STI-Bench
收藏Hugging Face2025-04-19 更新2025-04-20 收录
下载链接:
https://huggingface.co/datasets/MINT-SJTU/STI-Bench
下载链接
链接失效反馈官方服务:
资源简介:
STI-Bench是一个空间时间智能基准数据集,通过现实世界视频数据评估多模态大型语言模型对空间时间概念的理解能力,包含2000多个问题答案对,跨越300个视频,涵盖多种空间时间任务。
STI-Bench is a spatio-temporal intelligence benchmark dataset that evaluates the capability of multimodal large language models to comprehend spatio-temporal concepts using real-world video data. It comprises over 2,000 question-answer pairs across 300 videos, covering diverse spatio-temporal tasks.
创建时间:
2025-04-07
原始信息汇总
Spatial-Temporal Intelligence Benchmark (STI-Bench) 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 视觉问答 (Visual Question Answering)
- 语言: 英语 (en)
- 标签: 视频、文本、机器人学、自动驾驶
- 规模: 1K < n < 10K
数据集描述
STI-Bench 旨在评估多模态大语言模型 (MLLMs) 通过真实世界视频数据理解时空概念的能力。数据集包含:
- 问题-答案对: 超过 2,000 对
- 视频数量: 300 个
- 视频来源: Omni6DPose、ScanNet、Waymo 等数据集
- 场景: 桌面设置、室内场景、室外场景
任务类型
| 任务名称 | 描述 |
|---|---|
| 3D 视频定位 | 定位视频中物体的 3D 边界框 |
| 自我中心方向 | 估计相机的旋转角度 |
| 姿态估计 | 确定相机姿态 |
| 尺寸测量 | 测量物体的长度 |
| 位移与路径长度 | 估计物体或相机移动的距离 |
| 速度与加速度 | 预测移动物体或相机的速度和加速度 |
| 空间关系 | 识别物体的相对位置 |
| 轨迹描述 | 总结移动物体或相机的轨迹 |
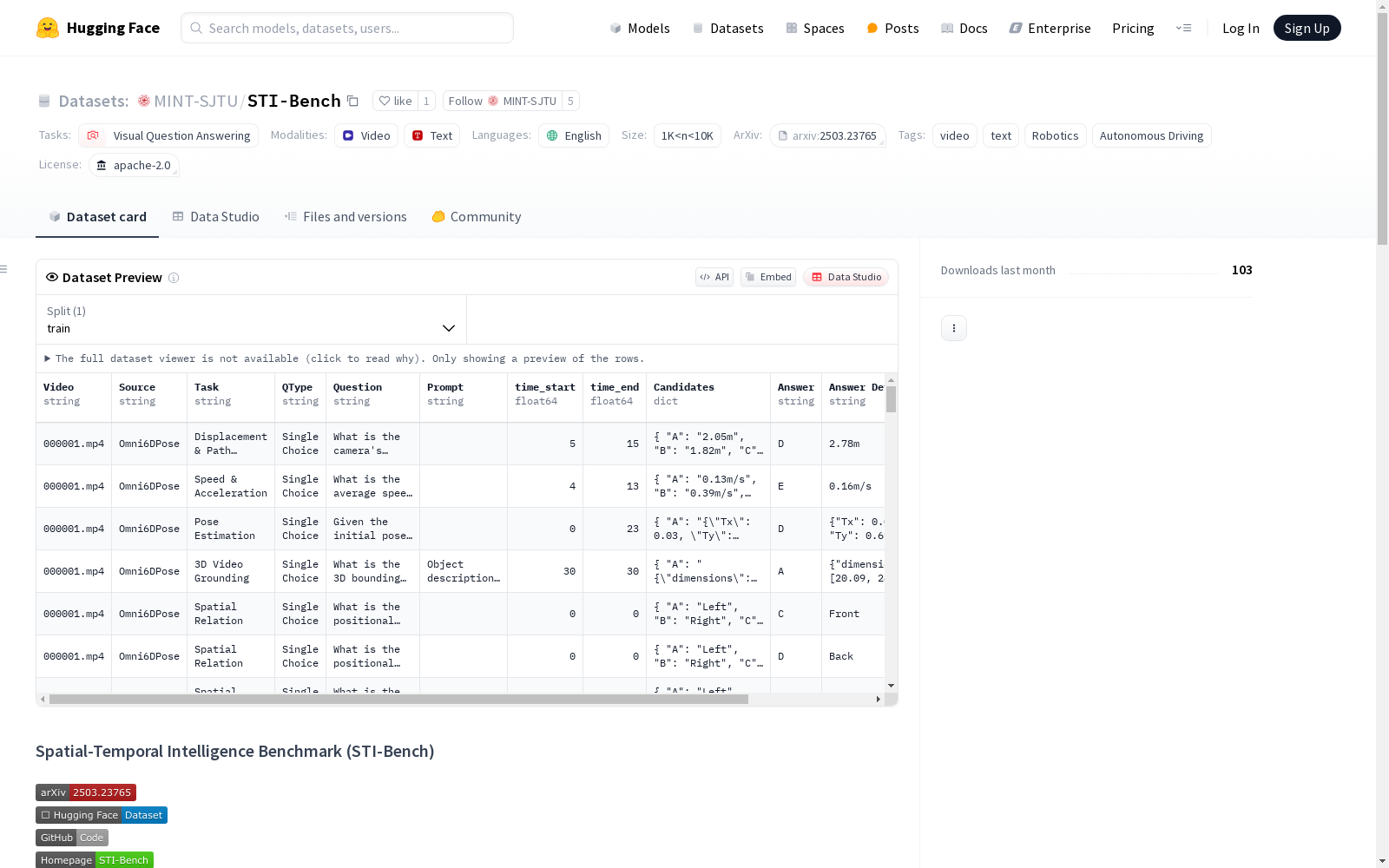
数据集字段说明
| 字段名称 | 描述 |
|---|---|
| Video | 视频文件对应的字符串 |
| Source | 视频来源,如 "ScanNet"、"Waymo" 或 "Omni6DPose" |
| Task | 任务类型字符串 |
| QType | 问题类型,通常为多选题 |
