fleurs
收藏Hugging Face2026-01-17 更新2026-01-18 收录
下载链接:
https://huggingface.co/datasets/mteb/fleurs
下载链接
链接失效反馈官方服务:
资源简介:
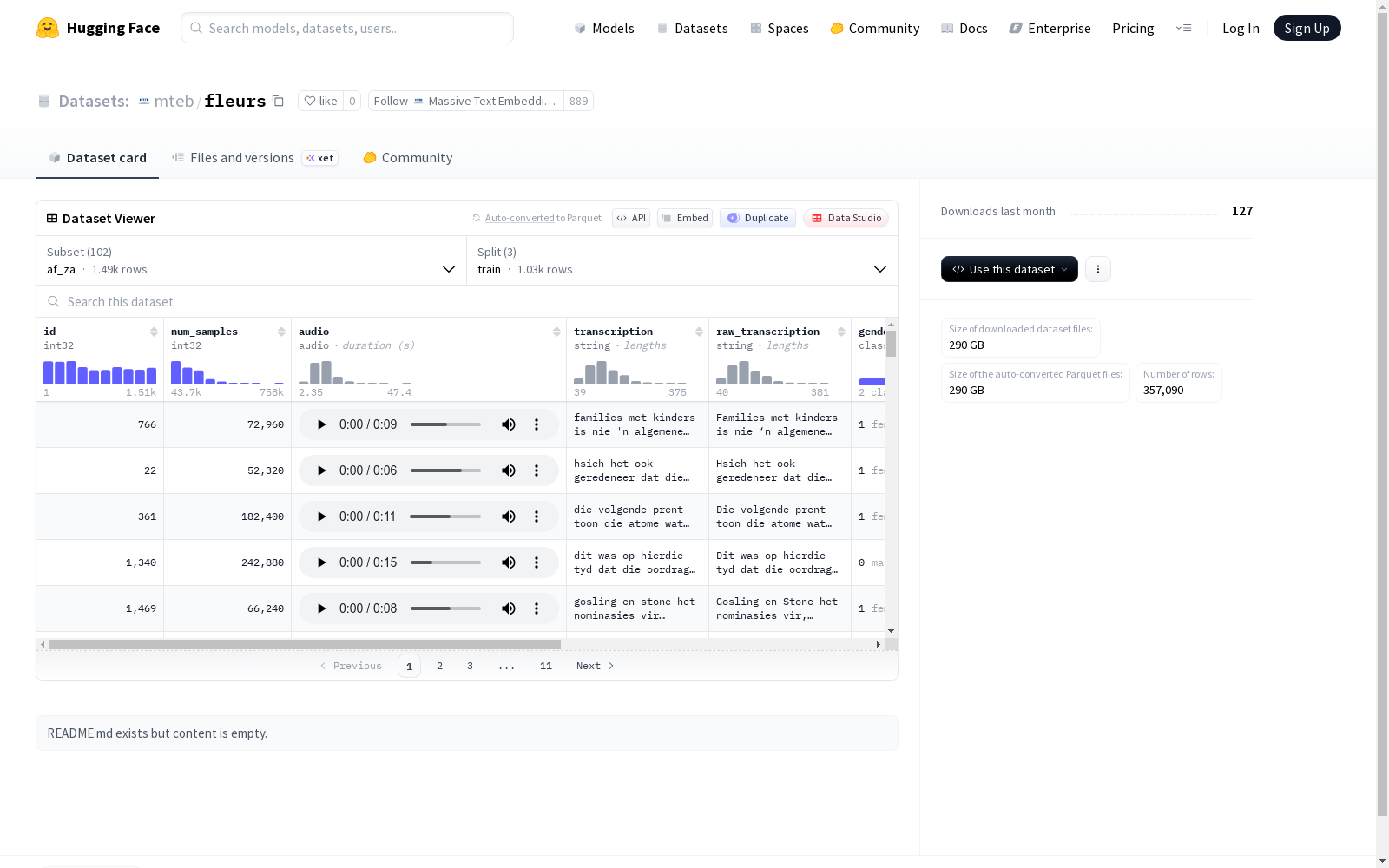
提供的README内容描述了一个多语言音频数据集,包含多个配置(af_za、am_et、ar_eg、as_in、ast_es、az_az)。每个配置包含采样率为16000 Hz的音频样本,以及转录文本、原始转录文本、性别信息、语言ID和语言组ID。数据集分为训练集、验证集和测试集,每个集都有指定的字节数和示例数。数据集支持多种语言和方言,分为西欧、东欧、中亚/中东/北非、撒哈拉以南非洲、南亚、东南亚和中日韩(CJK)等语言组。
The accompanying README describes a multilingual audio dataset encompassing multiple configurations (af_za, am_et, ar_eg, as_in, ast_es, az_az). Each configuration contains audio samples with a sampling rate of 16000 Hz, alongside transcription text, original transcription text, gender information, language ID, and language group ID. The dataset is partitioned into training, validation, and test splits, each with specified byte counts and quantities of examples. The dataset supports a wide range of languages and dialects, categorized into language groups including Western European, Eastern European, Central Asian/Middle Eastern/North African, Sub-Saharan African, South Asian, Southeast Asian, and Chinese-Japanese-Korean (CJK).
