ner-cat
收藏Hugging Face2025-03-18 更新2025-03-19 收录
下载链接:
https://huggingface.co/datasets/Ugiat/ner-cat
下载链接
链接失效反馈官方服务:
资源简介:
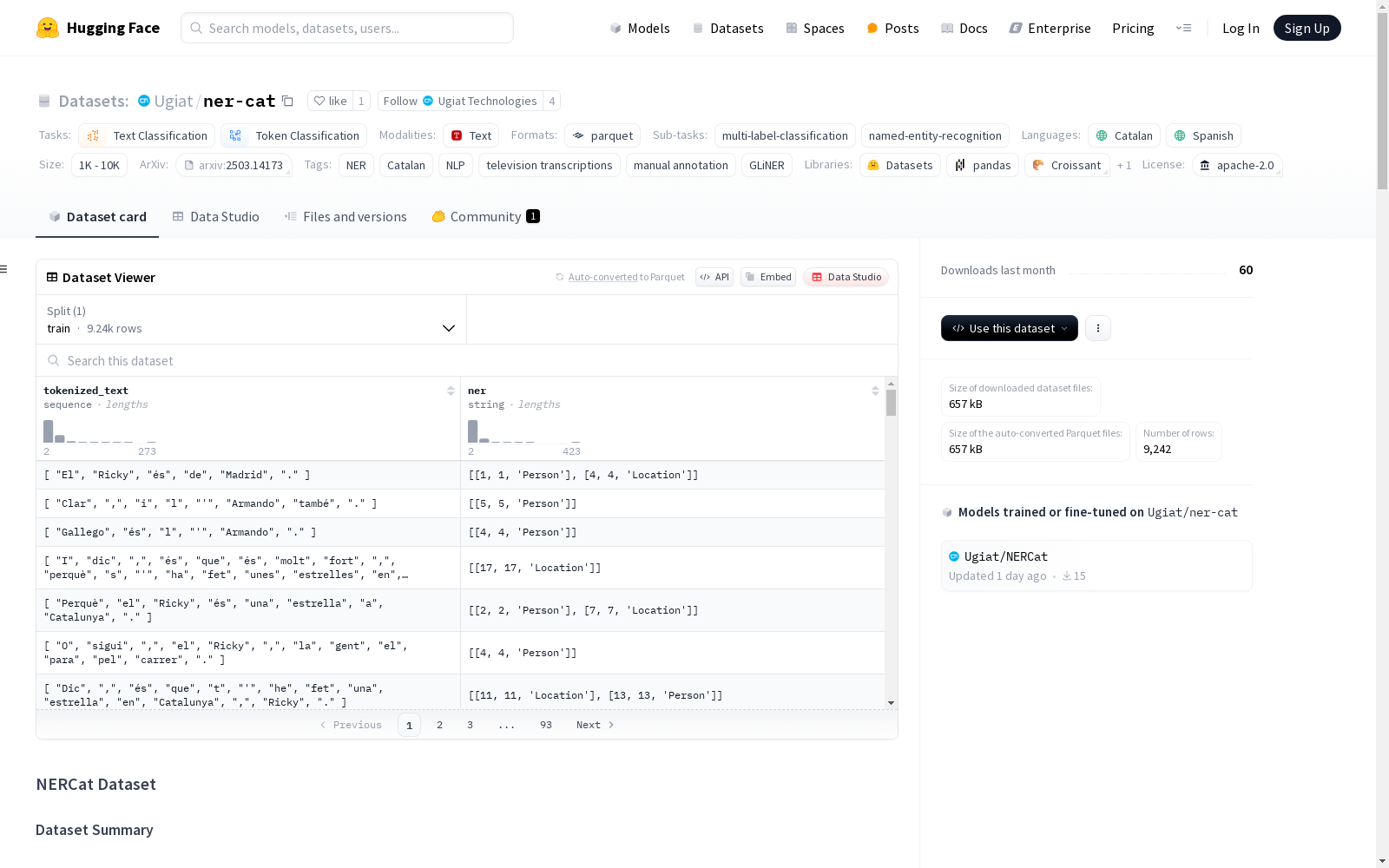
NERCat数据集是一个手动的加泰罗尼亚语电视节目转录注释集合,用于提高加泰罗尼亚语的命名实体识别性能。包含9242个句子和13,732个命名实体注释,涵盖个人、设施、组织、地点、产品、事件、日期和法律等八个类别。
The NERCat dataset is a manually annotated collection of Catalan-language television program transcripts, developed to improve the performance of named entity recognition (NER) for the Catalan language. It contains 9,242 sentences and 13,732 named entity annotations, covering eight categories including individuals, facilities, organizations, locations, products, events, dates, and legal entities.
