drt/kqa_pro|知识库问答数据集|推理能力数据集
收藏hugging_face2022-10-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/drt/kqa_pro
下载链接
链接失效反馈资源简介:
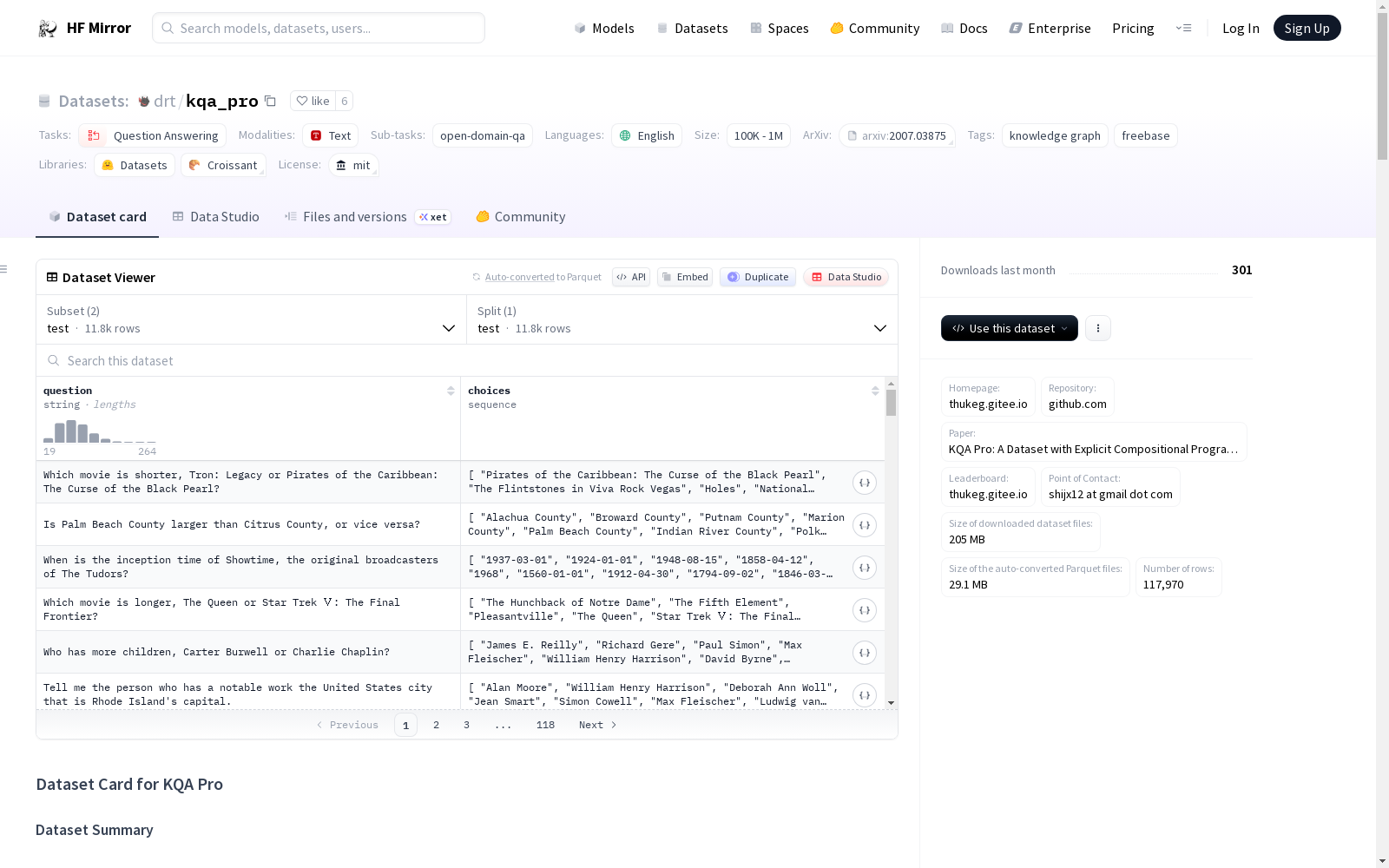
KQA Pro是一个大规模的知识库复杂问答数据集,问题多样且具有挑战性,需要多种推理能力,包括组合推理、多跳推理、定量比较、集合操作等。每个问题都提供了SPARQL和程序的强监督。数据集支持基于知识图谱的问答任务,并提供了SPARQL和程序。数据集的语言为英语,结构包括训练集、验证集和测试集,格式为JSON。此外,数据集还提供了知识图谱文件的格式、如何运行SPARQL和程序、如何提交测试集结果、许可证信息、引用信息和贡献者信息。
提供机构:
drt
原始信息汇总
数据集概述
数据集名称
- 名称: KQA-Pro
数据集特征
- 语言: 英语
- 许可证: MIT
- 多语言性: 单语
- 大小: 10K<n<100K
- 源数据集: 原始
- 标签: 知识图谱, Freebase
- 任务类别: 问答
- 任务ID: open-domain-qa
注释创建者
- 机器生成
- 专家生成
数据集描述
数据集总结
- 描述: KQA Pro是一个大规模的知识库复杂问答数据集,包含多样且具有挑战性的问题,需要多种推理能力,如组合推理、多跳推理、定量比较、集合操作等。每个问题都提供了SPARQL和程序的强监督。
支持的任务和排行榜
- 支持任务: 知识图谱基础的问答
- 特点: 为每个问题提供SPARQL和程序
数据集结构
数据配置
- 配置:
train_val和test
数据分割
- 分割: 训练集, 验证集, 测试集
数据文件格式
- 训练集/验证集: 包含问题、SPARQL、程序、选项和答案
- 测试集: 包含问题和选项
附加信息
知识图谱文件
- 文件:
kb.json - 格式: 包含概念、实体及其属性和关系
如何运行SPARQL和程序
- 实现: 在代码库中实现,包括SPARQL解析器和程序解析器
如何提交测试集结果
- 提交方式: 通过电子邮件发送预测答案文件,并提供模型信息
许可证信息
- 许可证: MIT License
引用信息
- 引用格式:
@inproceedings{KQAPro, title={{KQA P}ro: A Large Diagnostic Dataset for Complex Question Answering over Knowledge Base}, author={Cao, Shulin and Shi, Jiaxin and Pan, Liangming and Nie, Lunyiu and Xiang, Yutong and Hou, Lei and Li, Juanzi and He, Bin and Zhang, Hanwang}, booktitle={ACL22}, year={2022} }
AI搜集汇总
数据集介绍
构建方式
在知识图谱问答领域,KQA Pro数据集的构建体现了对复杂推理问题的系统性探索。该数据集以Freebase知识库为基础,通过机器生成与专家标注相结合的方式,精心设计了涵盖组合推理、多跳推理、定量比较及集合操作等多种复杂能力的问句。每个问题均配备了可执行的SPARQL查询语句和结构化程序表示,这些强监督信号为模型提供了清晰的推理路径指引,确保了数据在逻辑层面的严谨性与可解释性。