创建时间:
2026-01-17
原始信息汇总
FLEURS 数据集概述
数据集基本信息
- 数据集名称:FLEURS
- 托管地址:https://huggingface.co/datasets/mteb/fleurs
- 数据格式:多语言语音数据集,每个语言对应一个配置(config)
数据结构与特征
每个语言配置包含以下字段:
- id:整型标识符
- num_samples:整型样本数
- audio:音频数据,采样率为16000 Hz
- transcription:字符串类型转录文本
- raw_transcription:字符串类型原始转录文本
- gender:说话者性别标签(male、female、other)
- lang_id:语言标识符,涵盖103种语言变体
- language:字符串类型语言名称
- lang_group_id:语言组标识符,分为7个地理区域
语言覆盖范围
数据集支持103种语言变体,包括:
- 西欧语言(western_european_we)
- 东欧语言(eastern_european_ee)
- 中亚、中东、北非语言(central_asia_middle_north_african_cmn)
- 撒哈拉以南非洲语言(sub_saharan_african_ssa)
- 南亚语言(south_asian_sa)
- 东南亚语言(south_east_asian_sea)
- 中文、日语、韩语(chinese_japanase_korean_cjk)
数据划分
每个语言配置包含三个标准划分:
- 训练集(train)
- 验证集(validation)
- 测试集(test)
示例语言配置详情
南非荷兰语(af_za)
- 训练集:1,032个样本,839.64 MB
- 验证集:198个样本,147.30 MB
- 测试集:264个样本,207.28 MB
- 下载大小:1.17 GB
- 数据集大小:1.19 GB
阿姆哈拉语(am_et)
- 训练集:3,163个样本,2.56 GB
- 验证集:223个样本,150.57 MB
- 测试集:516个样本,371.84 MB
- 下载大小:3.05 GB
- 数据集大小:3.08 GB
阿拉伯语(ar_eg)
- 训练集:2,104个样本,1.39 GB
- 验证集:295个样本,201.61 MB
- 测试集:428个样本,300.09 MB
- 下载大小:1.88 GB
- 数据集大小:1.90 GB
阿萨姆语(as_in)
- 训练集:2,812个样本,2.47 GB
- 验证集:418个样本,324.75 MB
- 测试集:984个样本,800.24 MB
- 下载大小:3.57 GB
- 数据集大小:3.59 GB
阿斯图里亚斯语(ast_es)
- 训练集:2,511个样本,1.74 GB
- 验证集:398个样本,227.57 MB
- 测试集:946个样本,561.74 MB
- 下载大小:2.51 GB
- 数据集大小:2.53 GB
阿塞拜疆语(az_az)
- 特征结构:与其他配置一致,包含完整语言标签体系
技术规格
- 音频采样率:统一为16,000 Hz
- 数据格式:结构化数据集,支持批量加载和处理
- 标签体系:标准化的分类标签,确保跨语言一致性
搜集汇总
数据集介绍
构建方式
