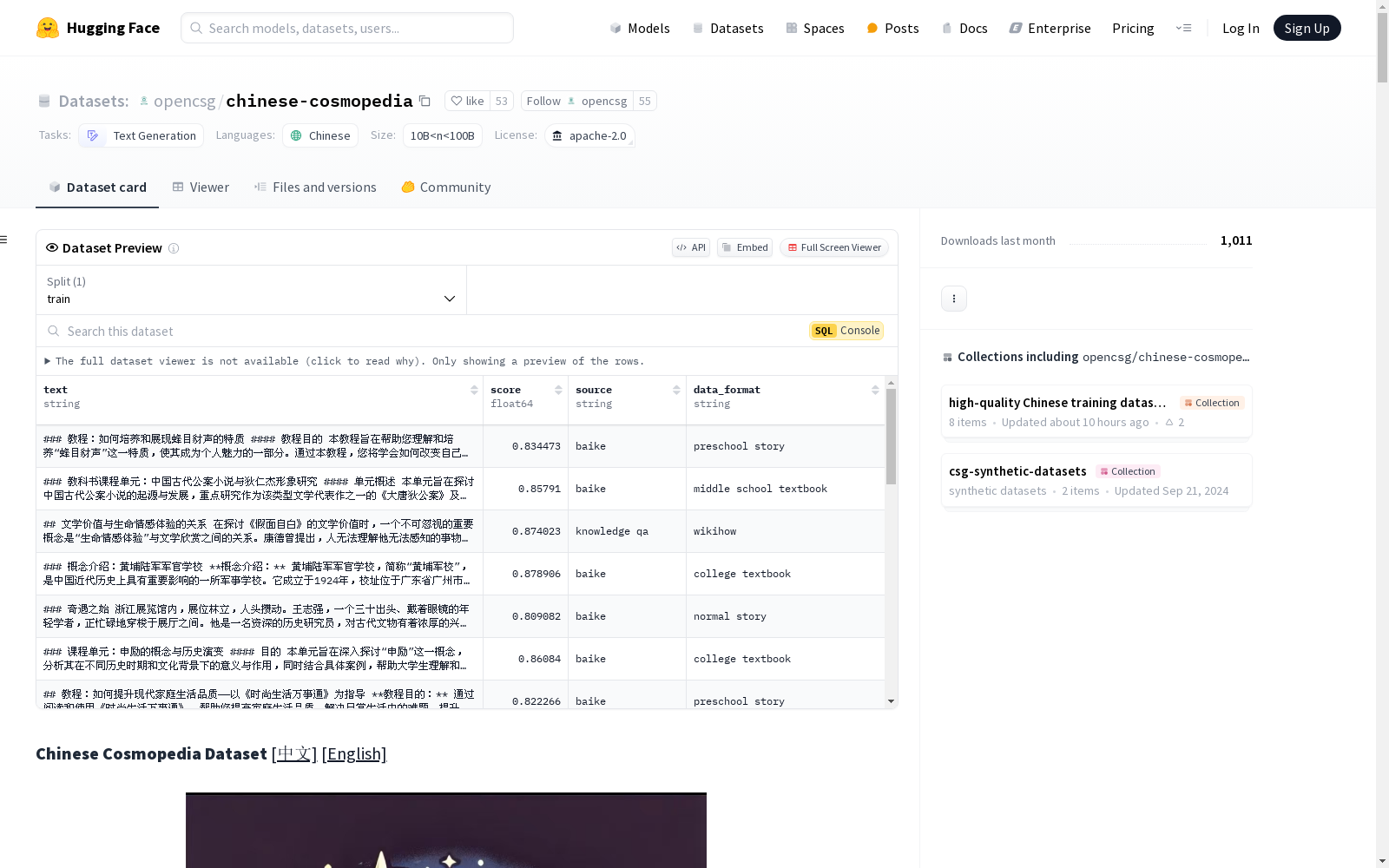
资源简介:
Chinese Cosmopedia数据集共包含1500万条数据,约60B个token,构建合成数据集的两个核心要素是种子数据和prompt。种子数据决定了生成内容的主题,prompt则决定了数据的风格(如教科书、故事、教程或幼儿读物)。数据来源丰富多样,涵盖了中文维基百科、百度百科、知乎问答和技术博客等平台,确保内容的广泛性和权威性。生成的数据形式多样,涵盖大学教科书、中学教科书、幼儿故事、普通故事和WikiHow风格教程等多种不同风格。通过对每条种子数据生成多种不同风格的内容,数据集不仅适用于学术研究,还广泛应用于教育、娱乐和技术领域。
The Chinese Cosmopedia dataset consists of 15 million data entries and approximately 60 billion tokens. The two core elements for constructing this synthetic dataset are seed data and prompts. Seed data dictates the theme of the generated content, while prompts determine the style of the data, such as textbooks, stories, tutorials, or children’s reading materials. The dataset draws from a wide range of sources, including Chinese Wikipedia, Baidu Encyclopedia, Zhihu Q&A, technical blogs and other platforms, ensuring the breadth and authority of its content. The generated data exhibits diverse styles, covering university textbooks, high school textbooks, children’s stories, general stories, and WikiHow-style tutorials, among others. By generating multiple distinct styles of content for each seed data entry, this dataset is not only applicable to academic research but also widely used in education, entertainment and technical domains.