| Question | 向模型提出的问题 |
| Prompt | 回答问题的附加信息 |
| time_start | 问题在视频中的开始时间(秒) |
| time_end | 问题在视频中的结束时间(秒) |
| Candidates | 答案选项字典,格式为 {"A": "value", "B": "value", ...} |
| Answer | 正确答案对应的选项标签(如 "A"、"B") |
| Answer Detail | 正确答案的精确值或描述 |
| ID | 视频中问题的唯一序列 ID |
| Scene | 视频场景类型,如 "indoor"、"outdoor" 或 "desktop" |
评估方法
- 指标: 准确率(基于多选题的精确匹配)
- 评估代码: 提供在 GitHub 仓库
引用
bibtex @article{li2025sti, title={STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?}, author={Yun Li and Yiming Zhang and Tao Lin and XiangRui Liu and Wenxiao Cai and Zheng Liu and Bo Zhao}, year={2025}, journal={arXiv preprint arXiv:2503.23765}, }
搜集汇总
数据集介绍
构建方式
STI-Bench数据集通过整合来自Omni6DPose、ScanNet和Waymo等真实环境的多源视频数据,构建了一个包含300个视频片段和2000余个问答对的评测基准。研究团队采用严谨的标注流程,针对8类空间-时间理解任务设计了细粒度的问答模板,每个样本均包含精确的时间戳标注、多模态问题描述及结构化答案选项,确保评测任务的多样性和科学性。视频场景覆盖桌面环境、室内场景和户外驾驶等多种复杂情境,为评估多模态大模型的时空理解能力提供了全面而可靠的测试平台。
特点
该数据集的核心特点在于其系统性地设计了涵盖静态与动态场景的8类时空理解任务,包括3D视频定位、自我中心定向、姿态估计等前沿评测维度。每个样本不仅包含传统视觉问答中的多模态输入,还创新性地引入了精确时间标注、物理量测量和运动轨迹描述等科学评测要素。数据集采用严格的标准化处理,所有视频均源自真实世界数据集并经过专业标注,问题类型以多选题为主并附有详细解析,为模型能力评估提供了可解释的量化指标。
使用方法
使用者可通过Hugging Face数据集库直接加载STI-Bench,或通过Git LFS克隆完整数据集。典型使用流程包括:加载视频与对应标注数据后,将多模态输入馈入待测模型,根据模型输出的选择答案与标准答案比对计算准确率。评估脚本已开源提供标准化的评测流程,支持研究者针对特定任务子集进行细粒度分析。对于模型开发者,建议重点关注时空推理、物理量估算等子任务的性能表现,并通过Answer Detail字段进行错误归因分析以指导模型改进。
