chinese_moegirl_wiki_corpus_raw
收藏Hugging Face2024-08-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/mrzjy/chinese_moegirl_wiki_corpus_raw
下载链接
链接失效反馈官方服务:
资源简介:
本数据集是中文二次元wiki网站Moegirl于2023年8月14日的wiki数据转储,经过格式转换和初步处理,包括添加标签和过滤重定向条目。数据为原始文本格式,适用于LLM预训练,需进一步处理。
创建时间:
2024-08-13
原始信息汇总
Chinese Moegirl ACG Corpus (Raw Data)
概述
- 数据集名称: Chinese Moegirl ACG Corpus (Raw Data)
- 许可协议: CC BY 4.0
- 任务类别: 文本生成
- 语言: 中文
- 标签: 动漫、ACG、游戏、维基、萌娘
- 数据规模: 100K<n<1M
数据来源
- 来源网站: Moegirl
- 数据版本: 20230814 wiki dump for wiki-zh.moegirl.org.cn
数据处理
- 格式转换: 从XML格式转换为JSONL格式
- 数据清洗:
- 使用正则表达式提取标签
- 过滤掉所有带有 "#REDIRECT" 内容的重定向条目
使用建议
- 后续处理: 作为LLM预训练语料时,务必进行进一步的文本清洗
搜集汇总
数据集介绍
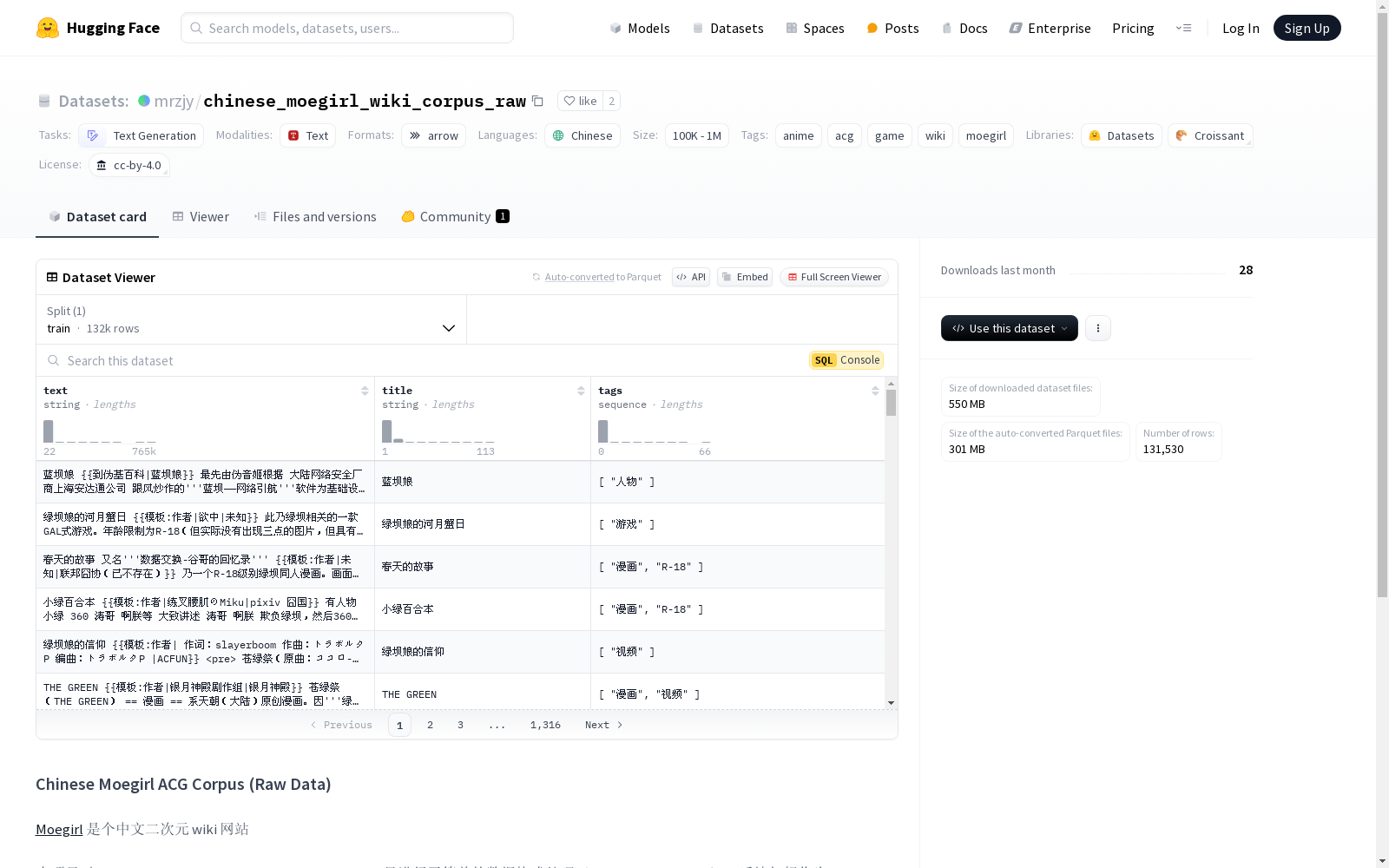
构建方式
该数据集基于2023年8月14日的中文二次元Wiki网站Moegirl的dump文件构建,原始数据为XML格式,经过简单的格式转换处理,转化为JSONL格式。在数据处理过程中,使用正则表达式为每条数据添加了标签,并过滤了所有包含“#REDIRECT”的重定向条目。这一过程确保了数据的初步结构化,为后续的文本清洗和模型预训练提供了基础。
使用方法
该数据集主要用于文本生成任务,尤其是与中文二次元文化相关的语言模型预训练。用户在使用时,应首先对数据进行清洗,去除冗余信息和不相关条目。清洗后的数据可直接用于模型的训练和微调。此外,由于数据集包含丰富的标签信息,用户还可以利用这些标签进行特定主题的文本生成或分类任务。数据集以JSONL格式提供,便于逐行读取和处理,适合大规模数据处理的场景。
背景与挑战
背景概述