特点
KQA Pro数据集的核心特征在于其问题的高度多样性与挑战性,旨在全面诊断模型在复杂知识推理上的能力。数据集不仅提供了丰富的答案选项,更以结构化的程序序列和标准化的SPARQL查询作为监督信息,实现了对推理过程的可分解与可验证。其知识图谱文件详细定义了实体、概念、属性及关系,并包含修饰词等细粒度信息,为深度语义理解与复杂计算提供了坚实的数据基础。
使用方法
使用该数据集时,研究者可通过Hugging Face平台指定`train_val`或`test`配置进行加载,分别获取包含完整监督信息的训练验证集与仅含问题和选项的测试集。对于模型开发,可利用官方代码库中的SPARQL解析器与程序执行器,基于提供的知识图谱运行预测的逻辑形式以获取答案。测试集评估需将预测答案按序提交至指定邮箱,并附上模型细节以参与官方排行榜,这为衡量模型在复杂知识问答上的性能提供了标准化平台。
背景与挑战
背景概述
在知识图谱问答领域,复杂问题的解析与推理一直是核心研究难题。KQA Pro数据集由清华大学研究团队于2022年创建,旨在通过提供大规模、结构化的复杂问答数据,推动知识库问答系统的深度发展。该数据集以Freebase知识图谱为基础,涵盖了组合推理、多跳推理、定量比较及集合操作等多种复杂推理能力,为模型诊断与性能评估提供了标准化基准。其创新之处在于为每个问题同时标注了可执行的SPARQL查询与程序化表示,显著提升了模型的可解释性与泛化能力,对自然语言处理与知识图谱交叉领域的研究产生了深远影响。
当前挑战
KQA Pro数据集致力于解决复杂知识库问答中的多维度挑战,其核心在于处理需要组合性、多跳及量化比较的复杂自然语言问题。构建过程中的主要挑战包括:如何从大规模知识图谱中精准提取并标注多样化的复杂问题,确保问题覆盖广泛的推理类型;设计兼顾机器可执行性与人类可读性的SPARQL和程序化标注方案,以提供强监督信号;以及保持知识图谱实体、属性与关系的语义一致性,避免标注噪声。这些挑战共同指向了知识推理的深度与广度之间的平衡,为后续研究设立了高标准。
常用场景
经典使用场景
在知识图谱推理领域,KQA Pro数据集为复杂问答任务提供了标准化的评估基准。其核心应用场景在于训练和测试模型对多样化推理能力的掌握,例如组合推理、多跳推理、定量比较及集合操作等。通过提供精确的SPARQL查询和程序化监督,该数据集使研究者能够系统性地探索模型在结构化知识上的逻辑演绎性能,从而推动知识驱动问答系统的前沿发展。
解决学术问题
KQA Pro数据集主要针对知识库复杂问答中的关键学术挑战,如模型对隐含逻辑关系的理解与执行能力不足问题。它通过提供大规模、高质量的程序化标注,解决了传统数据集在推理深度和多样性上的局限,促进了可解释性推理模型的设计与优化。这一贡献显著提升了领域内对多步骤、组合式问答任务的评估精度,为知识推理研究奠定了坚实的实证基础。
衍生相关工作
基于KQA Pro数据集,已衍生出一系列经典研究工作,包括改进的SPARQL解析器、神经程序归纳模型以及端到端的知识图谱问答框架。这些工作不仅拓展了数据集的基线方法,还催生了新型推理架构,如结合预训练语言模型与符号推理的混合系统,进一步推动了知识推理与自然语言处理的交叉融合,为后续研究提供了丰富的技术借鉴与创新灵感。
以上内容由AI搜集并总结生成