创建时间:
2025-03-13
搜集汇总
数据集介绍
构建方式
NERCat数据集是一个专门针对加泰罗尼亚语的手动标注电视转录文本集合,旨在提升加泰罗尼亚语的命名实体识别(NER)性能。该数据集涵盖了政治、体育和文化等多个领域,包含9,242个句子和13,732个命名实体,标注了八个类别:人物、设施、组织、地点、产品、事件、日期和法律。数据集的构建过程包括数据收集和标注,均由专家手动完成,确保了数据的高质量和准确性。
特点
NERCat数据集的主要特点在于其多领域覆盖和高质量的手动标注。数据集不仅包含了丰富的加泰罗尼亚语文本,还偶尔夹杂西班牙语的代码切换片段。标注的命名实体类别广泛,涵盖了从人物到法律等多个领域,尤其适合用于低资源语言的NLP应用开发。此外,数据集的格式与GLiNER框架兼容,便于直接用于训练和推理任务。
使用方法
NERCat数据集主要用于加泰罗尼亚语的命名实体识别任务。用户可以通过加载数据集的JSON格式实例,直接使用GLiNER框架进行模型训练和评估。每个实例包含分词后的文本和对应的命名实体标注,标注格式为实体在文本中的位置索引和类别标签。对于不包含命名实体的句子,数据集也提供了完整的标签列表,以确保数据的一致性。通过该数据集,用户可以显著提升加泰罗尼亚语NER模型的性能,尤其是在人物、组织和地点等类别上表现尤为突出。
背景与挑战
背景概述
NERCat数据集是一个专门针对加泰罗尼亚语的手动标注电视转录文本集合,旨在提升加泰罗尼亚语的命名实体识别(NER)性能。该数据集由Guillem Cadevall Ferreres等研究人员于2025年创建,涵盖了政治、体育、文化等多个领域,包含9,242个句子和13,732个标注实体,分为八个类别:人物、设施、组织、地点、产品、事件、日期和法律。加泰罗尼亚语作为一种低资源语言,长期以来缺乏高质量的标注数据,NERCat的推出填补了这一空白,为加泰罗尼亚语的自然语言处理(NLP)应用提供了重要支持,尤其在媒体、治理和文化领域具有深远影响。
当前挑战
NERCat数据集面临的挑战主要体现在两个方面。首先,加泰罗尼亚语作为一种低资源语言,其语言数据的稀缺性和多样性不足,导致模型训练时难以捕捉到足够的语言特征。其次,数据集的构建过程中,手动标注的复杂性较高,尤其是在处理多领域文本时,标注者需要具备丰富的领域知识以确保标注的准确性和一致性。此外,数据集中部分实体类别(如设施、产品和法律)的样本数量较少,可能导致模型在这些类别上的表现不佳。这些挑战不仅影响了数据集的构建效率,也对后续模型的训练和优化提出了更高的要求。
常用场景
经典使用场景
NERCat数据集主要用于加泰罗尼亚语的命名实体识别(NER)任务。该数据集涵盖了政治、体育、文化等多个领域,包含9242个句子和13732个命名实体,标注了人物、设施、组织、地点、产品、事件、日期和法律等八个类别。通过手动标注的电视转录文本,NERCat为加泰罗尼亚语这一低资源语言提供了高质量的标注数据,显著提升了NER模型在该语言上的表现。
实际应用
NERCat数据集的实际应用场景广泛,特别是在加泰罗尼亚语媒体和政府领域。通过训练基于该数据集的NER模型,可以自动识别新闻、法律文件和电视节目中的关键实体,如人名、地名和组织名,从而支持信息提取、内容分析和知识图谱构建等任务。此外,该数据集还可用于跨语言研究,探索加泰罗尼亚语与西班牙语之间的语言转换和实体识别差异。
衍生相关工作
NERCat数据集衍生了多项经典工作,其中最突出的是基于GLiNER框架的NERCat微调模型。该模型在加泰罗尼亚语NER任务中取得了接近完美的表现,特别是在人物、组织和地点类别上表现优异。此外,NERCat数据集还启发了跨语言NER研究,推动了低资源语言在自然语言处理领域的发展,并为其他低资源语言的标注数据构建提供了参考。
以上内容由遇见数据集搜集并总结生成