Chinese Moegirl ACG Corpus (Raw Data) 数据集源于中文二次元文化社区Moegirl,该网站是一个专注于动漫、游戏及相关亚文化内容的维基平台。数据集创建于2023年,基于20230814的Moegirl维基数据转储,经过简单的格式转换处理,从XML格式转化为JSONL格式。该数据集的核心研究问题在于为中文自然语言处理任务,特别是文本生成任务,提供丰富的二次元文化语料。其影响力主要体现在为中文大语言模型(LLM)的预训练提供了独特的领域数据支持,填补了中文ACG领域语料的空白。
当前挑战
该数据集面临的挑战主要集中在两个方面。首先,作为原始数据集,其文本内容尚未经过深度清洗,包含大量冗余信息、非结构化文本以及重定向条目,这为后续的模型训练带来了数据质量上的挑战。其次,由于ACG领域的特殊性,文本中充斥着大量专有名词、俚语及非标准表达,这对自然语言处理模型的语义理解和生成能力提出了更高的要求。此外,数据集的构建过程中,如何有效提取和标注标签信息,同时避免信息丢失,也是需要解决的技术难题。
常用场景
经典使用场景
在自然语言处理领域,chinese_moegirl_wiki_corpus_raw数据集常用于文本生成任务,尤其是针对中文二次元文化内容的生成。该数据集提供了丰富的ACG(动画、漫画、游戏)相关文本,能够为模型提供多样化的训练素材,帮助生成符合二次元文化语境的自然语言文本。
解决学术问题
该数据集解决了在中文二次元文化领域缺乏高质量、大规模文本数据的问题,为研究者提供了宝贵的资源。通过该数据集,研究者可以深入探讨中文ACG文本的语言特征、文化表达以及生成模型的优化方法,推动了中文自然语言处理在特定文化领域的应用与发展。
实际应用
在实际应用中,chinese_moegirl_wiki_corpus_raw数据集可用于开发智能对话系统、内容推荐引擎以及二次元文化相关的文本生成工具。例如,基于该数据集训练的模型可以为ACG爱好者提供个性化的内容推荐,或生成符合二次元风格的对话内容,提升用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,特别是针对中文二次元文化的文本生成任务,chinese_moegirl_wiki_corpus_raw数据集提供了丰富的原始语料。该数据集源自知名的中文二次元wiki网站Moegirl,涵盖了动漫、游戏等ACG相关内容,为研究中文语境下的文本生成模型提供了独特的数据支持。近年来,随着大语言模型(LLM)的快速发展,如何有效利用此类非结构化数据进行预训练成为研究热点。研究者们正探索更精细的文本清洗方法,以提升数据质量,同时也在研究如何将二次元文化特有的语言风格融入模型训练,以生成更具文化特色的文本。该数据集的应用不仅推动了中文ACG领域文本生成技术的发展,也为跨文化语境下的自然语言处理研究提供了新的视角。
以上内容由遇见数据集搜集并总结生成