背景与挑战
背景概述
STI-Bench数据集由上海交通大学MIRA实验室于2025年提出,旨在评估多模态大语言模型(MLLMs)在真实世界视频数据中对时空概念的精确理解能力。该数据集基于Omni6DPose、ScanNet和Waymo等知名数据集构建,包含300个视频及2000余个问答对,覆盖桌面环境、室内场景和户外场景等多种真实场景。其核心研究问题聚焦于模型在静态与动态时空任务中的表现,如三维视频定位、自我中心定向、姿态估计等。STI-Bench的提出为多模态智能体在自动驾驶、机器人等领域的时空理解能力提供了标准化评估工具,推动了相关领域的研究进展。
当前挑战
STI-Bench数据集面临的挑战主要体现在两个方面:领域问题方面,时空理解任务要求模型具备精确的几何推理能力和动态场景解析能力,而现有MLLMs在细粒度时空属性(如速度估计、三维定位)的建模上仍存在显著差距;数据构建方面,视频标注需融合计算机视觉与几何知识,对物体位移、相机位姿等专业属性的标注成本极高,且需保证多源数据(ScanNet/Waymo/Omni6DPose)在时空维度上的标注一致性。此外,动态场景下的问答对设计需平衡问题复杂性与答案确定性,这对基准的可靠性提出了严峻考验。
常用场景
经典使用场景
STI-Bench作为空间-时间智能评估基准,其经典使用场景聚焦于测试多模态大语言模型(MLLMs)对真实世界视频数据的时空理解能力。通过涵盖桌面环境、室内场景及户外情境的300余段视频与2000多组问答对,该数据集为模型在3D视频定位、自我中心定向、姿态估计等八项核心任务上的表现提供了标准化评估框架。研究者可利用其丰富的时空推理任务,系统性验证模型对物体位移、速度变化、空间关系等动态场景要素的认知精度。
衍生相关工作
基于STI-Bench的评估范式,学界已衍生出多类创新研究。部分工作扩展了其时空问答框架至医疗影像分析领域,另一些研究则借鉴其动态评估指标开发了增强现实中的实时物体追踪算法。数据集团队后续提出的Omni6DPose-VQA进一步细化了六自由度姿态估计任务,而受其启发的ST-VQA基准则将时空推理与常识知识问答相结合,推动了多模态推理模型的认知边界。
数据集最近研究
最新研究方向
在自动驾驶与机器人领域,空间-时间智能的理解已成为多模态大语言模型(MLLMs)研究的关键挑战。STI-Bench作为一项创新的基准测试,专注于评估模型在真实世界视频数据中对物体外观、姿态、位移及运动的精确理解能力。当前研究热点集中在如何提升模型在3D视频定位、自我中心定向及轨迹描述等任务中的表现,这些任务直接关联到自动驾驶系统的环境感知与决策能力。随着Waymo、ScanNet等数据源的引入,STI-Bench为学术界和工业界提供了一个标准化评估框架,推动了空间-时间智能在复杂场景下的应用边界。该数据集的发布不仅填补了多模态模型在动态时空理解上的评估空白,也为未来智能系统的可靠性和安全性研究奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