在语音识别与多语言技术蓬勃发展的背景下,FLEURS数据集通过系统化采集流程构建而成。该数据集源自涵盖102种语言变体的FLoRES翻译基准,由母语者朗读句子并录音,确保了语音样本的自然性与真实性。音频以16kHz采样率统一处理,每条录音均配有原始转录与标准化转录文本,并标注了说话者性别及语言分类信息。数据按语言配置划分,每种语言独立提供训练、验证与测试集,构建过程注重语言多样性与数据质量,为多语言语音研究提供了坚实基础。
特点
FLEURS数据集展现出卓越的多语言覆盖能力,囊括了从南非荷兰语到祖鲁语等102种语言及变体,并依据地理语言学划分为七大语言群组。其结构设计精良,每个语言配置均包含音频、转录文本、性别标签及语言标识等特征,音频采样率统一为16kHz以保证一致性。数据集规模庞大,不同语言的样本量虽有差异,但均遵循标准的数据分割原则,确保了评估的公平性与可复现性。这种广泛的代表性与精细的标注体系,使其成为评测跨语言语音模型的珍贵资源。
使用方法
针对多语言语音识别与合成的研究,使用者可通过HuggingFace数据集库直接加载FLEURS的特定语言配置。典型应用流程包括利用训练集进行模型参数学习,在验证集上进行超参数调优与早期停止,最终在预留的测试集上评估模型性能。数据集提供的标准化转录适用于训练端到端语音识别系统,而原始转录、性别及语言群组信息则支持说话人识别、语言检测等细粒度分析任务。其清晰的数据分割为模型开发与基准测试提供了可靠框架。
背景与挑战
背景概述
在语音识别与多语言技术蓬勃发展的时代背景下,FLEURS数据集应运而生,由Google Research团队于2022年推出。该数据集旨在应对全球语言多样性带来的技术挑战,其核心研究问题聚焦于为102种语言构建高质量、大规模、具有平行文本的语音识别基准。通过覆盖从高资源到低资源的广泛语种,FLEURS不仅推动了多语言语音识别模型的公平评估,也为语言技术向资源匮乏语言的扩展提供了关键基础设施,深刻影响了语音处理领域的全球化发展轨迹。
当前挑战
FLEURS数据集致力于解决多语言语音识别领域的关键挑战,即如何为众多语言,尤其是低资源语言,建立统一的评估基准。其构建过程面临多重困难:首先,数据收集需跨越不同地理与文化区域,确保语音样本的代表性与录音质量的一致性;其次,文本转录的准确性要求语言专家对多样化的书写系统与方言变体进行精细标注;最后,平衡不同语言的样本规模与性别分布,以消除数据偏差,构成了数据集构建中的核心挑战。
常用场景
经典使用场景
在语音识别与自然语言处理领域,多语言语音数据集FLEURS以其覆盖102种语言的广泛性,成为评估和训练自动语音识别系统的经典资源。该数据集通过提供高质量音频与对应转录文本,支持研究者构建跨语言语音识别模型,尤其在低资源语言场景下,其均衡的语料分布为模型泛化能力提供了坚实基础。
衍生相关工作
基于FLEURS数据集,学术界衍生了一系列经典研究工作,例如大规模多语言语音识别模型Whisper的评估与优化,以及跨语言语音合成系统的开发。这些工作不仅提升了模型在低资源语言上的性能,还推动了语音技术标准化评测框架的建立,为后续多模态语言研究奠定了重要基石。
数据集最近研究
最新研究方向
在语音识别与多语言处理领域,FLEURS数据集以其覆盖102种语言的广泛性,成为推动语言技术民主化的关键资源。近期研究聚焦于利用其丰富的语言多样性,探索跨语言语音表示学习与零样本迁移能力,尤其是在低资源语言场景下的应用。该数据集促进了多模态大语言模型在语音理解任务中的集成,响应了全球数字包容性倡议,为构建无语言障碍的智能交互系统提供了坚实的数据基础,对缩小语言技术鸿沟具有深远意义。
以上内容由遇见数据集搜集并总结生成