创建时间:
2024-09-16
原始信息汇总
Chinese Cosmopedia 数据集介绍
概述
- 语言: 中文
- 任务类别: 文本生成
- 许可证: Apache 2.0
- 数据规模: 10B<n<100B tokens
- 数据条目: 1500万条
数据来源与种类
- 中文维基百科: 提供大量精确、权威的知识性文章。
- 百度百科: 提供广泛的中文知识资源。
- 知乎问答: 涵盖多个领域的讨论与见解。
- 技术博客: 涵盖从编程到人工智能等多个技术方向的深入讨论。
数据形式与风格
- 大学教科书: 结构严谨,深入探讨各类大学学科的核心概念。
- 中学教科书: 适合中学生的教学内容,简洁易懂。
- 幼儿故事: 面向5岁儿童,语言简洁易懂。
- 普通故事: 通过引人入胜的情节和人物对话,展开对某一概念的生动描述。
- WikiHow风格教程: 详细的步骤指导,帮助用户完成特定任务。
统计
- 种子数据来源:
- blog: 2,111,009
- baike: 10,939,121
- wiki: 173,671
- knowledge QA: 2,291,547
- 数据形式:
- preschool story: 1,637,760
- normal story: 3,332,288
- middle school textbook: 4,677,397
- college textbook: 3,127,902
- wikihow: 2,740,001
数据生成与模型
- 生成模型: OpenCSG-Wukong-Enterprise-Long
- 生成过程: 通过设计专门的prompt,确保数据生成的风格与内容准确匹配。
许可协议
- 使用许可: 遵循OpenCSG社区许可证和Apache 2.0许可证。
- 商业用途: 需发送邮件至lorraineg@opencsg.com并获得许可。
搜集汇总
数据集介绍
构建方式
Chinese Cosmopedia数据集的构建基于种子数据和提示词(prompt)的双重机制。种子数据决定了生成内容的主题,涵盖了中文维基百科、百度百科、知识问答和技术博客等多种权威来源,确保了数据的广泛性和权威性。提示词则用于定义生成内容的风格,如教科书、故事、教程等。通过OpenCSG团队开发的OpenCSG-Wukong-Enterprise-Long模型,结合精心设计的提示词,生成了多样化的文本形式,包括大学教科书、中学教科书、幼儿故事、普通故事和WikiHow风格教程等。这种构建方式不仅确保了数据的多样性和深度,还使其适用于多个应用场景。
特点
Chinese Cosmopedia数据集的特点在于其多样化的文本风格和广泛的知识覆盖。数据集包含1500万条数据,约60B个token,涵盖了从学术到日常应用的多种文本类型。大学教科书和中学教科书内容严谨,适合学术研究;幼儿故事和普通故事语言生动,适合教育和娱乐领域;WikiHow风格教程则提供了详细的步骤指导,适用于技术应用。此外,数据集通过多种提示词生成不同风格的内容,确保了数据的丰富性和灵活性,使其能够满足不同领域的需求。
使用方法
Chinese Cosmopedia数据集的使用方法灵活多样,适用于多种场景。用户可以通过加载数据集并调用相应的提示词,生成特定风格的文本内容。例如,使用大学教科书提示词生成学术性文本,或使用幼儿故事提示词生成适合儿童阅读的内容。数据集支持商业用途,但需遵循OpenCSG社区许可证和Apache 2.0许可证的条款。对于商业用途,用户需通过邮件联系OpenCSG团队并获得许可。此外,数据集的开源发布将进一步促进其在学术研究、教育和技术领域的广泛应用。
背景与挑战
背景概述
Chinese Cosmopedia数据集由OpenCSG团队开发,旨在为中文文本生成领域提供丰富多样的语料资源。该数据集构建于2023年,包含约1500万条数据,总计60B个token,涵盖了从学术到日常应用的多种文本类型。数据来源包括中文维基百科、百度百科、知乎问答和技术博客等权威平台,确保了内容的广泛性和权威性。通过生成大学教科书、中学教科书、幼儿故事、普通故事和WikiHow风格教程等多种风格的内容,该数据集不仅为自然语言处理研究提供了重要支持,还在教育、娱乐和技术领域展现了广泛的应用潜力。
当前挑战
Chinese Cosmopedia数据集在构建过程中面临多重挑战。首先,文本生成的质量控制是关键问题,如何在保持内容连贯性的同时确保生成文本的多样性和准确性,是数据集构建的核心挑战之一。其次,数据来源的多样性和权威性要求团队在数据筛选和预处理阶段投入大量精力,以确保生成内容的可靠性和实用性。此外,不同文本类型的风格适配也是一个技术难点,如何通过prompt设计精确引导模型生成符合特定风格的内容,需要深入的语言模型调优和实验验证。最后,数据集的规模庞大,如何在保证数据质量的同时高效处理和管理海量数据,也是团队面临的重要挑战。
常用场景
经典使用场景
Chinese Cosmopedia数据集在自然语言处理领域中被广泛用于文本生成任务,尤其是中文文本的生成。其多样化的数据格式和风格使其成为训练和评估生成模型的理想选择。研究人员可以利用该数据集生成从学术教科书到儿童故事的各种文本,从而测试模型在不同语境下的表现。
实际应用
在实际应用中,Chinese Cosmopedia数据集被广泛用于教育、娱乐和技术领域。例如,教育机构可以利用该数据集生成适合不同年龄段学生的教材,而娱乐公司则可以基于数据集生成故事或剧本。技术公司则可以利用该数据集优化其自然语言处理系统,提升用户体验。
衍生相关工作
基于Chinese Cosmopedia数据集,许多经典的自然语言处理研究工作得以展开。例如,研究人员开发了多种生成模型,能够根据特定提示生成高质量的学术文本或故事。此外,该数据集还推动了中文语言模型的预训练和微调技术的发展,为中文自然语言处理领域的进步提供了重要支持。
以上内容由遇见数据集搜集并总结生成


